






转自:http://blog.csdn.net/tutucute0000/article/details/39756123
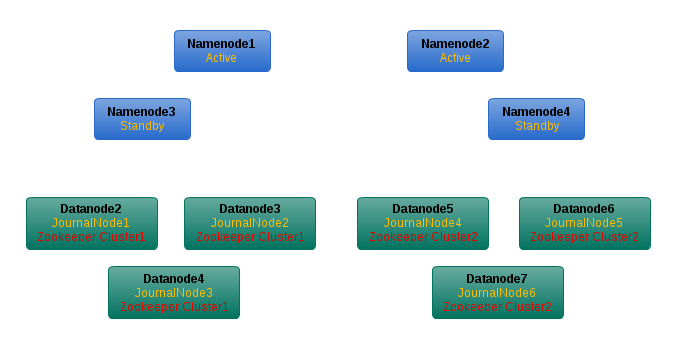
从nameNode1、namenode2克隆出namenode3、namenode4,分别作为1、2的standby node。
把datanode2、3、4作为namenode1的jounalnodes,datanode4、5、6作为namenode2的journalnodes。
同时将datanode2、3、4组成zookeeper cluster1,datanode5、6、7组成zookeeper cluster2,分别为namenode1、2管理的两个nameservice,提供namonode间的HA自动切换。
配置
1. 在datanode2、3、4、5、6、7上安装zookeeper
- wget http://mirrors.cnnic.cn/apache/zookeeper/zookeeper-3.4.6/zookeeper-3.4.6.tar.gz
- tar zxvf zookeeper-3.4.6.tar.gz
- mv zookeeper-3.4.6 zookeeper
- cd zookeeper/conf
- cp zoo_sample.cfg zoo.cfg
修改datanode2、3、4中的zoo.cfg文件为
- tickTime=2000
- initLimit=10
- syncLimit=5
- dataDir=/home/hduser/mydata/zookeeper/zkdata
- dataLogDir=/home/hduser/mydata/zookeeper/zkdatalog
- clientPort=2181
- server.1=datanode2:2888:3888
- server.2=datanode3:2888:3888
- server.3=datanode4:2888:3888
datanode5、6、7中的zoo.cfg为
- tickTime=2000
- initLimit=10
- syncLimit=5
- dataDir=/home/hduser/mydata/zookeeper/zkdata
- dataLogDir=/home/hduser/mydata/zookeeper/zkdatalog
- clientPort=2181
- server.1=datanode5:2888:3888
- server.2=datanode6:2888:3888
- server.3=datanode7:2888:3888
在每个节点上创建配置文件中所设的目录,同时在dataDir下新建myid文件
- mkdir -p /home/hduser/mydata/zookeeper/zkdata
- mkdir -p /home/hduser/mydata/zookeeper/zkdatalog
- vi /home/hduser/mydata/zookeeper/zkdata/myid
myid文件里就写一个数字,就是zoo.cfg文件里所配置的
server.X = datanodeN:2888:3888
中,节点N所对应的数字X。所以datanode2、5中myid文件内容就是数字1,datanode3、6是数字2,datanode4、7是数字3。
最后还要设置一下环境变量,添加一行到~/.bashrc
- export ZOOKEEPER_HOME=/usr/local/zookeeper
- export PATH=$ZOOKEEPER_HOME/bin:$PATH
2. 修改配置文件core-site.xml
基本的配置前面的文章都写了,这里只贴出需要修改和增加的配置项。
修改所有namenode和datanode的core-site.xml
- <property>
- <name>fs.defaultFS</name>
- <value>viewfs:///</value>
- </property>
- <property>
- <name>fs.viewfs.mounttable.default.link./ns1</name>
- <value>hdfs://ns1</value>
- </property>
- <property>
- <name>fs.viewfs.mounttable.default.link./ns2</name>
- <value>hdfs://ns2</value>
- </property>
其中ns1、ns2与下面hdfs-site.xml中配置的nameservices对应。
在datanode1、3的core-site.xml中添加
- <property>
- <name>ha.zookeeper.quorum</name>
- <value>datanode2:2181,datanode3:2181,datanode4:2181</value>
- </property>
在datanode2、4的core-site.xml中添加
- <property>
- <name>ha.zookeeper.quorum</name>
- <value>datanode5:2181,datanode6:2181,datanode7:2181</value>
- </property>
3.修改配置文件hdfs-site.xml
在所有节点(datanode1-3、namenode2-7)中的hdfs-site.xml中都添加以下配置
- <property>
- <name>dfs.nameservices</name>
- <value>ns1,ns2</value>
- </property>
- <property>
- <name>dfs.ha.namenodes.ns1</name>
- <value>nn1,nn3</value>
- </property>
- <property>
- <name>dfs.namenode.rpc-address.ns1.nn1</name>
- <value>namenode1:9000</value>
