




Solr是Apache开源的比较稳定的一款全文搜索引擎,也是市面上相对比较流行的一款全文搜索引擎,好不好用你用过之后自有判断。今天给大家分享一下它的安装与配置,我用的是7.7.2版本。废话不多说,开搞!
目录
一、solr简介
Solr是一个独立的企业级搜索应用服务器,它对外提供类似于Web-service的API接口。用户可以通过http请求,向搜索引擎服务器提交一定格式的XML文件,生成索引;也可以通过Http Get操作提出查找请求,并得到XML格式的返回结果。
二、下载
地址为: http://lucene.apache.org/solr/
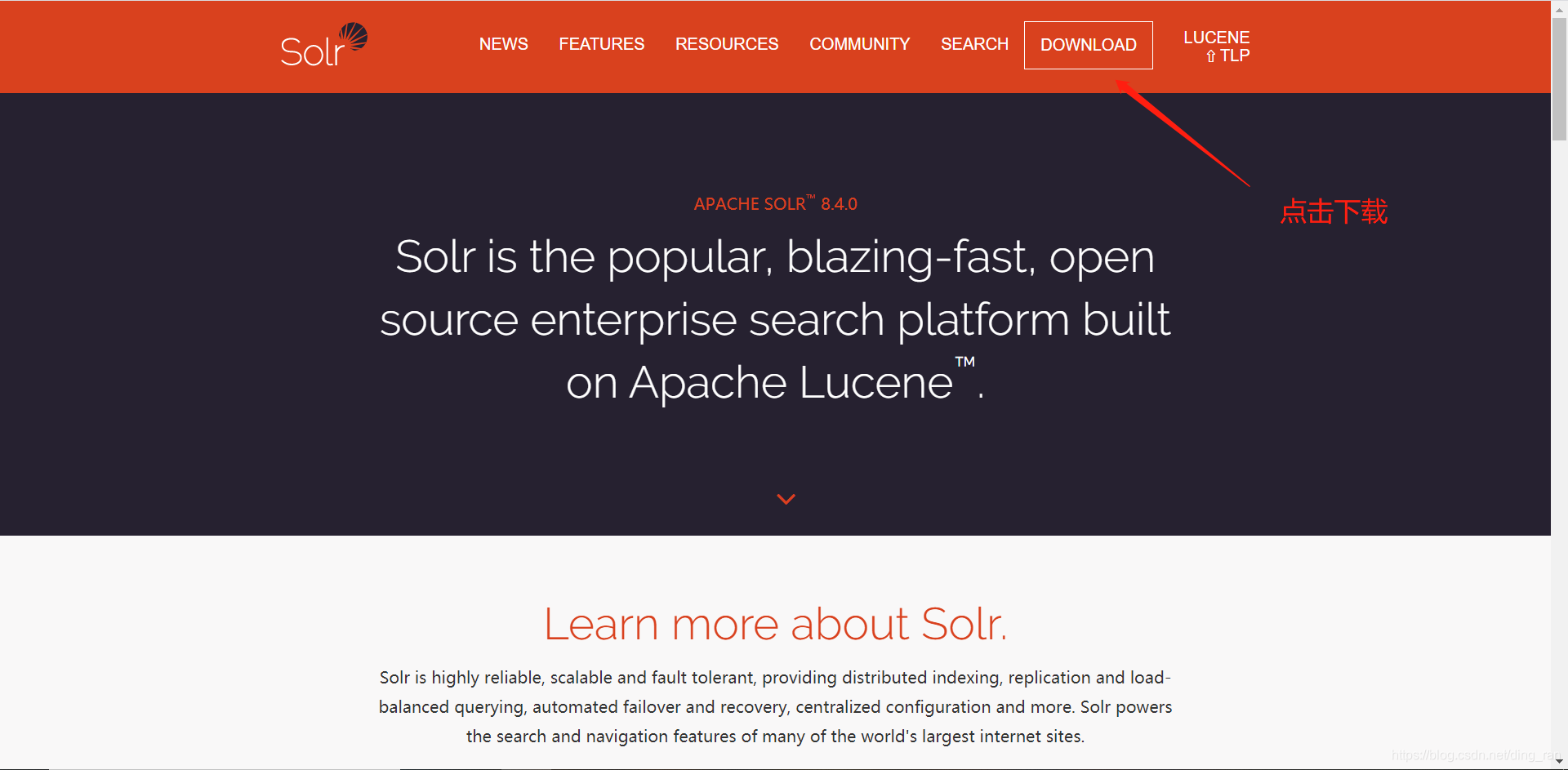
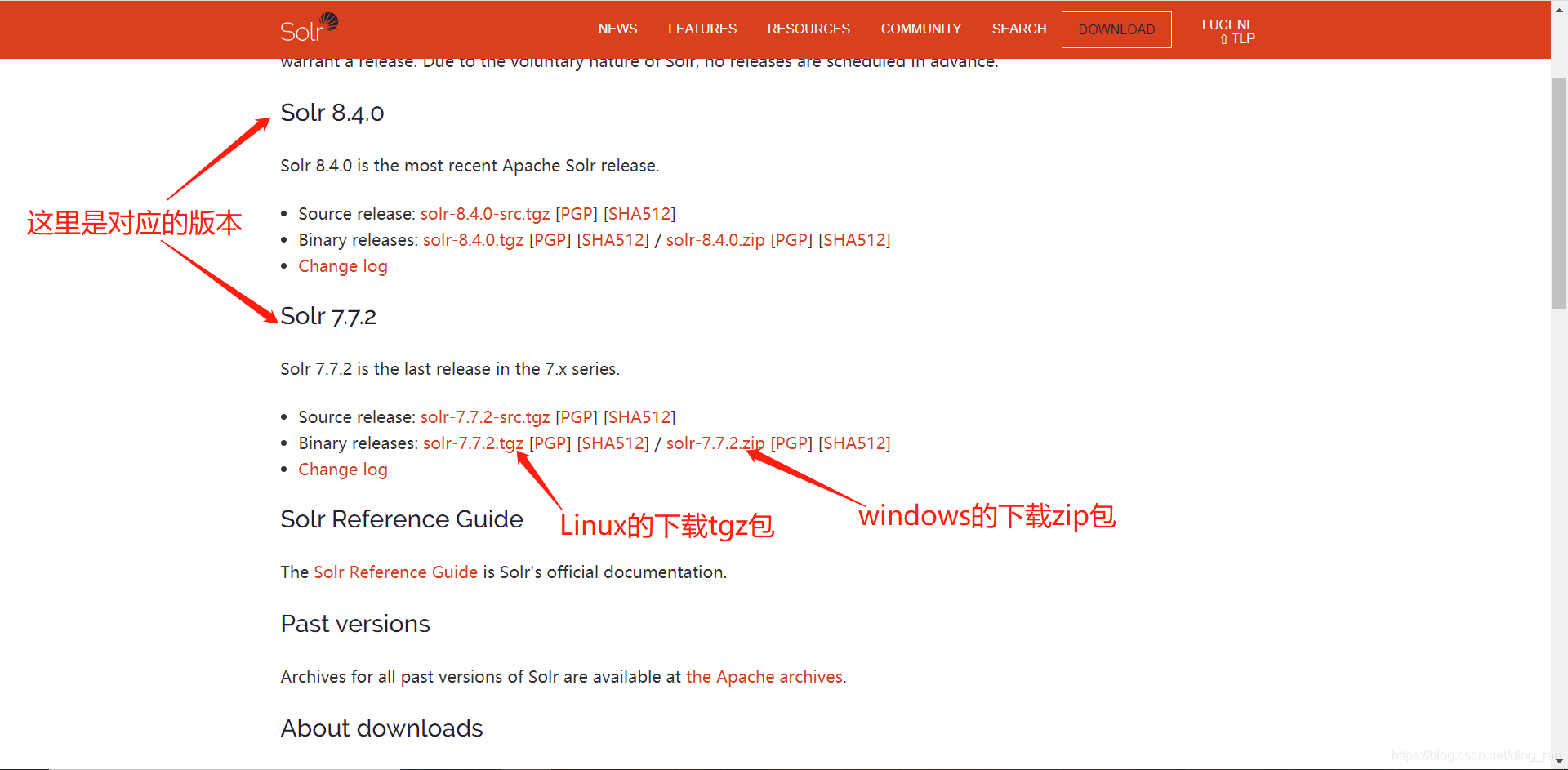
下载后解压到一个你认为比较合适的目录,常识性问题还是要提醒一下,不想给自己找麻烦的尽量不要放在中文路径中!
