







String
== 问题
String str1 = "hello world";
String str2 = "hello world";
String str3 = new String("hello world");
System.out.println(str1==str2);//true
System.out.println(str1==str3);//falsestr2 = "hello world",直接从字符串常量池中取值,就是上面的str2,str1两个引用指向的是共同一个对象。
new String();则是创建对象放到堆中,不管堆中是否已有这个对象
String对象的改变
public String concat(String str) {
int otherLen = str.length();
if (otherLen == 0) {
return this;
}
char buf[] = new char[count + otherLen];
getChars(0, count, buf, 0);
str.getChars(0, otherLen, buf, count);
return new String(0, count + otherLen, buf);
} public String substring(int beginIndex, int endIndex) {
if (beginIndex < 0) {
throw new StringIndexOutOfBoundsException(beginIndex);
}
if (endIndex > count) {
throw new StringIndexOutOfBoundsException(endIndex);
}
if (beginIndex > endIndex) {
throw new StringIndexOutOfBoundsException(endIndex - beginIndex);
}
return ((beginIndex == 0) && (endIndex == count)) ? this :
new String(offset + beginIndex, endIndex - beginIndex, value);
}StringBuilder
public StringBuilder() {
super(16);
}
AbstractStringBuilder(int capacity) {
value = new char[capacity];
} public AbstractStringBuilder append(String str) {
if (str == null) str = "null";
int len = str.length();
if (len == 0) return this;
int newCount = count + len;
if (newCount > value.length)
expandCapacity(newCount);
str.getChars(0, len, value, count);
count = newCount;
return this;
} void expandCapacity(int minimumCapacity) {
int newCapacity = (value.length + 1) * 2;
if (newCapacity < 0) {
newCapacity = Integer.MAX_VALUE;
} else if (minimumCapacity > newCapacity) {
newCapacity = minimumCapacity;
}
value = Arrays.copyOf(value, newCapacity);
} public static char[] copyOf(char[] original, int newLength) {
char[] copy = new char[newLength];
System.arraycopy(original, 0, copy, 0,
Math.min(original.length, newLength));
return copy;
}线程安全
public synchronized StringBuffer append(String str) {
super.append(str);
return this;
} public synchronized StringBuffer append(StringBuffer sb) {
super.append(sb);
return this;
} private StringBuilder append(StringBuilder sb) {
if (sb == null)
return append("null");
int len = sb.length();
int newcount = count + len;
if (newcount > value.length)
expandCapacity(newcount);
sb.getChars(0, len, value, count);
count = newcount;
return this;
} public StringBuilder append(String str) {
super.append(str);
return this;
}StringBuffer 和 StringBuild的toString()方法
public synchronized String toString() {
return new String(value, 0, count);
} public String toString() {
// Create a copy, don't share the array
return new String(value, 0, count);
}性能测试
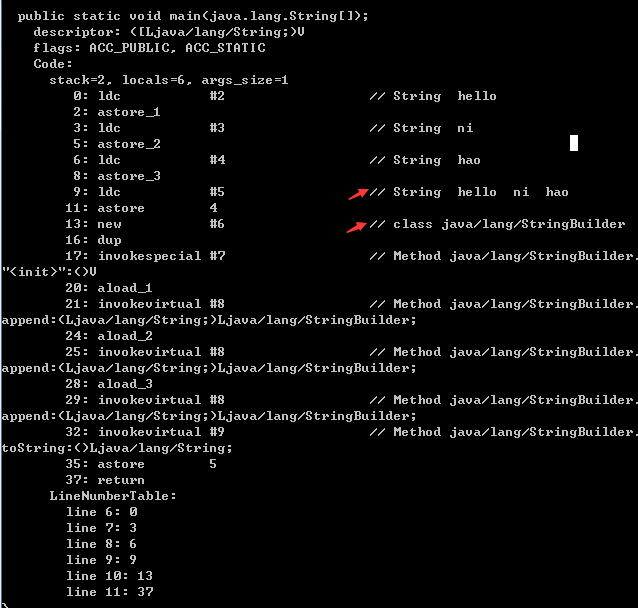
1. 间接相加和直接相加
String a = " hello ";
String b = " ni ";
String c = " hao ";
String str2 = " hello "+ " ni "+ " hao ";
String str1 = a+b+c;编译后:
从反编译的结果看出加号拼接的编译器会直接优化,后面a+b+c的方式则是创建stringbuilder使用append拼接,最后tostring,显然前面的性能更好
2. a+"hello"+"world"方式
String a = " hello ";
String b = " ni ";
String c = " hao ";
String str2 = " hello "+ " ni "+ " hao ";
String str1 = a+" ni "+" hao ";
从反编译结果看,a +" hello " +" world " 也会去创建stringbuilder,append拼接,最后调用tostring创建对象,并没有起到优化的效果

但是如果将a 改为final
final String a = " hello ";
String b = " ni ";
String c = " hao ";
String str2 = " hello "+ " ni "+ " hao ";
String str1 = a+" ni "+" hao ";

3. 比较循环中+和append的效率
public static void main(String[] args) {
run1();
run2();
}
public static void run1() {
long start = System.currentTimeMillis();
String result = "";
for (int i = 0; i < 10000; i++) {
result += i;
}
System.out.println(System.currentTimeMillis() - start);
}
public static void run2() {
long start = System.currentTimeMillis();
StringBuilder builder = new StringBuilder();
for (int i = 0; i < 10000; i++) {
builder.append(i);
}
System.out.println(System.currentTimeMillis() - start);
}
4. stringbuffer,stringbuilder初始化容量
前面有介绍过,stringbuilder,stringbuffer默认容量是16个长度,如果在创建时候,就指定了容量,就避免由于容量不足,创建新的字符数组的开销。
public class Demo3 {
public static void main(String[] args) {
test1();
test2();
}
public static void test1() {
StringBuilder sb = new StringBuilder(7000000);
long start = System.currentTimeMillis();
for (int i = 0; i < 1000000; i++) {
sb.append("jiajun");
}
long end=System.currentTimeMillis()-start;
System.out.println(end);
}
public static void test2() {
StringBuilder sb = new StringBuilder();
long start = System.currentTimeMillis();
for (int i = 0; i < 1000000; i++) {
sb.append("jiajun");
}
long end=System.currentTimeMillis()-start;
System.out.println(end);
}
//输出:18 26
}1. string对象创建的时候,如果使用new创建,会在堆中创建,不管有没有,而引号创建,会在字符串常量池中寻找,找到了,就将引用执行这个对象
2. 字符串直接相加的话,编译器会进行优化,间接相加的话,会创建stringbuilder,在append拼接
3. stringbuffer线程安全,但是牺牲了一些性能,stringbuilder线程非安全,但是在单线程环境下,性能更高
4.stringbuffer,stringbuilder 有默认容量,超出容量时候,会创建新的字符数组,进行复制
转载:http://www.cnblogs.com/-new/p/7417915.html















 85
85

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