- </property>
- <property>
- <name>dfs.namenode.rpc-address.ns1.nn3</name>
- <value>namenode3:9000</value>
- </property>
- <property>
- <name>dfs.client.failover.proxy.provider.ns1</name>
- <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
- </property>
- <property>
- <name>dfs.ha.namenodes.ns2</name>
- <value>nn2,nn4</value>
- </property>
- <property>
- <name>dfs.namenode.rpc-address.ns2.nn2</name>
- <value>namenode2:9000</value>
- </property>
- <property>
- <name>dfs.namenode.rpc-address.ns2.nn4</name>
- <value>namenode4:9000</value>
- </property>
- <property>
- <name>dfs.client.failover.proxy.provider.ns2</name>
- <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
- </property>
- <property>
- <name>dfs.ha.fencing.methods</name>
- <value>sshfence</value>
- </property>
- <property>
- <name>dfs.ha.fencing.ssh.private-key-files</name>
- <value>/home/hduser/.ssh/id_rsa</value>
- </property>
- <property>
- <name>dfs.ha.fencing.ssh.connect-timeout</name>
- <value>30000</value>
- </property>
- <property>
- <name>dfs.ha.automatic-failover.enabled</name>
- <value>true</value>
- </property>
- <property>
- <name>dfs.journalnode.edits.dir</name>
- <value>/home/hduser/mydata/hdfs/journalnode</value>
- </property>
然后单独在namenode1、3的hdfs-site.xml中添加
- <property>
- <name>dfs.namenode.shared.edits.dir</name>
- <value>qjournal://datanode2:8485;datanode3:8485;datanode4:8485/ns1</value>
- </property>
在namenode2、4的hdfs-site.xml中添加
- <property>
- <name>dfs.namenode.shared.edits.dir</name>
- <value>qjournal://datanode5:8485;datanode6:8485;datanode7:8485/ns2</value>
- </property>
每个journalnode的上都要创建配置dfs.journalnode.edits.dir中所设的目录
- mkdir -p /home/hduser/mydata/hdfs/journalnode
值得注意的是dfs.ha.fencing.methods配置。
它是用来保证同一时刻只能有一个active namenode在工作。如果配置成sshfence,则代表在发生failover的时候,使用ssh登录到active namenode上,然后使用fuser干掉active namenode上的进程。所以在namenode间还需要有如下配置:
1. 配置dfs.ha.fencing.ssh.private-key-files指定私钥。或者直接就在所有节点之间配置好ssh免密码登录,以后在集群间跳转也方便。
2. 确保所有namenode上都能使用fuser命令。如果没有,使用下面的命令安装
- sudo apt-get install psmisc
启动集群
1. 启动zookeeper
在namenode2-7上运行
- hduser@datanode5:~$ zkServer.sh start
- JMX enabled by default
- Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
- Starting zookeeper ... STARTED
检查进程
- hduser@datanode5:~$ jps
- 16448 Jps
- 16425 QuorumPeerMain
2. 启动journalnodes
在namenode2-7上运行
- hduser@datanode5:~$ hadoop-daemon.sh start journalnode
- starting journalnode, logging to /usr/local/hadoop/logs/hadoop-hduser-journalnode-datanode5.out
检查进程
- hduser@datanode5:~$ jps
- 16472 JournalNode
- 16518 Jps
- 16425 QuorumPeerMain
3. 启动namenode
由于我是将之前搭建的非HA集群转换成HA集群,所以不需要重新format namenode,只需要做以下两步
首先使用namenode中的信息初始化journalnodes。
在namenode1、2里运行
- hdfs namenode -initializeSharedEdits
