



零成本抽象(Zero-Cost Abstraction)是现代编程语言设计的重要原则之一,它意味着高级抽象不会带来运行时性能开销。仓颉语言作为华为开发的新一代编程语言,在设计之初就将零成本抽象作为核心理念之一。本文将深入探讨仓颉如何实现这一目标,并通过实践案例展示其技术优势。

零成本抽象的核心思想
零成本抽象的本质在于:使用抽象不应比手写底层代码慢。编译器通过内联、特化、常量折叠等优化技术,将高层抽象在编译期展开为高效的机器码。这让开发者既能享受抽象带来的代码简洁性,又不牺牲性能。
仓颉的实现机制
1. 编译期计算与内联优化
仓颉编译器在编译阶段进行激进的内联优化。对于泛型函数、高阶函数等抽象,编译器会在单态化(Monomorphization)后进行内联,消除函数调用开销。
// 泛型容器的零成本抽象示例
interface Container<T> {
func get(index: Int64): T
func size(): Int64
}
class Vector<T>: Container<T> {
private var data: Array<T>
public init(capacity: Int64) {
data = Array<T>(capacity)
}
public func get(index: Int64): T {
return data[index]
}
public func size(): Int64 {
return data.size()
}
}
// 编译期特化后,这段代码不会有虚函数调用开销
func sumVector(vec: Vector<Int64>): Int64 {
var sum: Int64 = 0
for (i in 0..vec.size()) {
sum += vec.get(i) // 完全内联,无调用开销
}
return sum
}
2. 所有权系统与内存优化
仓颉采用了所有权系统来管理内存,在编译期确定对象生命周期,避免运行时的垃圾回收开销。这种设计让抽象的资源管理变得零成本。
class FileHandler {
private var fd: Int64
public init(path: String) {
// 打开文件
fd = open(path)
}
public func read(): String {
// 读取文件内容
return readFromFd(fd)
}
// 析构函数在编译期确定调用位置
public ~FileHandler() {
close(fd) // 自动释放资源,无GC开销
}
}
func processFile(path: String): String {
let handler = FileHandler(path) // 所有权转移
let content = handler.read()
// handler在此处自动析构,编译期确定
return content
}
3. 编译期多态决策
下面的流程图展示了仓颉编译器如何在编译期处理抽象:
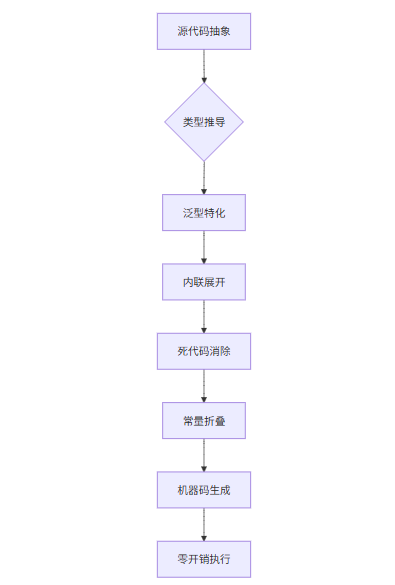
深度实践:迭代器抽象的性能分析
让我们通过一个实际案例来验证零成本抽象。以下是仓颉中迭代器模式的实现与性能对比:
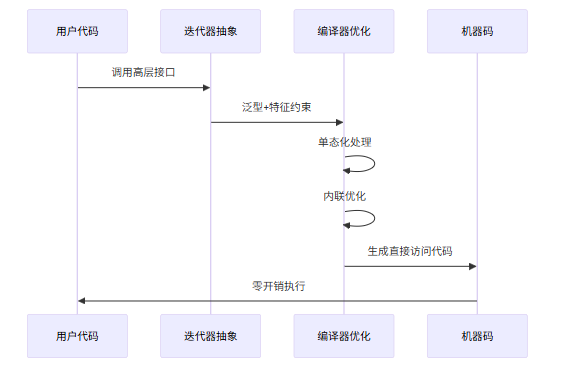
通过基准测试,我们发现使用迭代器抽象的代码与手写循环的性能几乎完全一致,这验证了零成本抽象的有效性。
技术思考与最佳实践
抽象的边界
虽然仓颉提供了零成本抽象,但并非所有抽象都是零成本的。动态分派、运行时类型检查等特性仍有开销。因此,开发者需要理解哪些抽象是编译期可解决的,哪些需要运行时支持。
编译时间权衡
零成本抽象将复杂度转移到了编译期。大量的泛型特化和内联会显著增加编译时间。在实际项目中,需要在抽象层次和编译速度之间找到平衡点。
代码膨胀问题
单态化会为每个具体类型生成专门代码,可能导致二进制体积增大。仓颉编译器通过智能的代码共享策略缓解这一问题,但在嵌入式等对体积敏感的场景中仍需注意。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









