






拨开字符编码迷雾系列文章链接:
1. Windows API介绍
本文介绍使用Windows API进行字符编码的转换,涉及WideCharToMultiByte和MultiByteToWideChar2个API,
API接口名中的MultiByte对应着多字节编码,如ASCII、UTF-8等都是多字节编码,而WideChar字面意思是宽字符,在windows内部宽字符特指UTF-16编码。 原型如下:
int WideCharToMultiByte(
UINT CodePage,
DWORD dwFlags,
LPCWSTR lpWideCharStr,
int cchWideChar,
LPSTR lpMultiByteStr,
int cbMultiByte,
LPCSTR lpDefaultChar,
LPBOOL lpUsedDefaultChar
);
int MultiByteToWideChar(
UINT CodePage,
DWORD dwFlags,
LPCSTR lpMultiByteStr,
int cbMultiByte,
LPWSTR lpWideCharStr,
int cchWideChar
);
2. 接口封装
std::string UnicodeToANSI(const std::wstring &str, UINT iCodePage = CP_ACP) {
std::string strRes;
int iSize = ::WideCharToMultiByte(iCodePage, 0, str.c_str(), -1, NULL, 0, NULL, NULL);
if (iSize == 0)
return strRes;
char *szBuf = new (std::nothrow) char[iSize];
if (!szBuf)
return strRes;
memset(szBuf, 0, iSize);
::WideCharToMultiByte(iCodePage, 0, str.c_str(), -1, szBuf, iSize, NULL, NULL);
strRes = szBuf;
delete[] szBuf;
return strRes;
}
std::wstring ANSIToUnicode(const std::string &str, UINT iCodePage = CP_ACP) {
std::wstring strRes;
int iSize = ::MultiByteToWideChar(iCodePage, 0, str.c_str(), -1, NULL, 0);
if (iSize == 0)
return strRes;
wchar_t *szBuf = new (std::nothrow) wchar_t[iSize];
if (!szBuf)
return strRes;
memset(szBuf, 0, iSize * sizeof(wchar_t));
::MultiByteToWideChar(iCodePage, 0, str.c_str(), -1, szBuf, iSize);
strRes = szBuf;
delete[] szBuf;
return strRes;
}
std::string UnicodeToUTF8(const std::wstring &str) {
std::string strRes;
int iSize = ::WideCharToMultiByte(CP_UTF8, 0, str.c_str(), -1, NULL, 0, NULL, NULL);
if (iSize == 0)
return strRes;
char *szBuf = new (std::nothrow) char[iSize];
if (!szBuf)
return strRes;
memset(szBuf, 0, iSize);
::WideCharToMultiByte(CP_UTF8, 0, str.c_str(), -1, szBuf, iSize, NULL, NULL);
strRes = szBuf;
delete[] szBuf;
return strRes;
}
std::string UnicodeToUTF8BOM(const std::wstring &str) {
std::string strRes;
int iSize = ::WideCharToMultiByte(CP_UTF8, 0, str.c_str(), -1, NULL, 0, NULL, NULL);
if (iSize == 0)
return strRes;
unsigned char *szBuf = new (std::nothrow) unsigned char[iSize + 3];
if (!szBuf)
return strRes;
memset(szBuf, 0, iSize + 3);
if (::WideCharToMultiByte(CP_UTF8, 0, str.c_str(), -1, (LPSTR)(szBuf + 3), iSize, NULL, NULL) > 0) {
szBuf[0] = 0xEF;
szBuf[1] = 0xBB;
szBuf[2] = 0xBF;
}
strRes = (char*)szBuf;
delete[] szBuf;
return strRes;
}
std::wstring UTF8ToUnicode(const std::string &str) {
std::wstring strRes;
int iSize = ::MultiByteToWideChar(CP_UTF8, 0, str.c_str(), -1, NULL, 0);
if (iSize == 0)
return strRes;
wchar_t *szBuf = new (std::nothrow) wchar_t[iSize];
if (!szBuf)
return strRes;
memset(szBuf, 0, iSize * sizeof(wchar_t));
::MultiByteToWideChar(CP_UTF8, 0, str.c_str(), -1, szBuf, iSize);
strRes = szBuf;
delete[] szBuf;
return strRes;
}
std::string ANSIToUTF8(const std::string &str, UINT iCodePage = CP_ACP) {
return UnicodeToUTF8(ANSIToUnicode(str, iCodePage));
}
std::string ANSIToUTF8BOM(const std::string &str, UINT iCodePage = CP_ACP) {
return UnicodeToUTF8BOM(ANSIToUnicode(str, iCodePage));
}
std::string UTF8ToANSI(const std::string &str, UINT iCodePage = CP_ACP) {
return UnicodeToANSI(UTF8ToUnicode(str), iCodePage);
}
对于只支持简体中文(部分韩文、日文)的系统,iCodePage可以使用CP_ACP,这时API会使用系统当前的代码页(简体中文系统为CP936,即GBK字符集)来进行编码转换。 但遇到如下情况就需要手动指定代码页了:
- 需要转换的字符串中的文字是系统当前代码页不支持的。如字符串中含有中文,而当前系统代码页确是英文的;
- GBK字符集中只包含了一部分韩文和日文,部分韩文和日文的转换可以正常转换,若遇到不能转换的情况也需要将指定iCodePage为特定的支持韩文或日文的代码页了,特别是中文和韩文、日文等混合的情况下。如韩文“탉”不包含在GBK中,若这时仍然使用CP_ACP就会得到错误的转换结果
?,十六进制3F。但GB18030(代码页为54936)支持“탉”,可以手动指定iCodePage为54936。
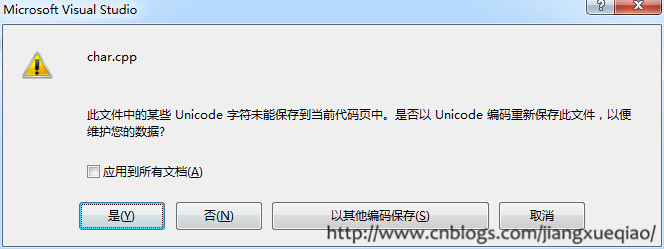
如果代码中含有GBK不支持的字符,如“탉”、“?”等,Visual Studio会弹出如下提示:
选择“以其他编码保存”,选择“Unicode(UTF-8带签名)- 代码页65001”保存。
虽然“简体中文(GB18030) - 代码页54936”也支持这些字符,但不能选择该选项进行保存,具体原因在拨开字符编码的迷雾--编译器如何处理文件编码 中有详细的介绍。














 769
769











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