然后启动namenode1、2
- hadoop-daemon.sh --config $HADOOP_CONF_DIR --script hdfs start namenode
登录到namenode3、4,将namenode1、2中的元数据同步到它们各自对应的standby namenode上。
- hdfs namenode -bootstrapStandby
然后再启动namenode3、4。
由于刚启动时所有的namenode都是standby状态,所有namenode log里会有如下错误。
- 2014-10-03 19:39:47,971 INFO org.apache.hadoop.hdfs.server.namenode.ha.EditLogTailer: Triggering log roll on remote NameNode namenode4/192.168\
- .1.81:9000
- 2014-10-03 19:39:47,980 WARN org.apache.hadoop.hdfs.server.namenode.ha.EditLogTailer: Unable to trigger a roll of the active NN
- org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.ipc.StandbyException): Operation category JOURNAL is not supported in state standby
- at org.apache.hadoop.hdfs.server.namenode.ha.StandbyState.checkOperation(StandbyState.java:87)
- at org.apache.hadoop.hdfs.server.namenode.NameNode$NameNodeHAContext.checkOperation(NameNode.java:1688)
- at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.checkOperation(FSNamesystem.java:1258)
- at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.rollEditLog(FSNamesystem.java:5765)
- at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.rollEditLog(NameNodeRpcServer.java:886)
理论上这时候是可以用HAAdmin的命令手动将某一个namenode指定成active的状态的,可奇怪的是当配置了两个nameservices以后,该命令就识别不了namenode了
- hduser@namenode4:~$ hdfs haadmin -transitionToActive nn3
- Illegal argument: Unable to determine the nameservice id.
如果单独配置HA,即只有一个nameservice,就不会有这个问题,暂时不清楚为什么。
所以目前只能通过automatic failover的方式,让ZKFC自动管理namenode的状态。
在namenode1、2里运行
- hdfs zkfc -formatZK
然后在所有的namenode上运行
- hadoop-daemon.sh start zkfc
这时候再检查每个namenode上ZKFC的log,
namenode1上的ZKFC log最后一行显示
- Successfully transitioned NameNode at namenode1/192.168.1.71:9000 to active state
namenode2显示
- Successfully transitioned NameNode at namenode2/192.168.1.72:9000 to active state
namenode3显示
- Successfully transitioned NameNode at namenode3/192.168.1.80:9000 to standby state
namenode4显示
- Successfully transitioned NameNode at namenode4/192.168.1.81:9000 to standby state
至此所有的namenode启动成功了。
4. 启动datanode
到所有的datanode上运行
- hadoop-daemon.sh --config $HADOOP_CONF_DIR --script hdfs start datanode
集群启动完毕。
验证
访问http://namenode1:50070/dfsclusterhealth.jsp

看着四个namenode都很正常。
先试着把namenode1干掉
- hduser@namenode1:~$ jps
- 7590 Jps
- 7061 NameNode
- 17441 DFSZKFailoverController
- hduser@namenode1:~$ kill -9 7061
登到namenode3中看ZKFC的log
- 2014-10-03 21:00:55,943 INFO org.apache.hadoop.ha.NodeFencer: ====== Beginning Service Fencing Process... ======
- 2014-10-03 21:00:55,943 INFO org.apache.hadoop.ha.NodeFencer: Trying method 1/1: org.apache.hadoop.ha.SshFenceByTcpPort(null)
- 2014-10-03 21:00:55,944 INFO org.apache.hadoop.ha.SshFenceByTcpPort: Connecting to namenode1...