三、目录介绍
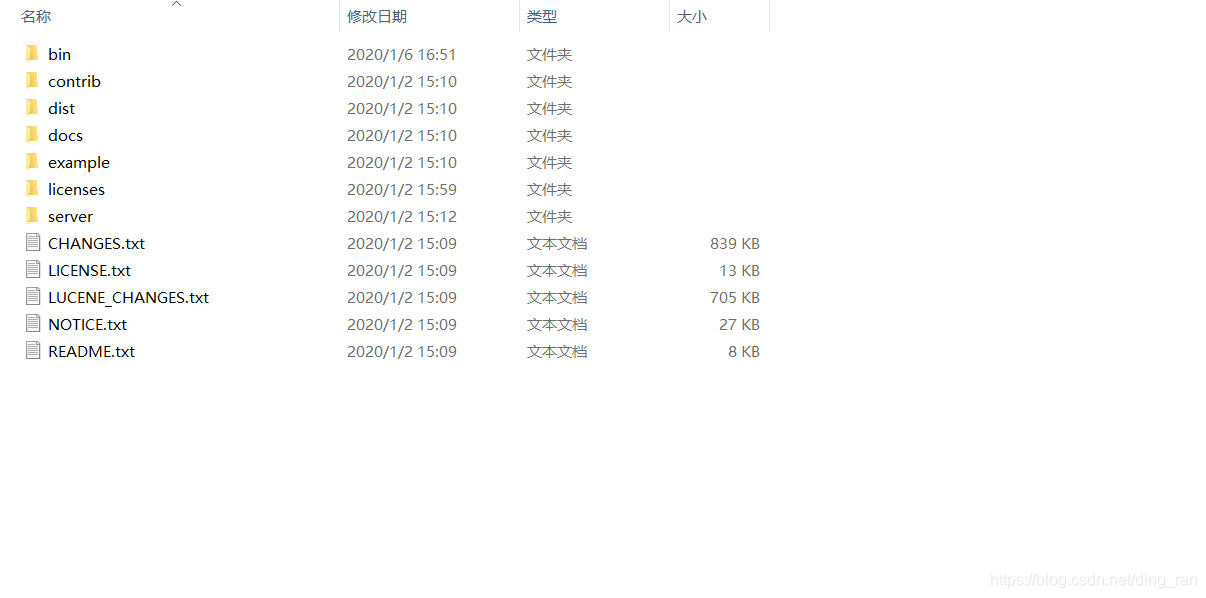
如图,解压后我们得到了一个这样的目录结构
- bin目录: 和其他软件的bin目录一样,bin目录是solr命令所在的目录,solr的所有命令都需要在 bin目录中执行。
- contribute目录:存放solr插件的目录,solr的很多插件都在此目录
- dist目录:存放的是solr和它爸爸Lucence的jar包
- docs目录:solr存放文本、文档、页面的目录,solr主页面就存放在此
- example目录:solr官方提供的solr配置示例的目录(不得不说还是很体贴呢,嘿嘿)
- licenses目录:solr存放许可证明的目录(都是很官方的文档,一般人用不上)
- server目录:个人认为solr最重要的目录,solr的启动目录,里面集成了solr自带的jetty服务器,我们创建的core也都存放在此,这个目录将会是我们经常访问的一个目录
下面那些文档就不细述了,想知道的打开百度翻译,输入文档名称就知道了(百度翻译给钱!!!)
四、启动solr
打开命令行,进入solr的bin目录,输入solr start,回车
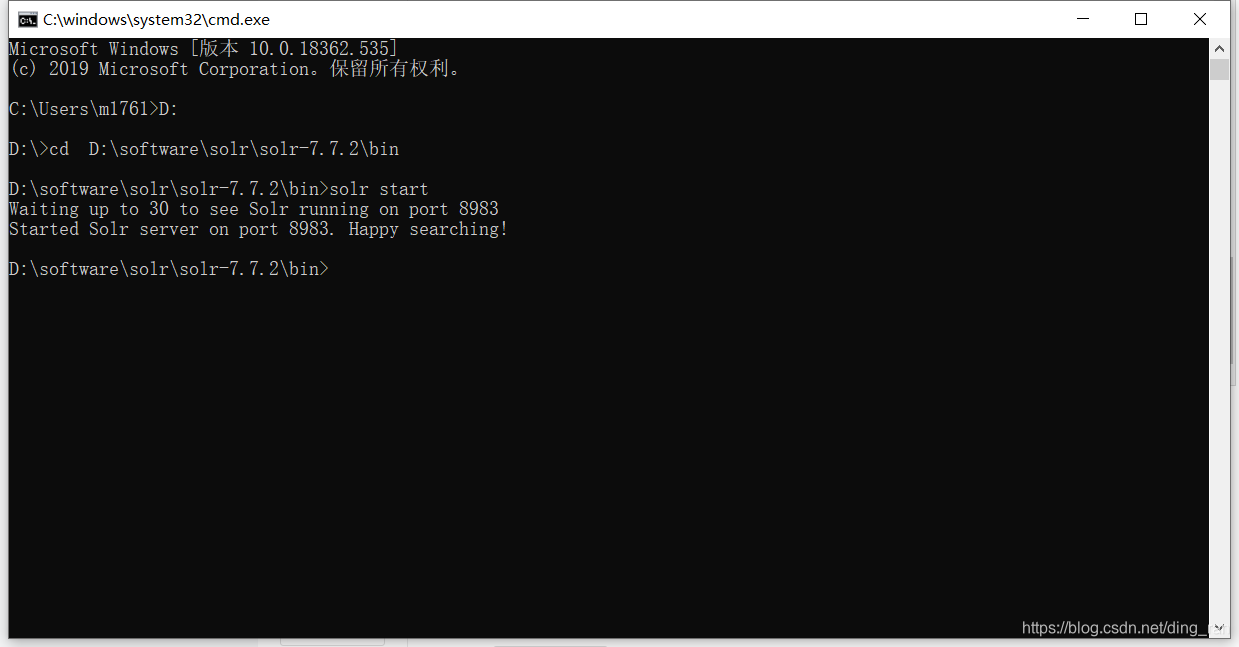
可以看到。solr的端口号默认为8983(当然,是可以自己配置的啦!)
