







使用Logistic Regression方法对MNIST 数据集进行数字识别
问题描述
请设计下述算法,求解 MNIST 数据集上的Logistic Regression问题:
- 梯度下降法
- 随机梯度法
对于每种算法,请给出每步计算结果与最优解的距离以及每步计算结果在测试集上所对应的分类精度。此外,请讨论随机梯度法中Mini Batch大小对计算结果的影响。可参考:
http://deeplearning.net/tutorial/logreg.html
任务描述
MINIST数据集:
MNIST数据集由Yann LeCun搜集,是一个大型的手写体数字数据库,通常用于训练各种图像处理系统,也被广泛用于机器学习领域的训练和测试,是简单的灰色图像手写数字数据集。MNIST 是一个经典的手写数字数据集,其原始数据集包含 60000 个训练数据和 10000 个测试数据。每个数据的样本特征为 28×28 像素的灰度图(784 维向量),表示一个手写数字;标签为 0~9 中的一个数字。
任务分析:
读取数据后分析数据,并建立相关的预测模型,该模型读取一个样本数据后输出预测的标签。模型通过训练数据进行训练,并在测试数据上进行测试。训练期间采用梯度下降法、随机梯度法以及不同大小的mini batch进行训练,通过调整不同的参数达到较为理想的预测准确度,并根据实验结果分析不同算法的特征。
准备工作:数据读取与分析
首先下载对应的数据集到代码同一文件夹:
数据下载地址: http://yann.lecun.com/exdb/mnist/
将4个gz文件下载并移动到代码同一文件夹,在该网站可以看到该数据集的详细介绍,重点如下:
train-images-idx3-ubyte:训练集图像
train-labels-idx1-ubyte:训练集标签
t10k-images-idx3-ubyte:测试集图像
t10k-labels-idx1-ubyte:测试集标签
数据下载的网站里有数据的简单介绍,idx3和idx1数据略有不同,故读取时需要分类考虑:
# -*- coding: utf-8 -*-
"""
Created on Mon Dec 16 10:22:12 2019
@author: Ding
"""
import numpy as np
import matplotlib.pyplot as plt
import gzip as gz
#--------------------读取数据----------
#filename为文件名,kind为'data'或'lable'
def load_data(filename,kind):
with gz.open(filename, 'rb') as fo:
buf = fo.read()
index=0
if kind=='data':
#因为数据结构中前4行的数据类型都是32位整型,所以采用i格式,需要读取前4行数据,所以需要4个i
header = np.frombuffer(buf, '>i', 4, index)
index += header.size * header.itemsize
data = np.frombuffer(buf, '>B', header[1] * header[2] * header[3], index).reshape(header[1], -1)
elif kind=='lable':
#因为数据结构中前2行的数据类型都是32位整型,所以采用i格式,需要读取前2行数据,所以需要2个i
header=np.frombuffer(buf,'>i',2,0)
index+=header.size*header.itemsize
data = np.frombuffer(buf, '>B', header[1], index)
return data
#--------------------加载数据-------------------
X_train = load_data('train-images-idx3-ubyte.gz','data') # 训练数据集的样本特征