- 2014-10-03 21:00:55,944 INFO org.apache.hadoop.ha.SshFenceByTcpPort.jsch: Connecting to namenode1 port 22
- 2014-10-03 21:00:55,946 INFO org.apache.hadoop.ha.SshFenceByTcpPort.jsch: Connection established
- 2014-10-03 21:00:55,953 INFO org.apache.hadoop.ha.SshFenceByTcpPort.jsch: Remote version string: SSH-2.0-OpenSSH_5.9p1 Debian-5ubuntu1.1
- 2014-10-03 21:00:55,953 INFO org.apache.hadoop.ha.SshFenceByTcpPort.jsch: Local version string: SSH-2.0-JSCH-0.1.42
- 2014-10-03 21:00:55,953 INFO org.apache.hadoop.ha.SshFenceByTcpPort.jsch: CheckCiphers: aes256-ctr,aes192-ctr,aes128-ctr,aes256-cbc,aes192-cbc,\
- aes128-cbc,3des-ctr,arcfour,arcfour128,arcfour256
- 2014-10-03 21:00:55,958 INFO org.apache.hadoop.ha.SshFenceByTcpPort.jsch: aes256-ctr is not available.
- 2014-10-03 21:00:55,958 INFO org.apache.hadoop.ha.SshFenceByTcpPort.jsch: aes192-ctr is not available.
- 2014-10-03 21:00:55,958 INFO org.apache.hadoop.ha.SshFenceByTcpPort.jsch: aes256-cbc is not available.
- 2014-10-03 21:00:55,958 INFO org.apache.hadoop.ha.SshFenceByTcpPort.jsch: aes192-cbc is not available.
- 2014-10-03 21:00:55,958 INFO org.apache.hadoop.ha.SshFenceByTcpPort.jsch: arcfour256 is not available.
- 2014-10-03 21:00:55,958 INFO org.apache.hadoop.ha.SshFenceByTcpPort.jsch: SSH_MSG_KEXINIT sent
- 2014-10-03 21:00:55,958 INFO org.apache.hadoop.ha.SshFenceByTcpPort.jsch: SSH_MSG_KEXINIT received
- 2014-10-03 21:00:55,958 INFO org.apache.hadoop.ha.SshFenceByTcpPort.jsch: kex: server->client aes128-ctr hmac-md5 none
- 2014-10-03 21:00:55,958 INFO org.apache.hadoop.ha.SshFenceByTcpPort.jsch: kex: client->server aes128-ctr hmac-md5 none
- 2014-10-03 21:00:55,960 INFO org.apache.hadoop.ha.SshFenceByTcpPort.jsch: SSH_MSG_KEXDH_INIT sent
- 2014-10-03 21:00:55,960 INFO org.apache.hadoop.ha.SshFenceByTcpPort.jsch: expecting SSH_MSG_KEXDH_REPLY
- 2014-10-03 21:00:55,964 INFO org.apache.hadoop.ha.SshFenceByTcpPort.jsch: ssh_rsa_verify: signature true
- 2014-10-03 21:00:55,965 WARN org.apache.hadoop.ha.SshFenceByTcpPort.jsch: Permanently added 'namenode1' (RSA) to the list of known hosts.
- 2014-10-03 21:00:55,965 INFO org.apache.hadoop.ha.SshFenceByTcpPort.jsch: SSH_MSG_NEWKEYS sent
- 2014-10-03 21:00:55,965 INFO org.apache.hadoop.ha.SshFenceByTcpPort.jsch: SSH_MSG_NEWKEYS received
- 2014-10-03 21:00:55,966 INFO org.apache.hadoop.ha.SshFenceByTcpPort.jsch: SSH_MSG_SERVICE_REQUEST sent
- 2014-10-03 21:00:55,966 INFO org.apache.hadoop.ha.SshFenceByTcpPort.jsch: SSH_MSG_SERVICE_ACCEPT received
- 2014-10-03 21:00:55,968 INFO org.apache.hadoop.ha.SshFenceByTcpPort.jsch: Authentications that can continue: publickey,keyboard-interactive,pas\
- sword
- 2014-10-03 21:00:55,968 INFO org.apache.hadoop.ha.SshFenceByTcpPort.jsch: Next authentication method: publickey
- 2014-10-03 21:00:55,996 INFO org.apache.hadoop.ha.SshFenceByTcpPort.jsch: Authentication succeeded (publickey).