然后打开浏览器,输入http://localhost:8983/solr
就来到了solr的主页面
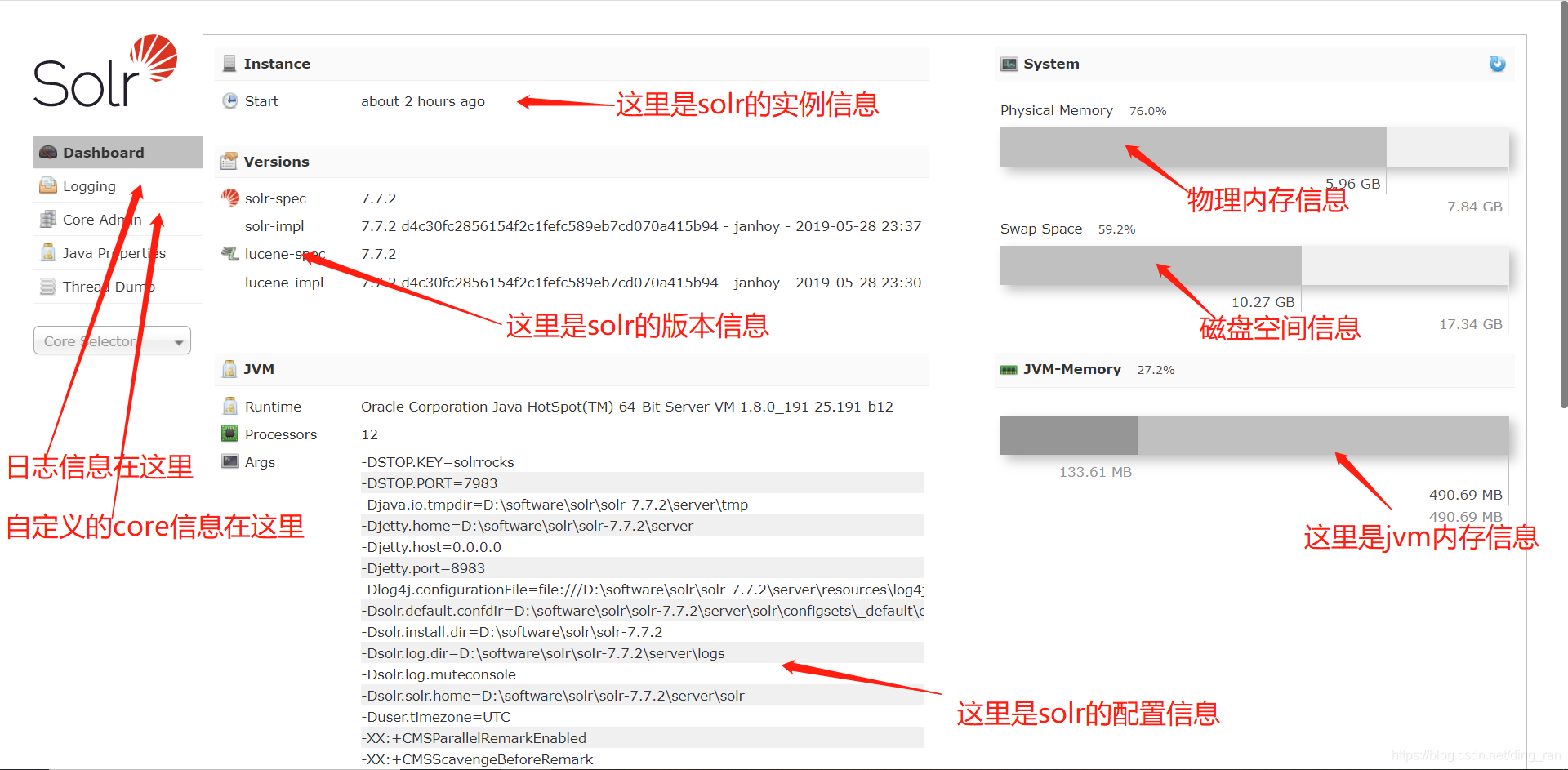
这个页面是我们操作solr及查看solr状态信息的页面 ,到这里,solr就启动成功了。下面,我们开始创建core。那什么是core呢?core就是solr的索引库,solr支持多个core实例,我们的查询都是基于core索引库实现的,怎么实现的我们后面会单独讲solr的查询原理。现在我们先创建一个自定义的core
五、创建core
core的创建方式有两种,第一种就是界面操作创建,第二种是通过命令创建。我们先说第一种:通过界面操作创建
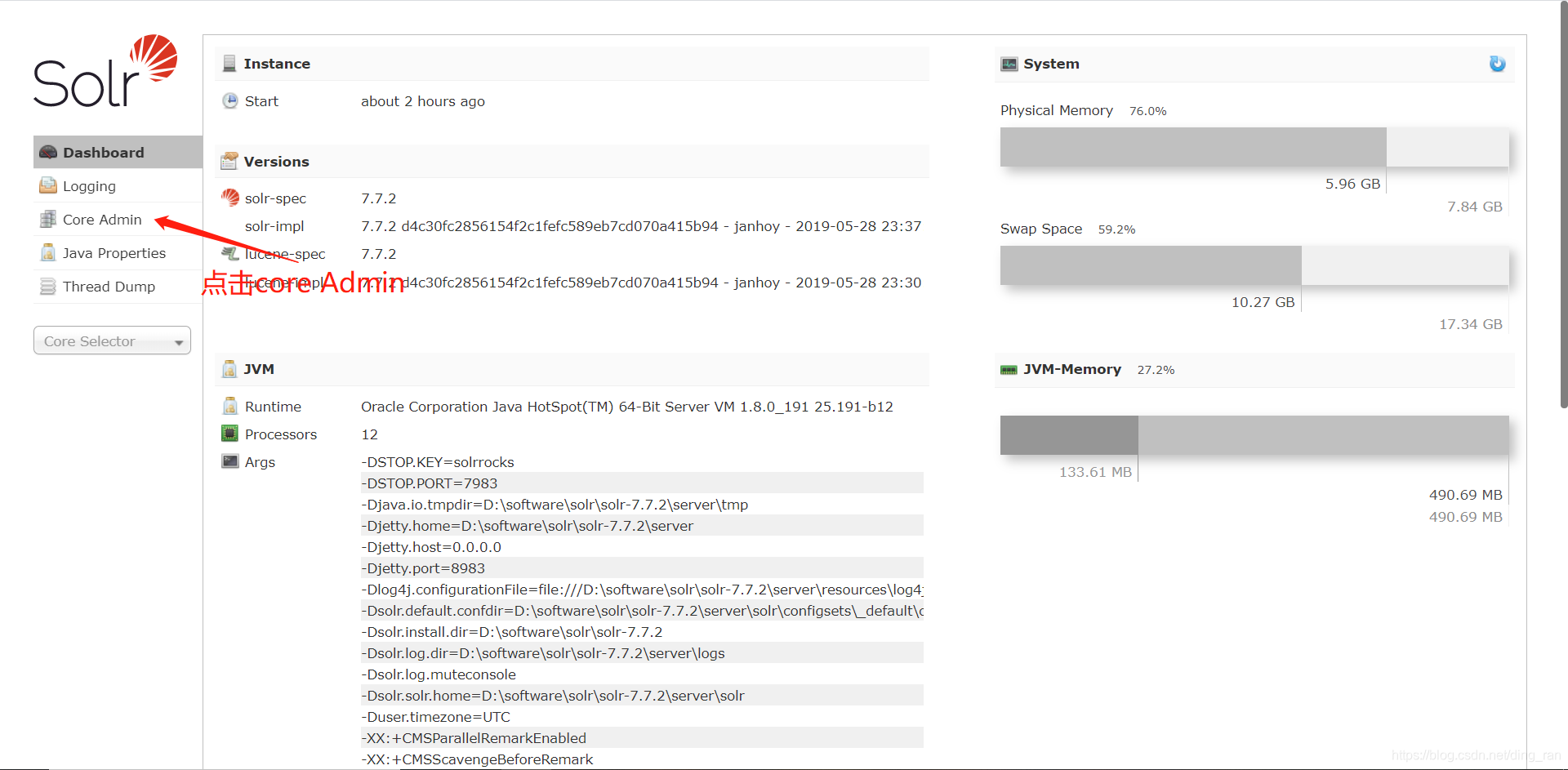
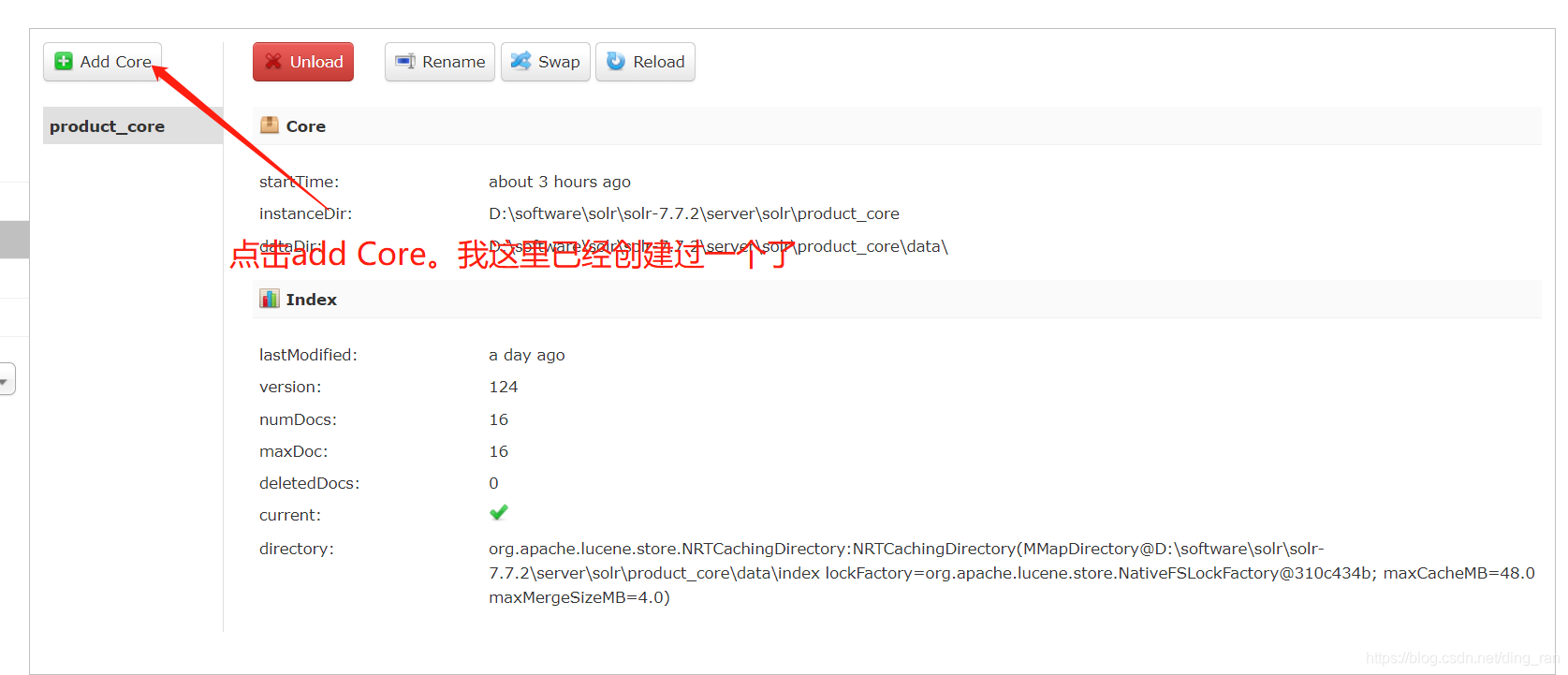
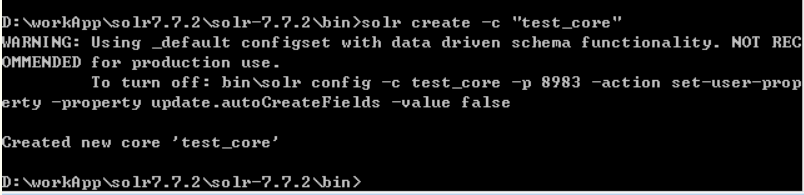
是不是很简单?告诉你一个比这个更简单的(一般人我不告诉他,点赞!!!) ,也就是第二种——通过命令创建,打开命令行窗口,进入solr的bin目录,优雅的打上一行 solr create -c "自定义core名称",回车,就搞定了。见下图(图是盗的,爱你们是真的,么么哒!)