y_train = load_data('train-labels-idx1-ubyte.gz','lable') # 训练数据集的标签
X_test = load_data('t10k-images-idx3-ubyte.gz','data') # 测试数据集的样本特征
y_test = load_data('t10k-labels-idx1-ubyte.gz','lable') # 测试数据集的标签
#---------查看数据的格式-------------
print('Train data shape:')
print(X_train.shape, y_train.shape)
print('Test data shape:')
print(X_test.shape, y_test.shape)
#--------------查看几个数据-----------
index_1 = 1024
plt.imshow(np.reshape(X_train[index_1], (28, 28)), cmap='gray')
plt.title('Index:{}'.format(index_1))
plt.show()
print('Label: {}'.format(y_train[index_1]))
index_2=2048
plt.imshow(np.reshape(X_train[index_2], (28, 28)), cmap='gray')
plt.title('Index:{}'.format(index_2))
plt.show()
print('Label: {}'.format(y_train[index_2]))
读取数据后存储在x_train,y_train,x_test,y_test中,查看了其中的两个数据,看一下数据的情况:
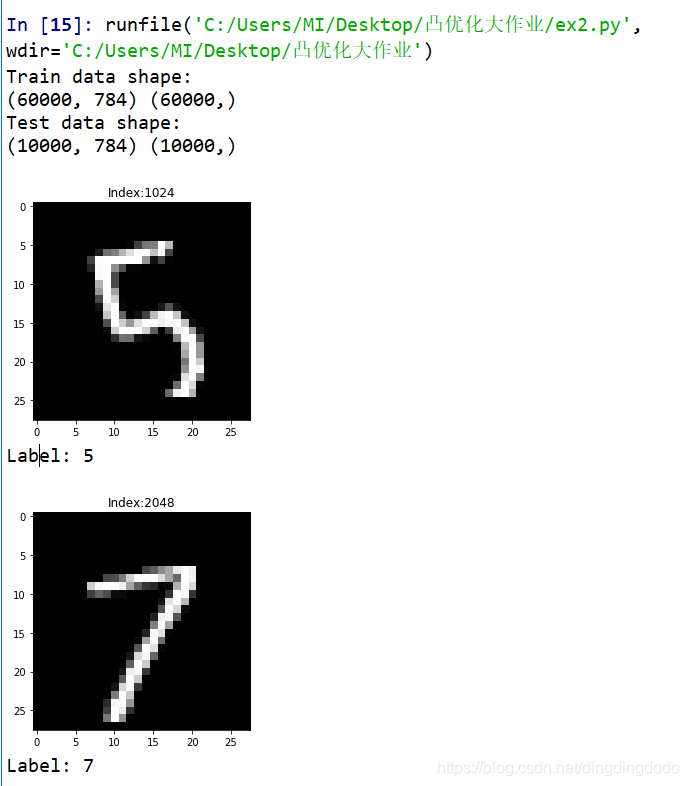
所以可以看出train数据中有60000个,test数据中有10000,data中数据为手写数字图像,在示例中我们可以看到图像还是较易识别的。
建立Logistic Regression模型
该问题是一个多分类问题,因此使用Logistic Regression时激活函数选用Softmax函数:
S i ( x ) = e x i ∑ j e x j S_i(x)=\dfrac{e^{x_i}}{\sum_{j} e^{x_j}} Si(x)=∑jexjexi该函数可以将输入映射为 0 − 1 0-1 0−1之间的实数,同时具有归一化的特征,因此与概率可以对应,易与分类任务对应。
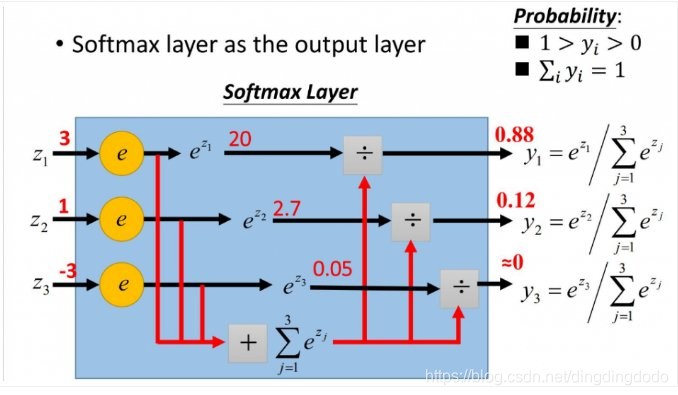 故根据这个思路,建立Logistic Regression模型。
故根据这个思路,建立Logistic Regression模型。
定义损失函数:
在使用softmax函数时,我们普遍采用交叉熵作为损失函数:
L = − ∑ i K p ( x i ) l o g ( q ( x i ) ) L =-\sum_i^K p(x_i)log(q(x_i)) L=−i∑Kp(xi)log(q(xi))其中 p p p 表示期望的概率分布, q q q 表示实际的概率分布, L L L 表示交叉熵。
交叉熵刻画的是实际输出概率和期望输出概率的距离,交叉熵的值越小,则两个概率分布越接近,即实际与期望差距越小 。交叉熵可以反映出隐藏在输出结果背后的更深的错误率表现出来。
因此,在softmax模型中,用交叉熵函数表示的损失函数为:
J = − ∑ i = 1 K y i l o g ( p i ) J=-\sum_{i=1}^Ky_ilog(p_i) J=−i=1∑Kyilog(p
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1146
1146











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