- 2014-10-03 21:00:55,996 INFO org.apache.hadoop.ha.SshFenceByTcpPort: Connected to namenode1
- 2014-10-03 21:00:55,996 INFO org.apache.hadoop.ha.SshFenceByTcpPort: Looking for process running on port 9000
- 2014-10-03 21:00:56,062 INFO org.apache.hadoop.ha.SshFenceByTcpPort: Indeterminate response from trying to kill service. Verifying whether it i\
- s running using nc...
- 2014-10-03 21:00:56,118 INFO org.apache.hadoop.ha.SshFenceByTcpPort: Verified that the service is down.
- 2014-10-03 21:00:56,118 INFO org.apache.hadoop.ha.SshFenceByTcpPort.jsch: Disconnecting from namenode1 port 22
- 2014-10-03 21:00:56,118 INFO org.apache.hadoop.ha.NodeFencer: ====== Fencing successful by method org.apache.hadoop.ha.SshFenceByTcpPort(null) \
- ======
- 2014-10-03 21:00:56,118 INFO org.apache.hadoop.ha.ActiveStandbyElector: Writing znode /hadoop-ha/ns1/ActiveBreadCrumb to indicate that the loca\
- l node is the most recent active...
- 2014-10-03 21:00:56,119 INFO org.apache.hadoop.ha.SshFenceByTcpPort.jsch: Caught an exception, leaving main loop due to Socket closed
- 2014-10-03 21:00:56,183 INFO org.apache.hadoop.ha.ZKFailoverController: Trying to make NameNode at namenode3/192.168.1.80:9000 active...
- 2014-10-03 21:00:57,323 INFO org.apache.hadoop.ha.ZKFailoverController: Successfully transitioned NameNode at namenode3/192.168.1.80:9000 to ac\
- tive state
看到namenode3成功变成了active的状态。
最后再试一下在拷贝文件的过程中干掉一个active的namenode会不会有问题。
准备一个2G多的大文件,拷贝到hdfs里
- hduser@datanode5:~$ hdfs dfs -cp file:///home/hduser/test.tar.gz /ns2/test2/
- 14/10/04 00:33:56 INFO retry.RetryInvocationHandler: Exception while invoking renewLease of class ClientNamenodeProtocolTranslatorPB over namenode4/192.168.1.81:9000. Trying to fail over immediately.
- java.net.ConnectException: Call From datanode5/192.168.1.77 to namenode4:9000 failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
- at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
- at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:57)
- ...
拷贝了一会儿active namenode居然自己挂了。。。还好还有一个
控制台输出显示成功切换了namenode过去,继续上传文件。
- 14/10/04 00:42:54 WARN retry.RetryInvocationHandler: A failover has occurred since the start of this method invocation attempt.
- 14/10/04 00:43:49 WARN hdfs.DFSClient: Slow ReadProcessor read fields took 56210ms (threshold=30000ms); ack: seqno: 25725 status: SUCCESS status: SUCCESS status: SUCCESS downstreamAckTimeNanos: 56224427288, targets: [192.168.1.77:50010, 192.168.1.74:50010, 192.168.1.79:50010]
- ...