core创建成功之后再主页面的Core Admin中会有显示,参考我上面那张图。创建成功之后进入到solr7.7.2——>server——>solr 目录能看到我们新建的core文件夹
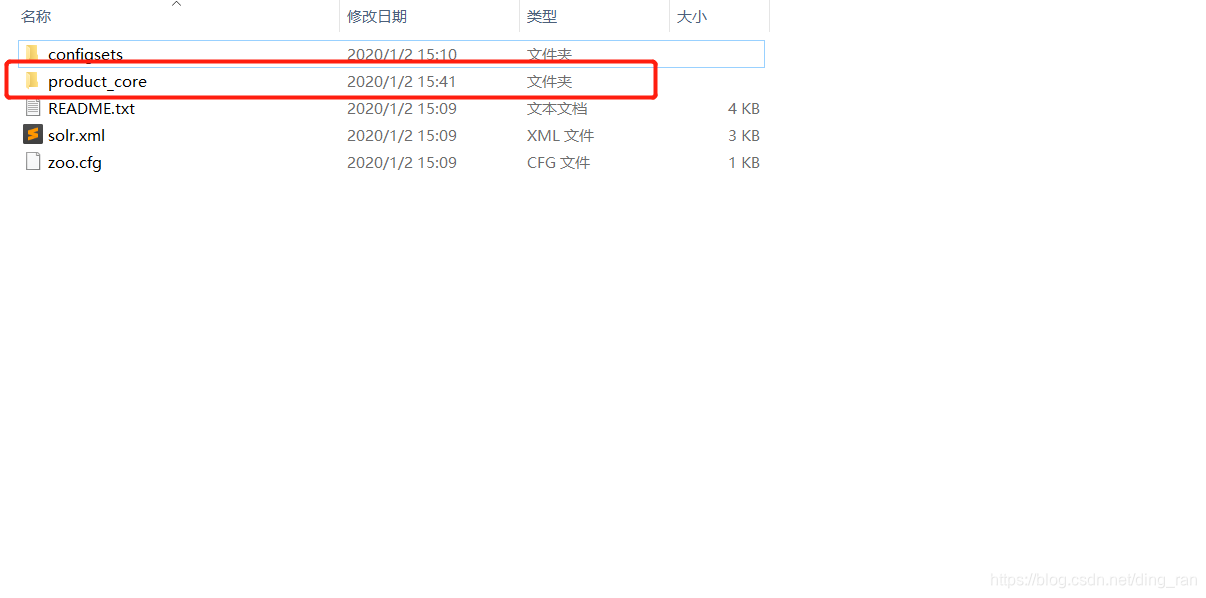
进入文件夹中之后,映入眼帘的便如下图所示
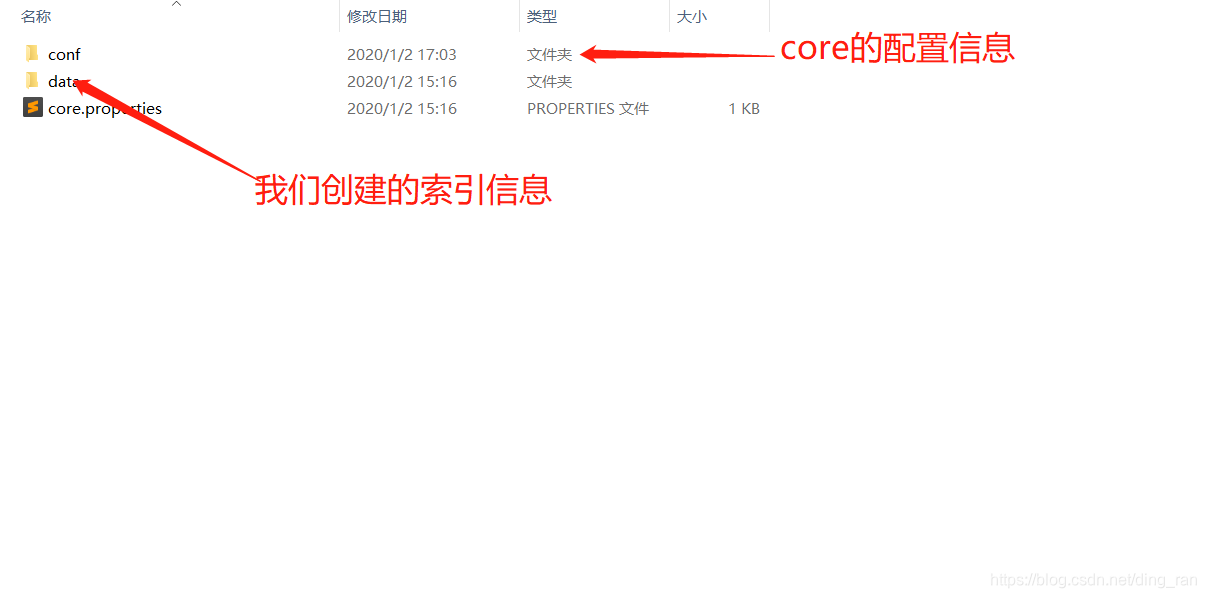
到这里,我们的core就创建成功了,接下来干嘛?当然是导数据啊!不然我下载一个solr摆着看啊!
六、DIH全量导入Mysql数据
这里扫盲一下,DIH是指DataImportHandler,是solr数据导入处理器(此处应有掌声!)。solr的数据导入分两种,一种是全量导入,一种是增量导入。全量导入是指清空数据,导入全部数据;增量导入是指在原有数据的基础上增加。我们今天讲的是全量导入Mysql数据,废话不多说,开搞!
1.创建数据导入配置文件
在自定义core文件夹的conf文件夹下(我的是product_core/conf)新建一个xml文档,名称随意,我的叫dataConfig.xml
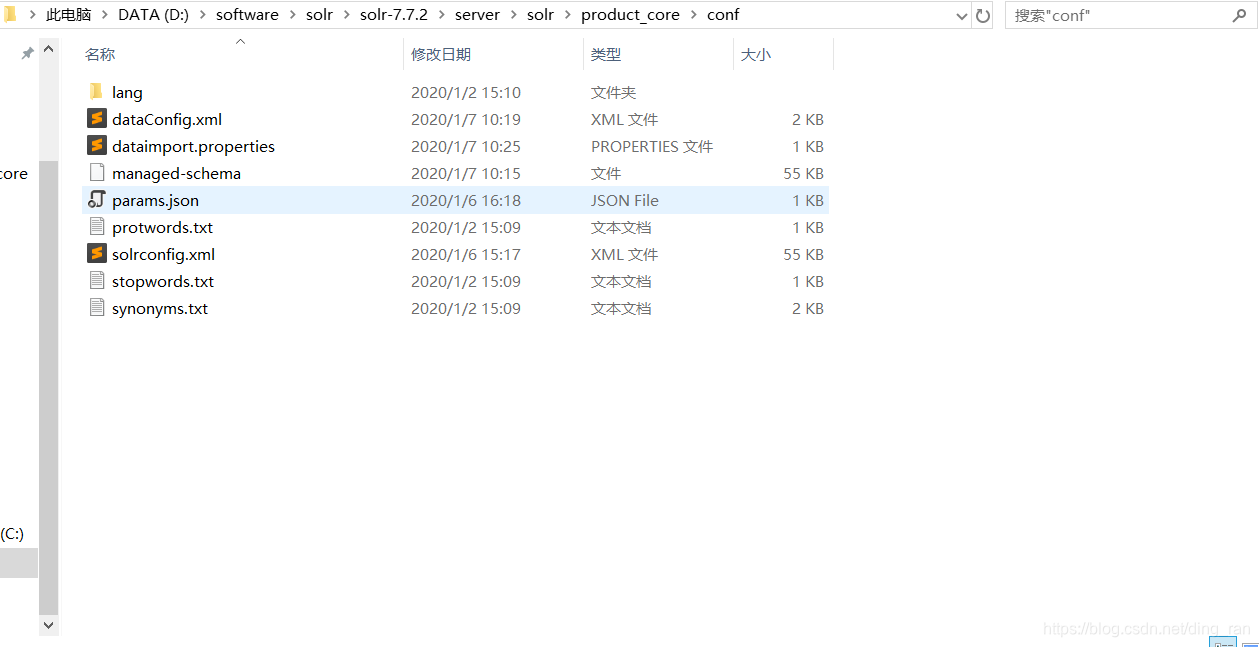
我的里面有一些文档你们没有是正常的,因为我已经导入过了,就会多几个导入的文件 ,你新建一个dataConfig.xml文件就对了
2.编辑dataConfig.xml
这里以我的为例
<?xml version="1.0" encoding="UTF-8" ?>
<dataConfig>
<dataSource
type="JdbcDataSource"
driver="com.mysql.cj.jdbc.Driver"
url="jdbc:mysql://localhost:3306/mrmf?useUnicode=true&characterEncoding=utf-8&useSSL=true&serverTimezone=UTC"
user="数据库账号" password="数据库密码"/>
<document>
<entity name="product" query="SELECT ID,BUSINESS_ID,LABEL_ID,PRODUCT_NAME,PRODUCT_PROFILE,PRODUCT_PRICE,PICTURE_URL,PAGE_URL,PAGE_TYPE,SHARE_COUNT,COLLECTION_COUNT,UPDATE_TIME,CREATE_TIME FROM product_info">
