






— 1、概述
许多Web应用程序提供大量静态内容,相当于从磁盘读取数据原封不动地写回响应套接字。
这个操作似乎只需要相对较少的CPU时间,但它的效率有点低:内核从磁盘读取数据,并跨越内核空间 - 用户空间边界,将其推到应用程序,然后应用程序将其写到套接字中。实际上,应用程序充当了一个低效的中介 - 将数据从磁盘文件挪到Socket。
每次数据穿越内核空间 - 用户空间边界时,都必须进行复制,这会消耗CPU周期和内存带宽。
幸运的是,您可以通过一种称为零拷贝的技术来消除这些复制。使用零拷贝的应用程序请求内核直接将数据从磁盘文件复制到套接字,而不经过应用程序。
零拷贝极大地提高了应用程序的性能,减少了内核态和用户态之间的上下文切换次数。
在Linux和UNIX系统上,Java类库通过java.nio.channels.FileChannel中的long transferTo(...)方法支持零拷贝。可以使用transferTo()方法将字节数据直接从调用它的通道传输到另一个可写的字节通道,而数据不需要流经应用程序。
本文先演示通过传统复制语义进行的简单文件传输所带来的开销,然后展示使用transferTo()的零复制技术如何获得更好的性能。
— 2、传统数据传输方式
考虑一下从文件中读取数据,然后通过网络将数据传输到另一个程序的场景。(此场景描述了许多服务器应用程序的行为,包括提供静态内容的Web应用程序、FTP服务器、邮件服务器等。)
两个核心方法调用见 Listing 1 📚(点击下载完整的示例代码):
📚 Listing 1. Copying bytes from a file to a socket
File.read(fileDesc, buf, len);
Socket.send(socket, buf, len);
虽然Listing 1📚 代码很简单,但是在内部实现上,复制操作需要在用户态和内核态之间进行四次上下文切换,并且在操作完成之前复制数据四次。
Figure 1 显示了内部是如何从文件移动到套接字的:
 |
|---|
| Figure 1. 传统数据拷贝方式 Traditional data copying approach |
步骤如下:
-
用户程序调用
read()方法,导致OS从用户态到内核态的1️⃣🔃第一次上下文切换(参见Figure 2)。在OS内部,会调用sys_read()系统调用(或等效方法)来从文件中读取数据。第一个副本(参见图1)由 直接内存访问(DMA) 引擎执行,该引擎从磁盘读取文件内容并将其存储到内核地址空间缓冲区中(第一次复制1️⃣📘)。 -
请求的大量数据从
读缓冲区复制到用户缓冲区(第二次复制2️⃣📘),然后read()方法返回。方法返回导致2️⃣🔃第二次内核态到用户态的上下文切换 。现在数据存储在用户缓冲区(用户地址空间缓冲区)中。 -
Socket.send()方法调用导致从用户态切换内核态(3️⃣🔃第三次上下文切换)。,再次将数据放入
内核地址空间缓冲区(执行第三次复制3️⃣📘)。不过,这一次数据被放入一个不同的缓冲区(Socket Buffer),这个缓冲区与目标 Socket 相关联。 -
send()方法返回,导致4️⃣🔃第四次上下文切换。DMA引擎将数据从内核缓冲区传递到协议引擎(这是第四次复制4️⃣📘),这个过程是DMA引擎独立且异步进行的。
Figure 2 显示了上下文切换
 |
|---|
| Figure 2. Traditional context switches |
使用中间的内核缓冲区(而不是直接将数据传输到用户缓冲区)可能看起来效率很低。但是进程中引入了中间内核缓冲区就是为了提高性能。
在读取端使用中间缓冲区允许内核缓冲区在应用程序没有请求内核缓冲区所持有的数据时充当“预读缓存”,当请求的数据量小于内核缓冲区大小时,这将显著提高性能。
写入端的中间缓冲区允许异步完成写操作。
不幸的是,如果所请求的数据的大小远远大于内核缓冲区的大小,这种方式本身就会成为性能瓶颈。数据在最终交付给应用程序之前,会在磁盘、内核缓冲区和用户缓冲区之间复制多次。
零拷贝通过消除这些冗余的数据拷贝以提升性能。
— 3、零拷贝方式数据传输
如果重新检查传统的场景,您会注意到实际上并不需要第二和第三个数据副本。应用程序只是缓存数据并将其传输回套接字缓冲区。相反,数据可以直接从读缓冲区传输到Socket缓冲区。transferTo()方法允许您完成这一操作。
Listing 2📚显示了transferTo()方法的声明:
📚Listing 2. The transferTo() method
public void transferTo(long position, long count, WritableByteChannel target);
transferTo()方法将数据从文件通道传输到给定的可写字节通道。在内部,它依赖于底层操作系统对零拷贝的支持;
