






一. 理解并能快速、准确写出代码。(★★★★★)
1. 几种常见排序( 代码 )
基于比较的排序算法: 下界是 nlgn
1.1 SelectionSort:每次选出最下的元素,放在当前循环最左边的位置。
1.2 BubbleSort:每次比较相邻的两个数,使得最大的数像气泡一样冒到最右边。
1. 3 InsertionSort:每次拿起一个数,插入到它左边数组的正确位置。
1.4 QuickSort:选择一个数,作为标准,小于它的放在左边,大于它的放在右边。并把它放在中间;递归地对左右子数组进行排序。
实现时:
1. 确定递归结束条件,初始化左右游标, 选择标准数;
2. while循环,do while实现两个游标同时向中间移动,置换;
3. 置换标准数和右边游标所指的数;
4. 递归调用,对左右子数组进行排序。
1. 5 HeapSort:用最大堆实现。
实现时:建堆:置换堆顶元素和最后一个元素,堆大小减少,保持新的堆为最大堆;
保持最大堆: 从底向上依次保持最大堆,从第一个父节点到根部。
1.6 MergeSort:拆分数组,递归实现排序,二路归并。用哨兵来阻止游标的越界。
线性时间运行的算法:
1.7 CountingSort: 假设数据分布在0到k之间的。对于每个输入x,确定出小于x的数的个数。假设小于x的数有17个,那么x就应该在第18个输出位置。
1. 8 Radix sort(基数排序):从最低位开始,每位采用稳定的排序算法(如计数排序)。
1.9 Bucket sort:当输入数据比较均匀时采用。
先将数据区间分为n个桶,把数据分放到对应的桶中;对桶内的数据采用插入排序;再把各个桶的排序结果串起来。
2. 二分查找( 代码 )
有序数组的查找,注意数组中可能有相同的数。
3. 单链表( 代码 )
单链表的基本操作:建立,查找,插入,删除等。
4. 二叉树( 代码 )
二叉树的建立、遍历(前序、后序、中序、逐层)、销毁、高度计算等。
5. 图( 代码 )
5.1 表示:邻接表、邻接矩阵;
5.2 遍历:深度优先搜索、广度优先搜索;
5.3 最小生成树:
Kruskal算法:每次取当前最小权值的边,如果这条边连接的两个节点不在同一个连通分量中,则添加到最小生成树中,直到所有顶点被覆盖。
Prim算法:从任意根顶点开始,每次取到树中任意一个顶点权值最小的边,加入到树中,直到所有顶点被覆盖。
5.4 有向图单源最短路径:
Dijkstra算法(要求所有权值非负):算法给定一个源点,每次从剩余顶点中选择具有最短路径估计的顶点u,将其加入集合S,并对u的所有出边进行松弛。
二. 理解。(★★★★)
1. 栈和队列:队列中当 head[Q] = tail[Q]+1时,表示队列是满的。
2. 双向链表:
![]()
为了使删除、插入的代码好写,提出了哨兵:

3. 散列表:具有关键字k的元素放在槽h(k)中, 用链接法解决碰撞,如下图:

三个小知识点:
装载因子:元素个数n/槽位数m
散列函数:除法: h(k) = k mod m. m通常是与2的整数幂不太接近的质数。
开放寻址:连续查找散列表的各项,直到找到一个空槽为止。删除操作比较困难。
4. 二叉查找树:
4.1 性质:父节点的关键字大于其左节点的,小于其右节点的。
4.2遍历;插入和删除;查找:查找某个关键字、最大、最小元素、前驱和后继。寻找后继的算法:
如果节点x的右子树非空,那么其有子树的最左节点即是;
如果节点x的右子树为空,且x有后继,那么其后继是它的最低祖先y,并且要满足y的左儿子也是x的祖先。
5. 红黑树
5.1 定义:一种二叉查找树,在节点上增加一个存储位表示节点颜色。红黑树通过对从根到叶子的路径中各个节点着色方式的限制,确保没有一条路径会比其他路径长出两倍。因而是接近平衡的。
5.2 5条性质:
1)每个节点是红色或黑色;
2)根节点是黑色;
3)每个叶节点(NIL)是黑色;
4)如果一个节点是红色,则它的两个儿子都是黑的;
5)对每个节点,从该节点到其子孙节点的所有路径上包含相同数目的黑节点
5.3 实例:

5.4 应用:
在C++ STL中,很多部分(目前包括set, multiset, map, multimap)应用了红黑树的变体(SGI STL中的红黑树有一些变化,这些修改提供了更好的性能,以及对set操作的支持)。它是复杂的,但它的操作有着良好的最坏情况运行时间,并且在实践中是高效的: 它可以在O(log n)时间内做查找,插入和删除等操作。
5.5 AVL树:高度平衡的二叉查找树,对每个节点x,它的左子树和右子树的高度至多差1.
5.6 Treep:节点排列时,让关键字遵循二叉查找树的性质,并且优先级遵循最小堆的性质。

根的关键字是G,优先级是4.
6. B树:B树的节点可以有很多子女。
6.1 典型特征:
(a)每个节点的关键字按照非降序排列;
(b)父节点的关键字,介于子节点关键字之间(即可以把各个孩子分开)。如下图所示:

6.2应用:B树索引是数据库中存取和查找文件(称为记录或键值)的一种方法。B-tree算法减少定位记录时所经历的中间过程,从而加快存取速度。
6.3 B+树:所有的附属数据都保存在叶子节点,只将关键字和子女的指针保存在内节点。如下图所示:

链表的分类
单链表
单链表是一种链式存取的结构,为找第 i 个数据元素,必须先找到第 i-1 个数据元素。图中阴影区域表示数据域,空白区表示指针域。而且最后一个指针域为空。
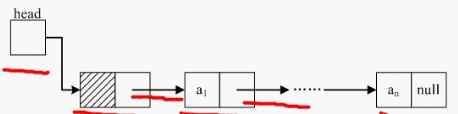
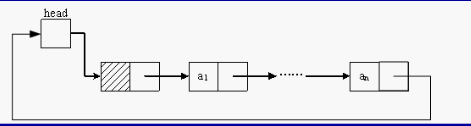
循环链表
循环链表是另一种形式的链式存贮结构。它的特点是表中最后一个结点的指针域指向头结点,整个链表形成一个环。循环链表又分为单循环链表和多重链的循环链表。
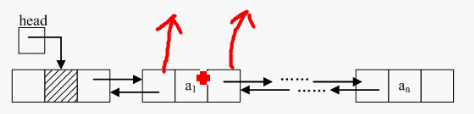
双链表
双链表也称为双向链表,是链表的一种,它的每个数据结点中都有两个指针,分别指向直接后继和直接前驱。所以,从双向链表中的任意一个结点开始,都可以很方便地访问它的前驱结点和后继结点。双链表的灵活度要比单链表好一些,但开支要大一些(存在两个指针)。
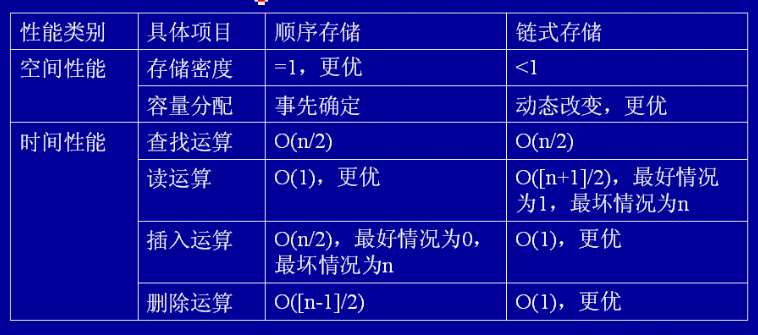
顺序表与链表的比较
顺序表存储位置是相邻连续的,可以随即访问的一种数据结构,一个顺序表在使用前必须指定起长度,一旦分配内存,则在使用中不可以动态的更改。他的优点是访问数据是比较方便,可以随即的访问表中的任何一个数据。
链表是通过指针来描述元素关系的一种数据结构,他可以是物理地址不连续的物理空间。不能随即访问链表元素,必须从表头开始,一步一步搜索元素。它的优点是:对于数组,可以动态的改变数据的长度,分配物理空间。
在使用中:如果一个数组在使用中,查询比较多,而插入,删除数据比较少,数组的长度不变时,选顺序表比较合理。如果插入,删除,长度不定的数组,可以选链表。
树(Tree)
树是包含n(n>0)个结点的有穷集合K,且在K中定义了一个关系N,N满足 以下条件:
(1)有且仅有一个结点 K0,他对于关系N来说没有前驱,称K0为树的根结点。简称为根(root)。
(2)除K0外,K中的每个结点,对于关系N来说有且仅有一个前驱。
(3)K中各结点,对关系N来说可以有m个后继(m>=0)。
树具有以下特点:
(1) 每个节点有零个或多个子节点。
(2) 每个子节点只有一个父节点。
(3) 没有父节点的节点称为根节点。
关于树的一些术语
节点的度:一个节点含有的子树的个数称为该节点的度;
叶节点或终端节点:度为零的节点称为叶节点;
非终端节点或分支节点:度不为零的节点;
双亲节点或父节点:若一个结点含有子节点,则这个节点称为其子节点的父节点;
孩子节点或子节点:一个节点含有的子树的根节点称为该节点的子节点;
兄弟节点:具有相同父节点的节点互称为兄弟节点;
树的高度或深度:定义一棵树的根结点层次为1,其他节点的层次是其父结点层次加1。一棵树中所有结点的层次的最大值称为这棵树的深度。节点的层次:从根开始定义起,根为第1层,根的子结点为第2层,以此类推;
树的度:一棵树中,最大的节点的度称为树的度;
节点的祖先:从根到该节点所经分支上的所有节点;
子孙:以某节点为根的子树中任一节点都称为该节点的子孙。
森林:由m(m>=0)棵互不相交的树的集合称为森林;
树的遍历
树的遍历分为:前序遍历、后序遍历、层次遍历。前序遍历的遍历顺序是先访问根结点,再访问叶子结点;后序遍历的遍历顺序是先访问叶子结点,再访问根结点;而层次遍历则是按层次进行遍历。
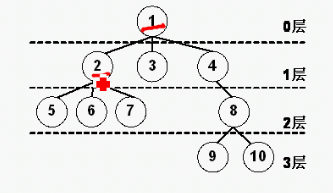