<field column="ID" name="productId"/>
<field column="BUSINESS_ID" name="businessId"/>
<field column="LABEL_ID" name="labelId"/>
<field column="PRODUCT_NAME" name="productName"/>
<field column="PRODUCT_PROFILE" name="productProfile"/>
<field column="PRODUCT_PRICE" name="productPrice"/>
<field column="PICTURE_URL" name="pictureUrl"/>
<field column="PAGE_URL" name="pageUrl"/>
<field column="PAGE_TYPE" name="pageType"/>
<field column="SHARE_COUNT" name="shareCount"/>
<field column="COLLECTION_COUNT" name="collectionCount"/>
<field column="UPDATE_TIME" name="updateTime"/>
<field column="CREATE_TIME" name="createTime"/>
</entity>
</document>
</dataConfig>如代码所示,第一步先配置数据库连接信息,第二步,配置要导入的表字段信息,entity标签就是表实体信息,name是自己取的,随意,查询的话再加一个query属性,写上查询所有的语句。field标签中的name也是自己起的,后面要用。这里有两个巨坑,困扰我了两天才解决!第一,查询语句关键字要大写,不然可能会造成数据导入不全;第二,数据库中为空的字段查询的时候是不显示的,不显示为空的字段!!!当然,本人觉得这个是可以配置的,只是还没找到在哪配置。。。。。好了,不扯了,按照这个代码把表信息和数据库信息都配置正确之后就要开始第三步了
3.配置solrconfig.xml
dataConfig.xml配置好之后就要配置solrconfig.xml了,不然solr怎么知道你在哪配置了个什么东西?solrconfig.xml在同目录下,打开solrconfig.xml,在下面添加一下如下代码
<requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler">
<lst name="defaults">
<!-- 配置文件的路径应该也可以使用绝对路径 -->
<str name="config">dataConfig.xml</str>
</lst>
</requestHandler>起的其他名称的小伙伴也记得要把 名称写对哦,就加在</config>标签上面就行
4.配置managed-schema
同目录下打开managed-schema,这个文件是配置数据类型及索引和返回结果的。打开后往下拉,你会看到里面的<field>标签,就是配置我们返回的字段和索引的。如下图,配置我们的数据库表字段信息及索引信息
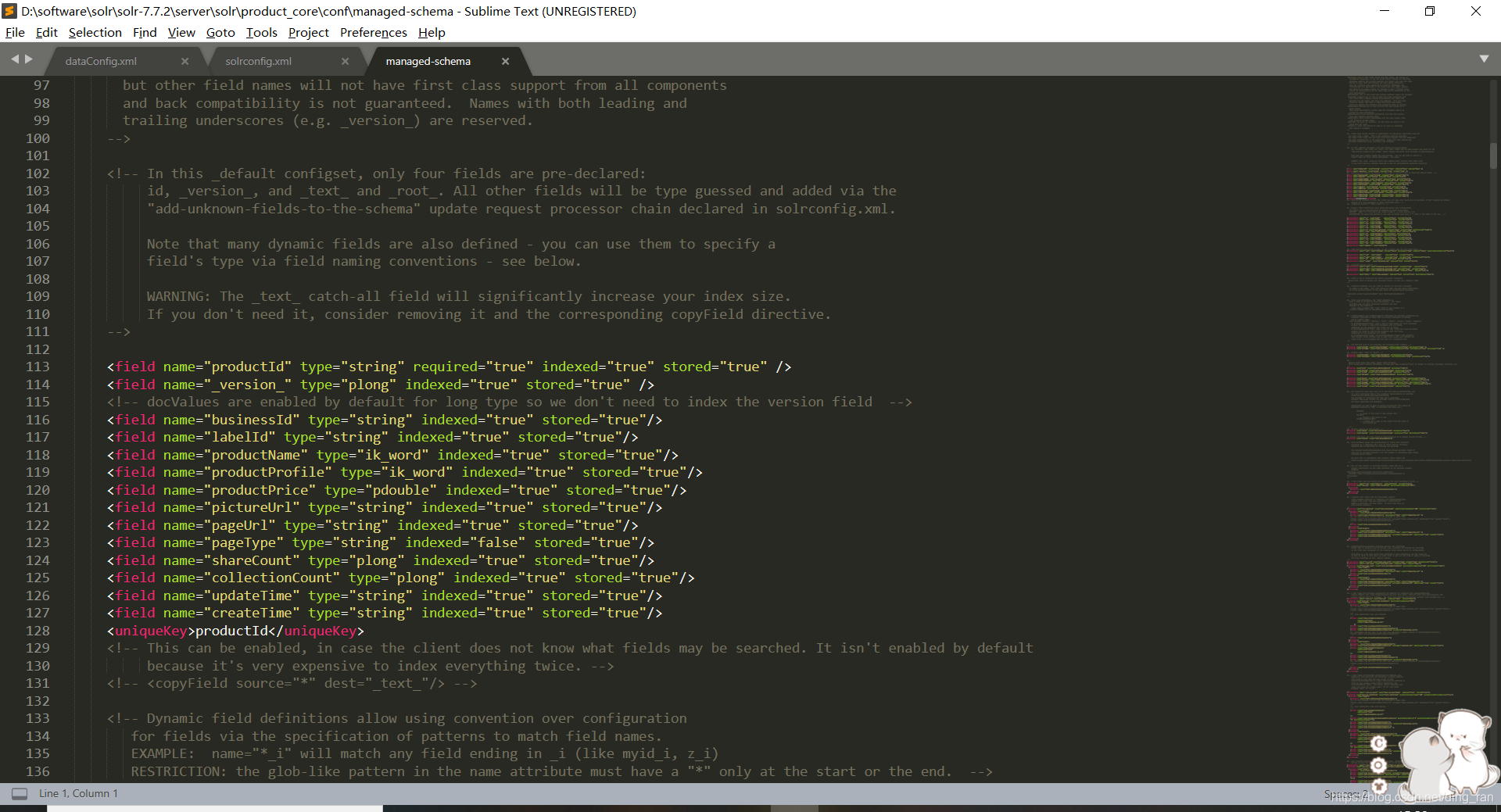
solr默认给我们创建了_version_、_root_、_text_等字段的field,不用删,solr内部要用,尤其是_version_,我们直接添加我们直接的field标签就好,上图中的type="ik_word"先配置你们的字段类型,分词器配置之后再改为ik_word。不然会报错。这里说一下field标签中属性的意义
.name:我们在dataConfig.xml中自定义的字段名称,也是我们查询出来的字段名称,要与dataConfig.xml文件中配置的字段name一致
.type:就是字段类型,需要注意的是要写这个文件下面定义过的字段类型,没定义过得字段类型不要写,可以看一下下面都配置了哪些类型。
.indexed:是否索引字段,值为true或false
.stored:是否存储该索引,值为true或false。主页面的很多操作会要求索引字段被存储过才能操作。
.multiValued:主要结合<copyField>标签使用,一filed里面是否有多个字段的值,值为true或false
这里有一个问题需要注意一下,就是solr默认给我们配置了一个主键id,就是<uniqueKey>标签中的id,这个标签是必须要的,如果你的主键不是id,那你要记得修改为自己的主键id,如上图,我的主键id为productId,记得和你在dataConfig.xml中配置的name保持一致。
5.导入MySQL连接jar包和数据导入jar包