不一会儿功夫这个namenode也挂了。看了log,挂的原因都是一个
- 2014-10-04 00:37:12,798 INFO org.apache.hadoop.hdfs.qjournal.client.QuorumJournalManager: Waited 6001 ms (timeout=20000 ms) for a response for\
- sendEdits. Succeeded so far: [192.168.1.79:8485]
- 2014-10-04 00:37:13,799 INFO org.apache.hadoop.hdfs.qjournal.client.QuorumJournalManager: Waited 7002 ms (timeout=20000 ms) for a response for\
- sendEdits. Succeeded so far: [192.168.1.79:8485]
- 2014-10-04 00:37:14,799 INFO org.apache.hadoop.hdfs.qjournal.client.QuorumJournalManager: Waited 8003 ms (timeout=20000 ms) for a response for\
- sendEdits. Succeeded so far: [192.168.1.79:8485]
- 2014-10-04 00:37:15,801 INFO org.apache.hadoop.hdfs.qjournal.client.QuorumJournalManager: Waited 9004 ms (timeout=20000 ms) for a response for\
- sendEdits. Succeeded so far: [192.168.1.79:8485]
- 2014-10-04 00:37:16,802 INFO org.apache.hadoop.hdfs.qjournal.client.QuorumJournalManager: Waited 10005 ms (timeout=20000 ms) for a response fo\
- r sendEdits. Succeeded so far: [192.168.1.79:8485]
- 2014-10-04 00:37:17,803 INFO org.apache.hadoop.hdfs.qjournal.client.QuorumJournalManager: Waited 11006 ms (timeout=20000 ms) for a response fo\
- r sendEdits. Succeeded so far: [192.168.1.79:8485]
- 2014-10-04 00:37:18,804 INFO org.apache.hadoop.hdfs.qjournal.client.QuorumJournalManager: Waited 12007 ms (timeout=20000 ms) for a response fo\
- r sendEdits. Succeeded so far: [192.168.1.79:8485]
- 2014-10-04 00:37:19,804 INFO org.apache.hadoop.hdfs.qjournal.client.QuorumJournalManager: Waited 13008 ms (timeout=20000 ms) for a response fo\
- r sendEdits. Succeeded so far: [192.168.1.79:8485]
- 2014-10-04 00:37:20,806 WARN org.apache.hadoop.hdfs.qjournal.client.QuorumJournalManager: Waited 14009 ms (timeout=20000 ms) for a response fo\
- r sendEdits. Succeeded so far: [192.168.1.79:8485]
- 2014-10-04 00:37:21,806 WARN org.apache.hadoop.hdfs.qjournal.client.QuorumJournalManager: Waited 15010 ms (timeout=20000 ms) for a response fo\
- r sendEdits. Succeeded so far: [192.168.1.79:8485]
- 2014-10-04 00:37:22,808 WARN org.apache.hadoop.hdfs.qjournal.client.QuorumJournalManager: Waited 16011 ms (timeout=20000 ms) for a response fo\
- r sendEdits. Succeeded so far: [192.168.1.79:8485]
- 2014-10-04 00:37:23,808 WARN org.apache.hadoop.hdfs.qjournal.client.QuorumJournalManager: Waited 17012 ms (timeout=20000 ms) for a response fo\
- r sendEdits. Succeeded so far: [192.168.1.79:8485]
- 2014-10-04 00:37:23,864 INFO org.apache.hadoop.hdfs.server.blockmanagement.CacheReplicationMonitor: Rescanning after 30000 milliseconds
- 2014-10-04 00:37:23,864 INFO org.apache.hadoop.hdfs.server.blockmanagement.CacheReplicationMonitor: Scanned 0 directive(s) and 0 block(s) in 1\
- millisecond(s).
- 2014-10-04 00:37:24,810 WARN org.apache.hadoop.hdfs.qjournal.client.QuorumJournalManager: Waited 18013 ms (timeout=20000 ms) for a response fo\
- r sendEdits. Succeeded so far: [192.168.1.79:8485]
- 2014-10-04 00:37:25,811 WARN org.apache.hadoop.hdfs.qjournal.client.QuorumJournalManager: Waited 19014 ms (timeout=20000 ms) for a response fo\
- r sendEdits. Succeeded so far: [192.168.1.79:8485]
- 2014-10-04 00:37:26,798 FATAL org.apache.hadoop.hdfs.server.namenode.FSEditLog: Error: flush failed for required journal (JournalAndStream(mgr\
- =QJM to [192.168.1.77:8485, 192.168.1.78:8485, 192.168.1.79:8485], stream=QuorumOutputStream starting at txid 506))
- java.io.IOException: Timed out waiting 20000ms for a quorum of nodes to respond.