二叉树
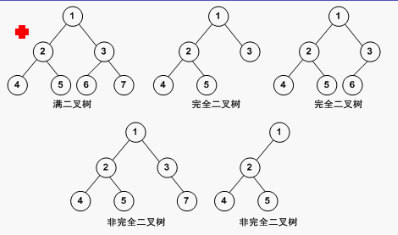
二叉树是每个节点最多有两个子树的有序树。通常子树被称作“左子树”(left subtree)和“右子树”(right subtree)。二叉树又分为满二叉树、完全二叉树、非完全二叉树等。
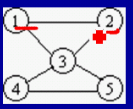
图(Graph)
图是由结点的有穷集合V和边的集合E组成。其中,为了与树形结构加以区别,在图结构中常常将结点称为顶点,边是顶点的有序偶对,若两个顶点之间存在一条边,就表示这两个顶点具有相邻关系。其中,图分为无向图和有向图。
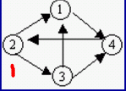
图的遍历
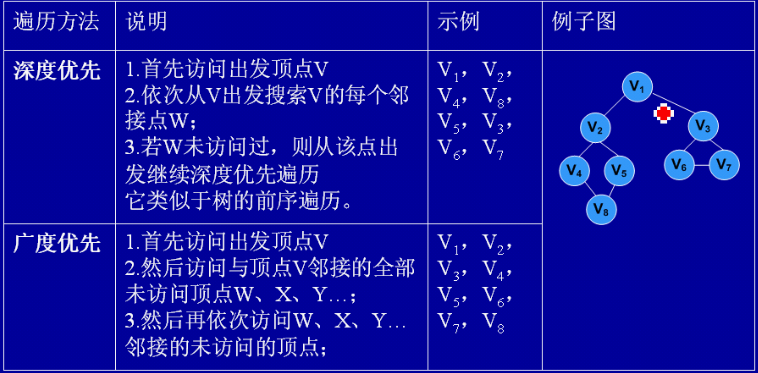
图的遍历分为深度优先遍历和广度优先遍历。深度优先遍历的思想类似于树的先序遍历。其遍历过程可以描述为:从图中某个顶点v出发,访问该顶点,然后依次从v的未被访问的邻接点出发继续深度优先遍历图中的其余顶点,直至图中所有与v有路径相通的顶点都被访问完为止。
广度优先遍历方法描述为:从图中某个顶点v出发,在访问该顶点v之后,依次访问v的所有未被访问过的邻接点,然后再访问每个邻接点的邻接点,且访问顺序应保持先被访问的顶点其邻接点也优先被访问,直到图中的所有顶点都被访问为止。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