我的项目用的是MySQL8.0版本,所以连接的jar包名称就是mysql-connector-java-8.0.18.jar。小伙伴们要根据自己的项目情况选择对应的MySQL的jar包,复制这个jar包到solr7.7.2/server/solr-webapp/webapp/WEB-INF/lib目录下。(记住这个目录,一会配置分词器还得用。)
数据导入jar包有两个,都在solr7.7.2/dist目录下,名称分别为solr-dataimporthandler-7.7.2.jar 和 solr-dataimporthandler-extras-7.7.2.jar,复制这两个jar包到solr7.7.2/server/solr-webapp/webapp/WEB-INF/lib目录下就可以了,和MySQL连接jar包在一个位置
6.导入数据
该配置的都已经配置完了,下面就可以导入数据了打开我们的solr主页面,不用重启。
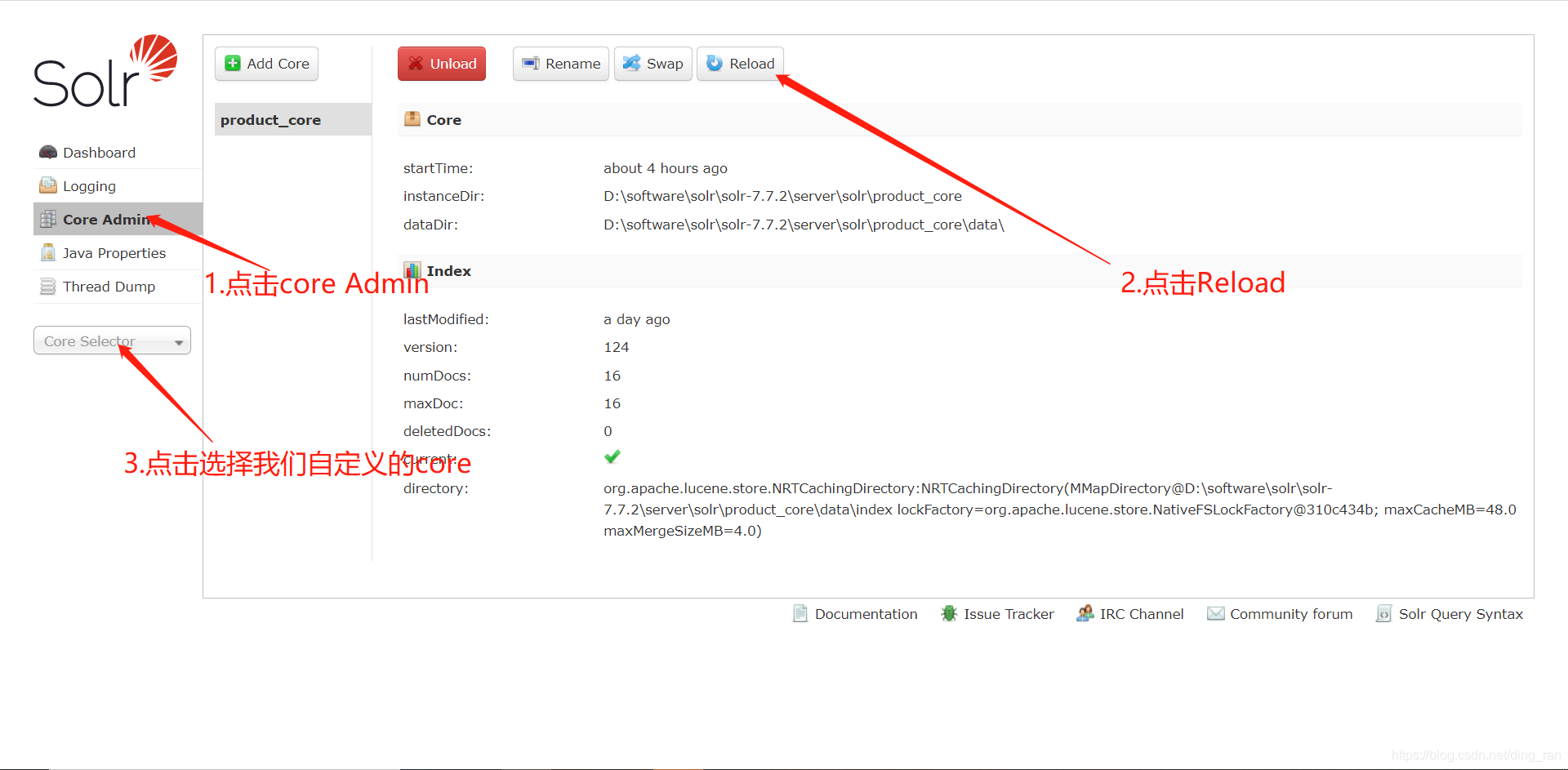
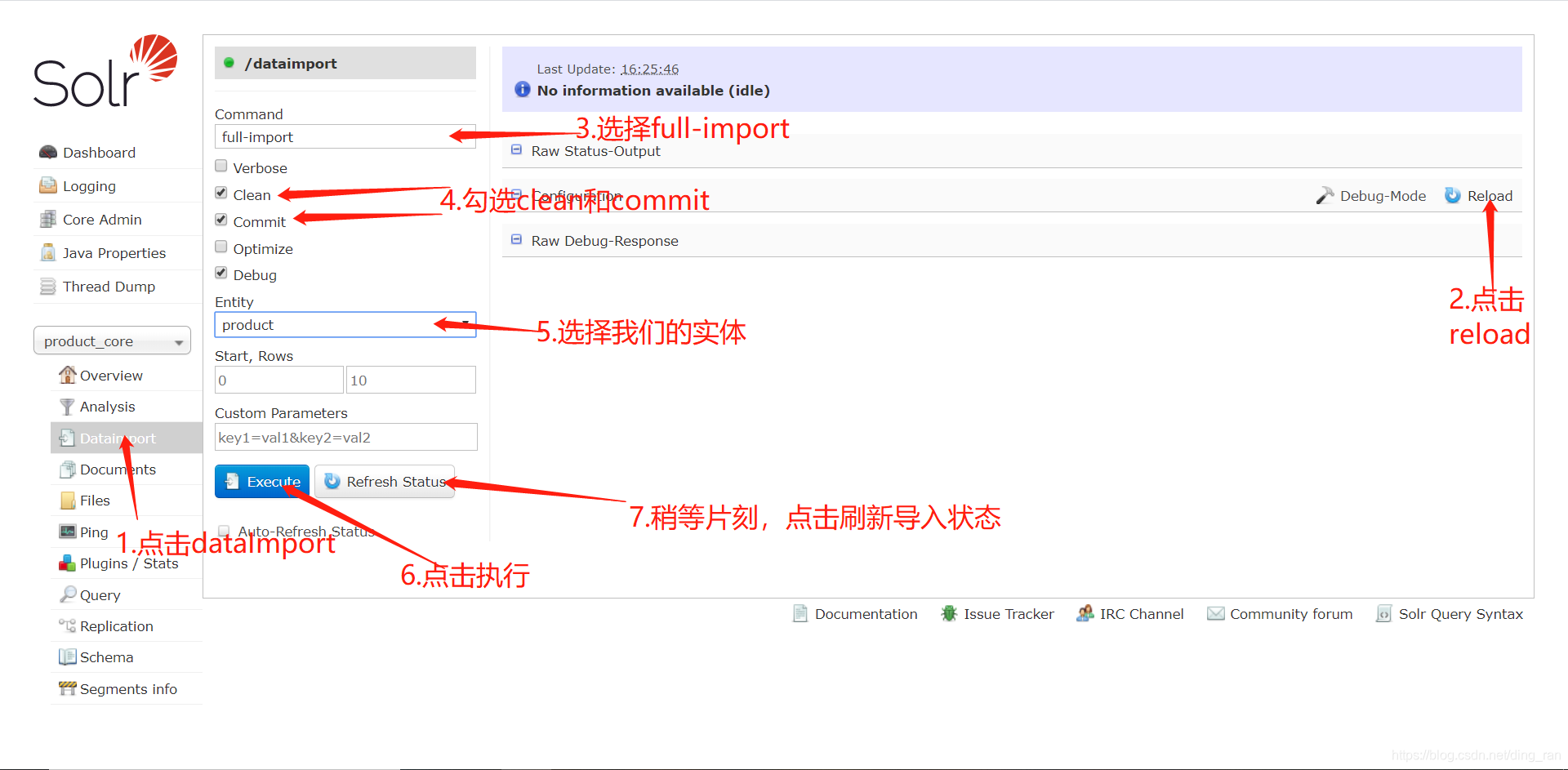
按照上面的步骤,导入成功之后在上方会有成功或失败的提示
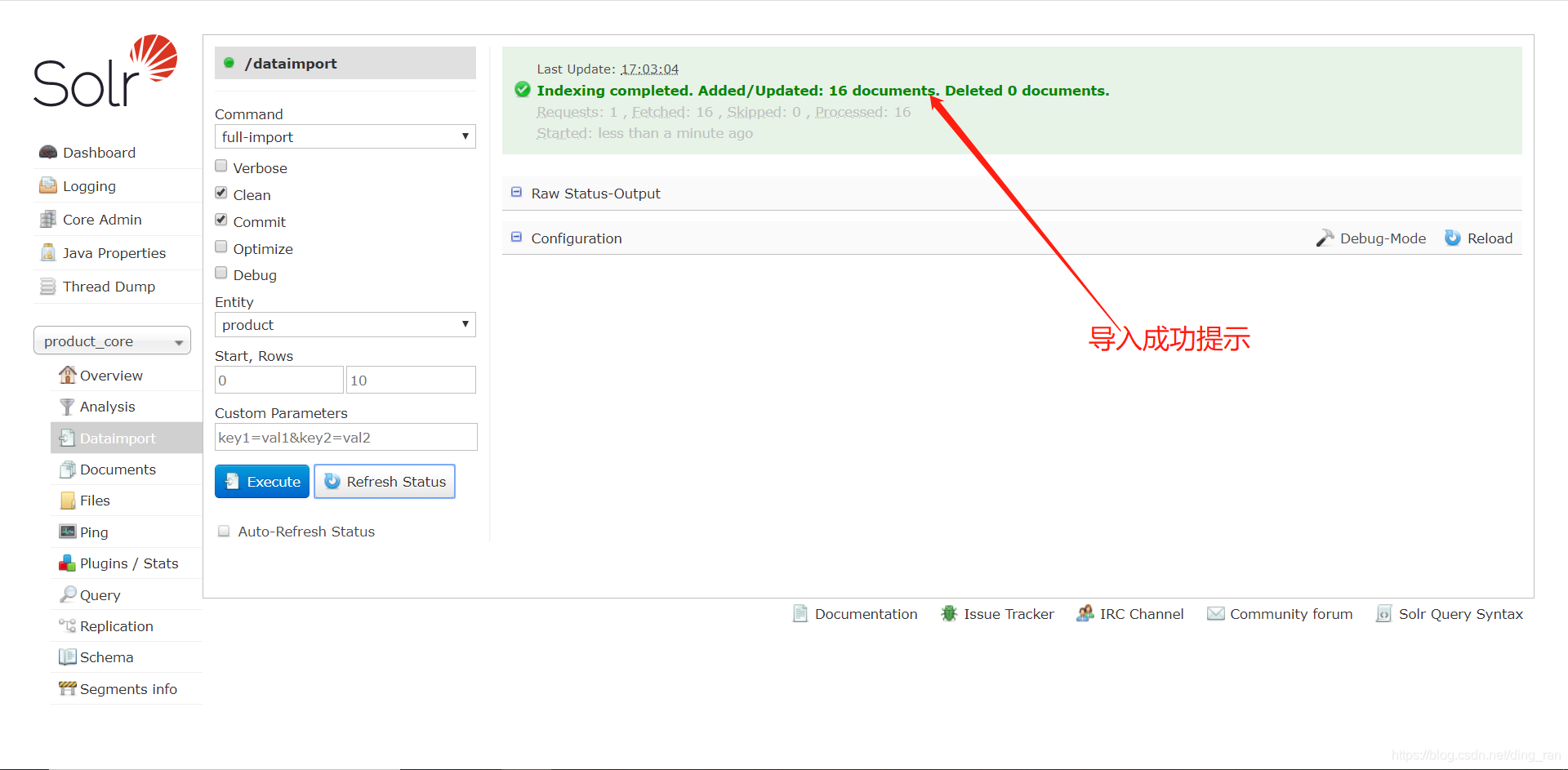
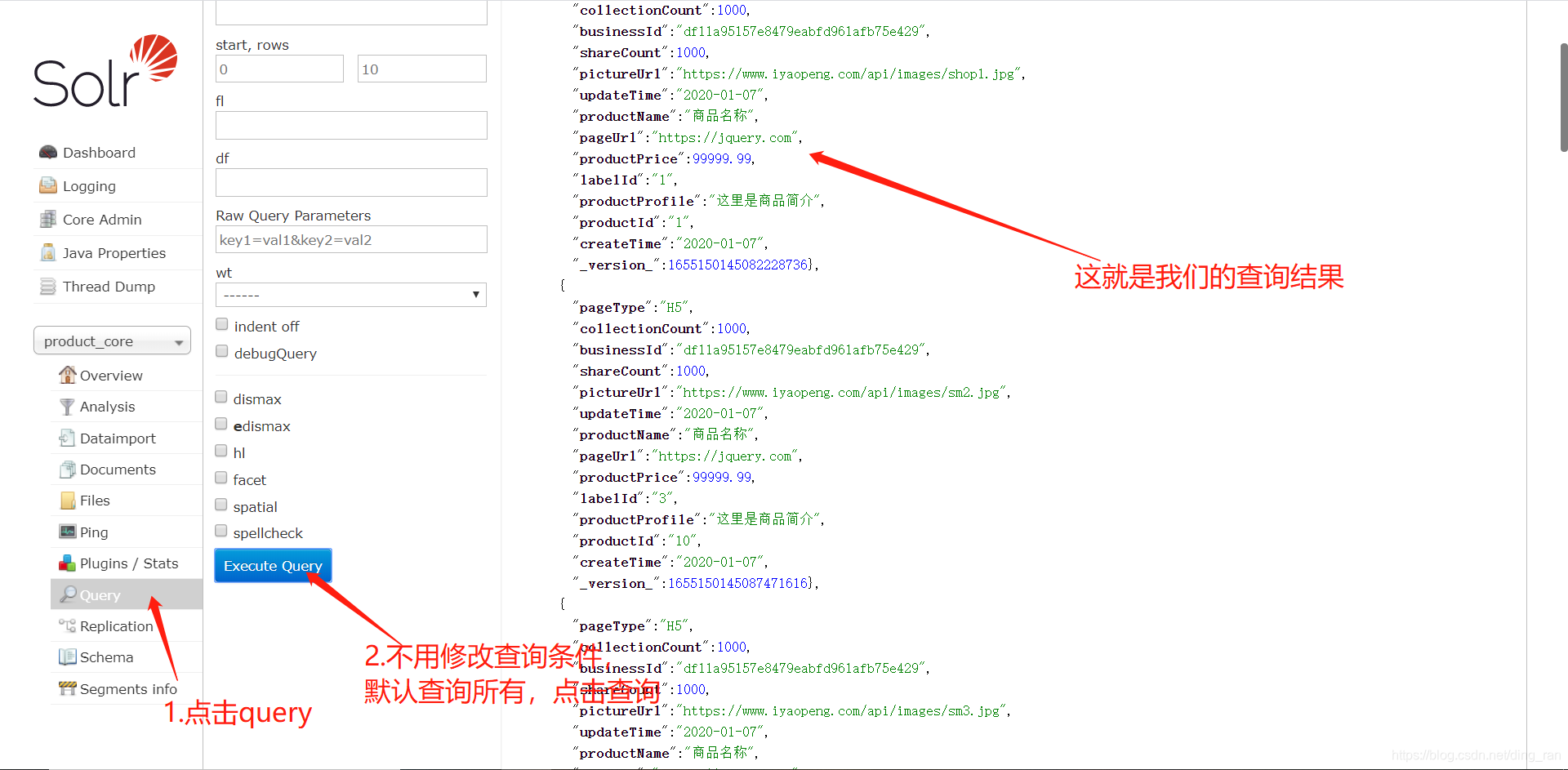
到这里,我们的数据就导入成功了,下面我们来测试一下导入的结果
7.测试导入结果
到这里,我们的DIH全量导入MySQL数据就结束了,但是还有一个问题,就是现在还没有实现分词,如下图1,分词前我们搜索的话一句话是不会被分开的,这就导致我们后面搜索关键字查询高亮显示查询结果的时候不会高亮显示关键字,而是高亮显示一整句话,就是因为现在还没有分词。分词后就能将一句话分成若干个词,高亮显示的也是关键字而不是一句话,如下图2,下面和我一起引入IK分词器实现分词效果吧。
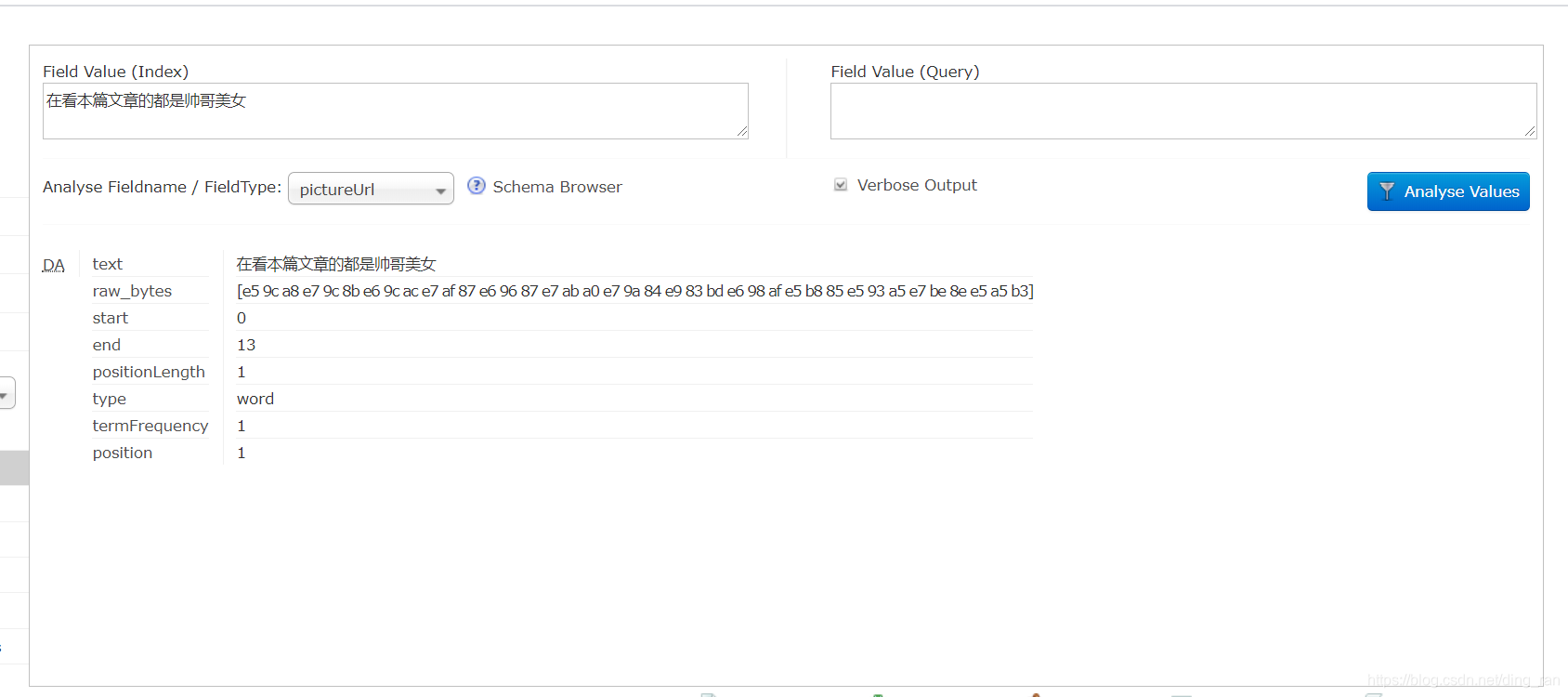
pictureUrl字段是没有分词的,所以一句话没有被拆开
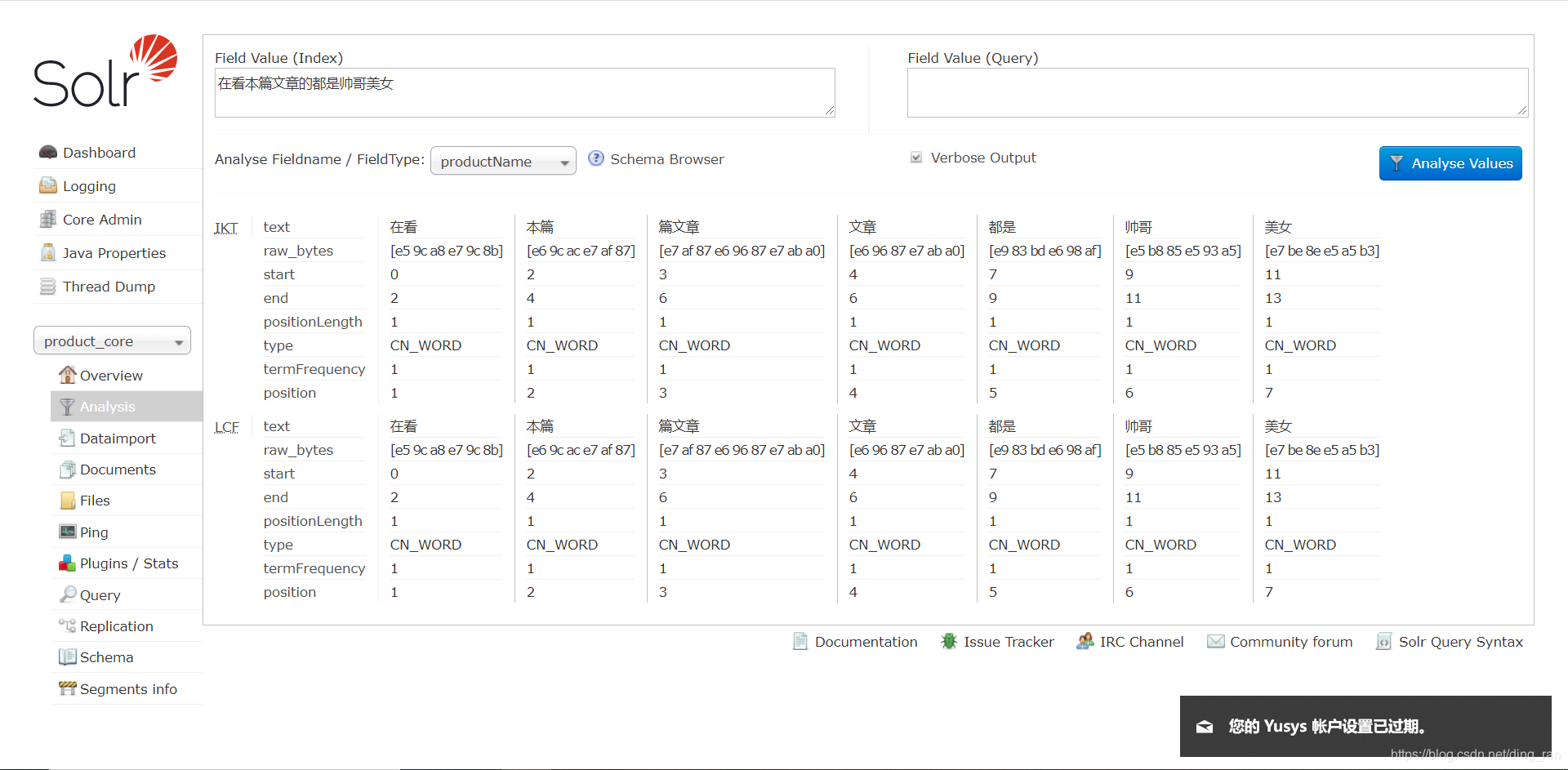
productName字段实现分词了的,所以同样一句话能拆分成若干个词
七、引入IK分词器实现分词
1.下载ik分词器jar包,我下载的是ik-analyzer-solr7-7.x.jar,传送门