在UNIX和各种Linux中,这个调用被路由到sendfile()系统调用,如 Listing 3 📚所示,它将数据从一个文件描述符传输到另一个文件描述符:
📚Listing 3. The sendfile() system call
#include <sys/socket.h>
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);
Listing 1 中的 file.read()和socket.send()调用的操作可以被一个transferTo()调用代替,如清单3、4所示:
 |
|---|
| Figure 3 - 调用transferTo()方法时数据的传输路径 |
📚Listing 4. Using transferTo() to copy data from a disk file to a socket
transferTo(position, count, writableChannel);
 |
|---|
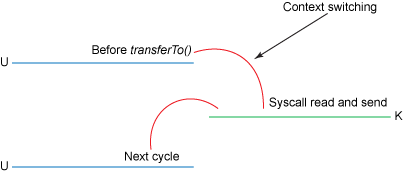
| Figure 4 - 调用transferTo()方法时的上线文切换 |
在清单4中使用transferTo() 时采取的步骤是:
- transferTo()方法导致DMA引擎将文件内容复制到一个读取缓冲区中。然后,内核将数据复制到与输出Socket关联的内核缓冲区中。
- 当DMA引擎将数据从内核套接字缓冲区传递到协议引擎时,会发生第三次复制。
改进:我们将上下文切换从4次减少到2次,并将数据复制从4次减少到3次(其中只有一个涉及到CPU)。但这并没有让我们达到零拷贝的目标。
如果底层网络接口卡支持收集操作,我们可以进一步减少内核所做的数据重复。在Linux内核2.4及更高版本中,修改了套接字缓冲区描述符以适应这一需求。这种方法不仅减少了多个上下文切换,还消除了需要CPU参与的重复数据赋值,用户端仍然保持不变,但本质已经改变:
- transferTo()方法导致DMA引擎将文件内容复制到内核缓冲区中。
- 没有数据被复制到套接字缓冲区。相反,只有包含数据位置和长度信息的描述符才会被附加到套接字缓冲区中。DMA引擎直接将数据从内核缓冲区传递到协议引擎,从而消除了CPU拷贝。
图5显示了具有数据收集功能的transferTo()方法的数据拷贝过程
Figure 5. 底层网卡支持收集操作时,使用transferTo() 方法的数据传输过程
 |
|---|
— 4、构建文件服务器
现在,让我们使用在客户机和服务器之间传输文件的相同示例来实践零拷贝(有关示例代码,请参阅下载)。
TraditionalClient.java和 TraditionalClient.java 基于传统的复制语义,使用File.read()和Socket.send()。
TraditionalClient.java是一个服务器程序,它监听客户端要连接的特定端口,然后每次从套接字中读取4K字节的数据。
TraditionalClient.java 连接到服务器,从文件中读取(使用file .read()) 4K字节的数据,并通过socket将内容发送给服务器(使用socket.send())
 |
|---|
| Table 1. Performance comparison: Traditional approach vs. zero copy |
可以看到,与传统方法相比,transferTo() API减少了大约65%的时间。对于需要将大量数据从一个I/O通道复制到另一个通道(如Web服务器)的应用程序,这可能会显著提高性能。
As you can see, the transferTo() API brings down the time approximately 65 percent compared to the traditional approach. This has the potential to increase performance significantly for applications that do a great deal of copying of data from one I/O channel to another, such as Web servers.
—5、总结
我们已经演示了相较于从一个通道读取数据然后将其写入另一个通道, 使用transferTo()的性能优势。中间缓冲区的拷贝(哪怕他隐藏在内核中)的成本是可以测量的。
在需要在通道之间进行大量数据复制的应用程序中,零复制技术可以显著提高性能。















 2333
2333











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