- at org.apache.hadoop.hdfs.qjournal.client.AsyncLoggerSet.waitForWriteQuorum(AsyncLoggerSet.java:137)
- at org.apache.hadoop.hdfs.qjournal.client.QuorumOutputStream.flushAndSync(QuorumOutputStream.java:107)
- at org.apache.hadoop.hdfs.server.namenode.EditLogOutputStream.flush(EditLogOutputStream.java:113)
- at org.apache.hadoop.hdfs.server.namenode.EditLogOutputStream.flush(EditLogOutputStream.java:107)
- at org.apache.hadoop.hdfs.server.namenode.JournalSet$JournalSetOutputStream$8.apply(JournalSet.java:499)
- at org.apache.hadoop.hdfs.server.namenode.JournalSet.mapJournalsAndReportErrors(JournalSet.java:359)
- at org.apache.hadoop.hdfs.server.namenode.JournalSet.access$100(JournalSet.java:57)
- at org.apache.hadoop.hdfs.server.namenode.JournalSet$JournalSetOutputStream.flush(JournalSet.java:495)
- at org.apache.hadoop.hdfs.server.namenode.FSEditLog.logSync(FSEditLog.java:625)
- at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getAdditionalBlock(FSNamesystem.java:2839)
- at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.addBlock(NameNodeRpcServer.java:606)
- at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.addBlock(ClientNamenodeProtocolServerSideTranslatorP\
- B.java:455)
- at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtoc\
- olProtos.java)
- at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:585)
- at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:928)
- at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2013)
- at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2009)
- at java.security.AccessController.doPrivileged(Native Method)
- at javax.security.auth.Subject.doAs(Subject.java:415)
- at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1614)
- at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2007)
- 2014-10-04 00:37:26,798 WARN org.apache.hadoop.hdfs.qjournal.client.QuorumJournalManager: Aborting QuorumOutputStream starting at txid 506
- 2014-10-04 00:37:26,799 INFO org.apache.hadoop.util.ExitUtil: Exiting with status 1
- 2014-10-04 00:37:26,801 INFO org.apache.hadoop.hdfs.server.namenode.NameNode: SHUTDOWN_MSG:
- /************************************************************
- SHUTDOWN_MSG: Shutting down NameNode at namenode2/192.168.1.72
连接192.168.1.79超时了,这边的网络确实是不太好。不过这也说明了采用QJM方式的HA集群对Journal Node依赖太大了,需要注意。
试图重新启动两个namenode,发现ZKFC也挂了,日志报错如下
- 2014-10-04 00:38:15,708 INFO org.apache.zookeeper.ClientCnxn: Opening socket connection to server datanode5/192.168.1.77:2181. Will not attemp\
- t to authenticate using SASL (unknown error)
- 2014-10-04 00:38:15,717 INFO org.apache.zookeeper.ClientCnxn: Socket connection established to datanode5/192.168.1.77:2181, initiating session
- 2014-10-04 00:38:17,386 INFO org.apache.zookeeper.ClientCnxn: Client session timed out, have not heard from server in 1669ms for sessionid 0x0\
- , closing socket connection and attempting reconnect
- 2014-10-04 00:38:18,288 INFO org.apache.zookeeper.ClientCnxn: Opening socket connection to server datanode6/192.168.1.78:2181. Will not attemp\
- t to authenticate using SASL (unknown error)
- 2014-10-04 00:38:18,289 INFO org.apache.zookeeper.ClientCnxn: Socket connection established to datanode6/192.168.1.78:2181, initiating session
- 2014-10-04 00:38:19,957 INFO org.apache.zookeeper.ClientCnxn: Client session timed out, have not heard from server in 1668ms for sessionid 0x0\
- , closing socket connection and attempting reconnect
- 2014-10-04 00:38:20,585 INFO org.apache.zookeeper.ClientCnxn: Opening socket connection to server datanode7/192.168.1.79:2181. Will not attemp\
- t to authenticate using SASL (unknown error)
- 2014-10-04 00:38:20,586 INFO org.apache.zookeeper.ClientCnxn: Socket connection established to datanode7/192.168.1.79:2181, initiating session
- 2014-10-04 00:38:20,587 INFO org.apache.zookeeper.ClientCnxn: Unable to read additional data from server sessionid 0x0, likely server has clos\
- ed socket, closing socket connection and attempting reconnect
- 2014-10-04 00:38:20,710 ERROR org.apache.hadoop.ha.ActiveStandbyElector: Connection timed out: couldn't connect to ZooKeeper in 5000 milliseco\
- nds
- 2014-10-04 00:38:21,750 INFO org.apache.zookeeper.ZooKeeper: Session: 0x0 closed
- 2014-10-04 00:38:21,753 INFO org.apache.zookeeper.ClientCnxn: EventThread shut down
- 2014-10-04 00:38:21,756 FATAL org.apache.hadoop.ha.ZKFailoverController: Unable to start failover controller. Unable to connect to ZooKeeper q\
- uorum at datanode5:2181,datanode6:2181,datanode7:2181. Please check the configured value for ha.zookeeper.quorum and ensure that ZooKeeper is \
- running.
