






一、知识回顾
第三章学习了线性表里面的栈、队列,他们俩又可细分为顺序栈、链栈,顺序队列和链队。这样看,先入后出(FILO)的栈和先入先出的队列(FIFO)某种程度上是特殊的顺序表/链表,我认为这一章实际上是顺序表和链表那一章的回顾和提升。
针对他们的特性,来谈谈为什么栈是先入后出,队列是先入先出。
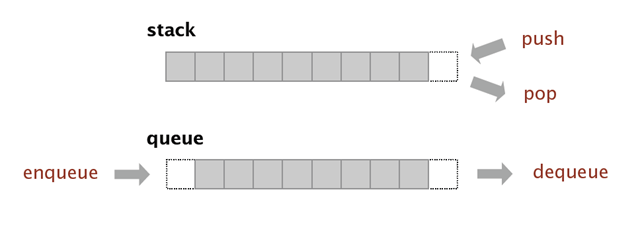
图片上可以直观的看出,栈是对一端进行操作,而队列是对头、尾两端进行操作。
顺序栈 ADT
typedef struct { SElemType data[MAXSIZE]; int top ; //作为栈顶标志 int stacksize ; //栈的最大容量 }
一些基本操作(顺序栈)
初始化
InitStack(SqStack &S) void InitStack(SqStack &S) { S.top = 0; S.stacksize = MAXSIZE; }
判断栈满
bool StackFull(SqStack &S) { if (S.top==S.stacksize) return true; else return false; }
判断栈空
bool StackFull(SqStack &S) { if (S.top==0) return true; else return false}
为什么要单独写一个判断栈满栈空的函数?有利于封装性
入栈
void Push(SqStack &S, SElemType e) {//元素e入栈,调用该函数前先判断是否栈满 S.data[S.top] = e; S.top++; }
出栈
void Pop(SqStack &S, SElemType &e) {//出栈赋给元素e,调用该函数前先判断是否栈空 S.top--; e = S.data[S.top]; }
链栈 ADT
typedef struct StackNode { SElemType data; struct StackNode *next; } StackNode, *LinkStack; LinkStack S;
基本操作(链栈)
初始化
void InitStack(LinkStack &S) { S = NULL; }
链栈由于不像顺序栈要考虑栈满的问题,所以一般不写判断链栈栈满的函数
判断栈空
bool StackEmpty(LinkStack S) { if (S==NULL) return true; else return false; }
入栈
Status Push(LinkStack &S, SElemType e) { p = new StackNode; //生成新结点p if (p==NULL) exit(OVERFLOW); p->data = e; p->next = S; S = p; return OK; }
出栈
void Pop(LinkStack &S, SElemType &e) {//在调用该函数前先调用StackEmpty(S)判断栈空 e = S-> data; p = S; S = S-> next; delete p; }
循环队列的顺序存储结构
ADT
const int MAXQSIZE = 100; //最大队列长度 typedef int QElemType; typedef struct { QElemType data[MAXQSIZE]; int front; //头指针 int rear; //尾指针 }SqQueue;
初始化
void InitQueue(SqQueue &Q) { Q.front = Q.rear = 0; }
判断队满
bool QueueFull(SqQueue Q) { if((Q.rear+1)%MAXQSIZE == Q.front) return true; else return false; }
判断队空
bool QueueEmpty(SqQueue Q) { if(Q.front==Q.rear) return true; else return false; }
入队
void EnQueue(SqQueue &Q, QElemType e) { Q.data[Q.rear] = e; Q.rear = (Q.rear+1) % MAXQSIZE; }
出队
void DeQueue(SqQueue &Q, QElemType &e) { e = Q.data[Q.front]; Q.front = (Q.front+1) % MAXQSIZE; }
链队 ADT
typedef struct QNode{ QElemType data; struct Qnode *next; }Qnode, *QueuePtr; typedef struct{ QueuePtr front; //队头指针 QueuePtr rear; //队尾指针 }LinkQueue;
初始化
Status InitQueue(LinkQueue &Q) { Q.front = new Qnode; if(Q.front==NULL) exit(OVERFLOW); Q.front->next = NULL; Q.rear = Q.front; return OK; }
队空
bool QueueEmpty(LinkQueue Q) { if(Q.front == Q.rear) return false;//队空 else return true; }
入队
Status EnQueue(LinkQueue &Q, QElemType e) { p = new QNode; if (p==NULL) exit( OVERFLOW ); p->data = e; p->next = NULL; Q.rear->next = p; Q.rear = p; return OK; }
出队
void DeQueue(LinkQueue &Q, QElemType &e) {//调用该函数前先判断队列是否为空 p = Q.front->next; e = p->data; Q.front->next = p->next; if(Q.rear == p) //最后一个结点出队 Q.rear = Q.front; delete p; //回收p指向的空间 }
二、遇到的问题
这一章我写了括号匹配和银行排队的程序,自己还写了一个顺序栈的基本操作(大杂烩)。总的来说觉得这一章学的比上一章轻松了一些,上一章学习的时候很不习惯书上这种处处ADT的方法,漏洞百出的程序摆在那很让人头大,但是这一章心里面大致有了个框架,首先要使所有的变量有一个合法的来源,自定义的抽象数据模型需要声明,每个部分的小函数要写好,其实主函数差不多可以说是各个小函数的拼接。
还有一些细节问题需要格外注意,比如说银行排队那题,为了满足题目要求的输出格式,我将出队的元素又放进一个数组里面,然后输出,但是没有在输入n值之后再定义数组,导致出错;写“大杂烩”的时候,程序老是在入栈之后就崩溃了,我检查了很久才发现其实问题出在入栈那个步骤时if语句判断我只打了一个等号。所以这提示我们第一遍一定要仔细再仔细,不然之后来找BUG,既耗时又耗精力。














 148
148











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