2..把jar包放到你刚刚mysql连接jar包的位置,也就是solr7.7.2/server/solr-webapp/webapp/WEB-INF/lib目录下
3.在solr7.7.2/server/solr-webapp/webapp/WEB-INF目录下新建文件夹“classes”
4.从ik分词器的jar包中也就是ik-analyzer-solr7-7.x.jar中解压出里面的IKAnalyzer.cfg.xml、ext.dic、stopword.dic这三个文件放到刚刚新建的classes目录下
这里解释一下为什么要这三个文件
IKAnalyzer.cfg.xml:ik分词器的主配置文件,默认配置了扩展词典和禁用词典,可以自主修改,也可以用它默认的
ext.dic:ik分词器的扩展词典,在里面可以配置ik分词器分辨不出来的词汇,注意该文档要保持无DOM,UTF-8编码格式(它默认就是这样)
stopword.dic:ik分词器的禁用词典,在里面可以配置禁用词汇,注意该文档要保持无DOM,UTF-8编码格式(它默认就是这样)
5.在managed-schema文件中引入ik分词器字段类型。不知道这个文件在哪的小伙伴看前面就知道了。我在前面有说过,引入代码如下
<fieldType name="ik_word" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="true" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>配置到该文件下面那一堆<fieldType>标签后面即可
6.修改要分词的字段类型为ik_word。
![]()
7.重启solr,验证分词
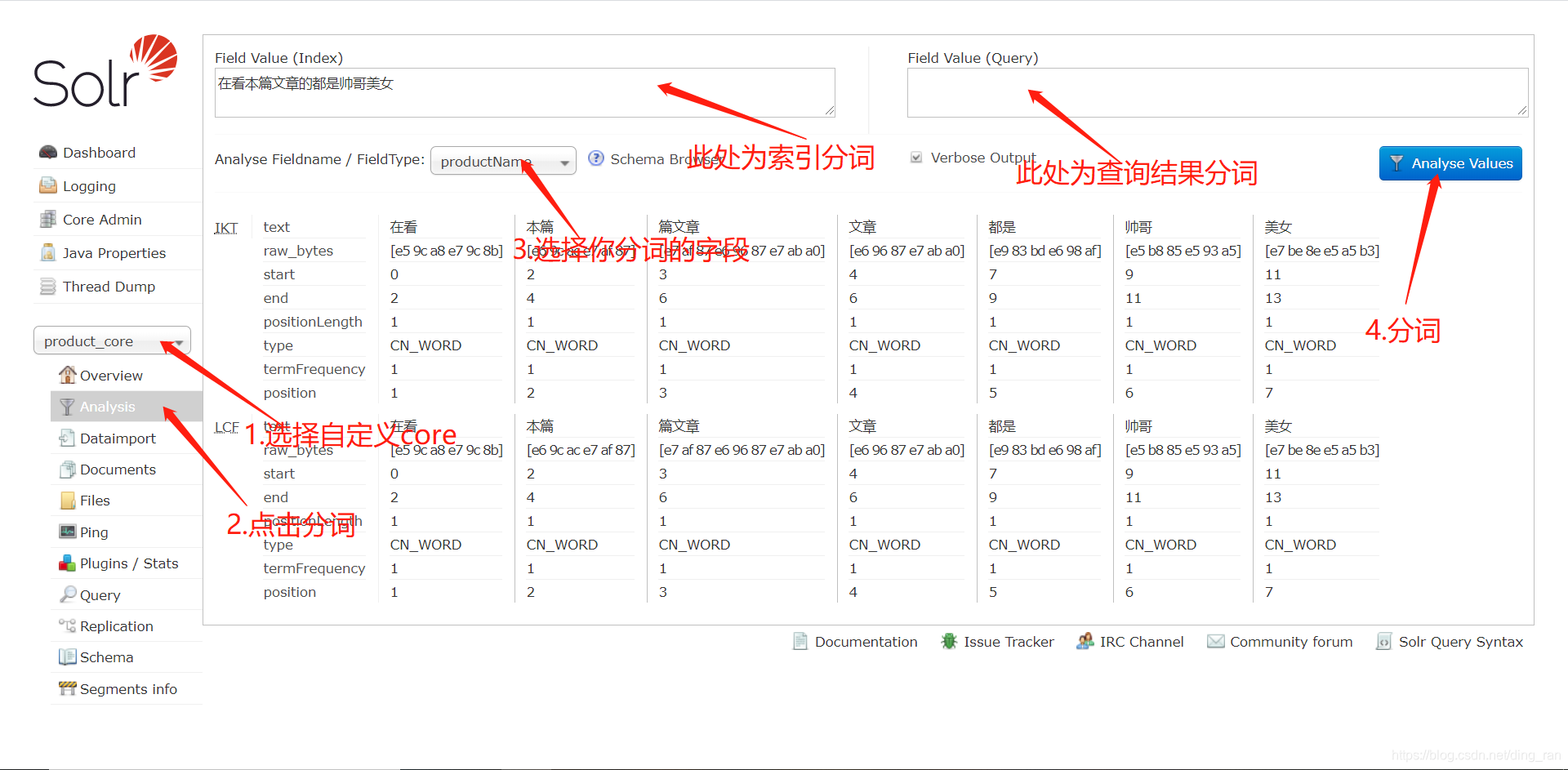
索引分词和查询结果分词都可以验证我们的分词效果,遇到分词器无法辨别的词汇可以在扩展词典中配置。
好了,到这里我们的分词就结束了,solr也能执行查询了,分词效果也有了,就可以在项目中初步使用了,下一期我会给大家分享springboot整合solr完成增删改查。感兴趣的小伙伴记得点赞关注收藏哦,你们的满意是我持续更新的最大动力。

















 891
891

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