试着telnet一下,端口没挂,但是连接速度慢也有卡死现象,看来还是网络问题。这又说明了采用ZKFC方式做automatic failover对zookeeper的依赖。
重新启动zkfc和namenode,磕磕跘跘的终于拷完了,临了还出了个小问题
- 14/10/04 00:46:30 WARN hdfs.DFSClient: DFSOutputStream ResponseProcessor exception for block BP-1850652326-192.168.1.72-1411567722328:blk_1073741916_1098
- java.net.SocketTimeoutException: 75000 millis timeout while waiting for channel to be ready for read. ch : java.nio.channels.SocketChannel[connected local=/192.168.1.77:38739 remote=/192.168.1.77:50010]
- at org.apache.hadoop.net.SocketIOWithTimeout.doIO(SocketIOWithTimeout.java:164)
- at org.apache.hadoop.net.SocketInputStream.read(SocketInputStream.java:161)
- at org.apache.hadoop.net.SocketInputStream.read(SocketInputStream.java:131)
- at org.apache.hadoop.net.SocketInputStream.read(SocketInputStream.java:118)
- at java.io.FilterInputStream.read(FilterInputStream.java:83)
- at java.io.FilterInputStream.read(FilterInputStream.java:83)
- at org.apache.hadoop.hdfs.protocolPB.PBHelper.vintPrefixed(PBHelper.java:1998)
- at org.apache.hadoop.hdfs.protocol.datatransfer.PipelineAck.readFields(PipelineAck.java:176)
- at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer$ResponseProcessor.run(DFSOutputStream.java:798)
- 14/10/04 00:46:30 WARN hdfs.DFSClient: Error Recovery for block BP-1850652326-192.168.1.72-1411567722328:blk_1073741916_1098 in pipeline 192.168.1.77:50010, 192.168.1.74:50010, 192.168.1.76:50010: bad datanode 192.168.1.77:50010
- 14/10/04 00:46:33 WARN hdfs.DFSClient: Slow waitForAckedSeqno took 78393ms (threshold=30000ms)
- hduser@datanode5:~$
- hduser@datanode5:~$ hdfs dfs -ls /ns2/test2/
- Found 1 items
- -rw-r--r-- 3 hduser supergroup 2001616896 2014-10-04 00:43 /ns2/test2/test.tar.gz
把文件再从hdfs上拉下来,使用md5校验是否与原文件一致
- // 目标路径
- hdfs dfs -get /ns2/test2/test.tar.gz
- // 原始文件路径
- md5sum test.tar.gz > test.tar.gz.md5
- // 拷贝test.tar.gz.md5到目标路径
- md5sum -c test.tar.gz.md5
- test.tar.gz: OK
看来虽然上传的不太顺利,但是结果还是好的。
一些关于HA+Federation的意义和相关组件的介绍,可以参见以下文章
http://www.infoq.com/cn/articles/Hadoop-2-0-namenode-ha-federation-practice-zh/














 481
481











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









