






Profile API
都说要致富先修路,要调优当然需要先监控啦,elasticsearch在很多层面都提供了stats方便你来监控调优,但是还不够,其实很多情况下查询速度慢很大一部分原因是糟糕的查询引起的,玩过SQL的人都知道,数据库服务的执行计划(execution plan)非常有用,可以看到那些查询走没走索引和执行时间,用来调优,elasticsearch现在提供了Profile API来进行查询的优化,只需要在查询的时候开启profile:true就可以了,一个查询执行过程中的每个组件的性能消耗都能收集到。
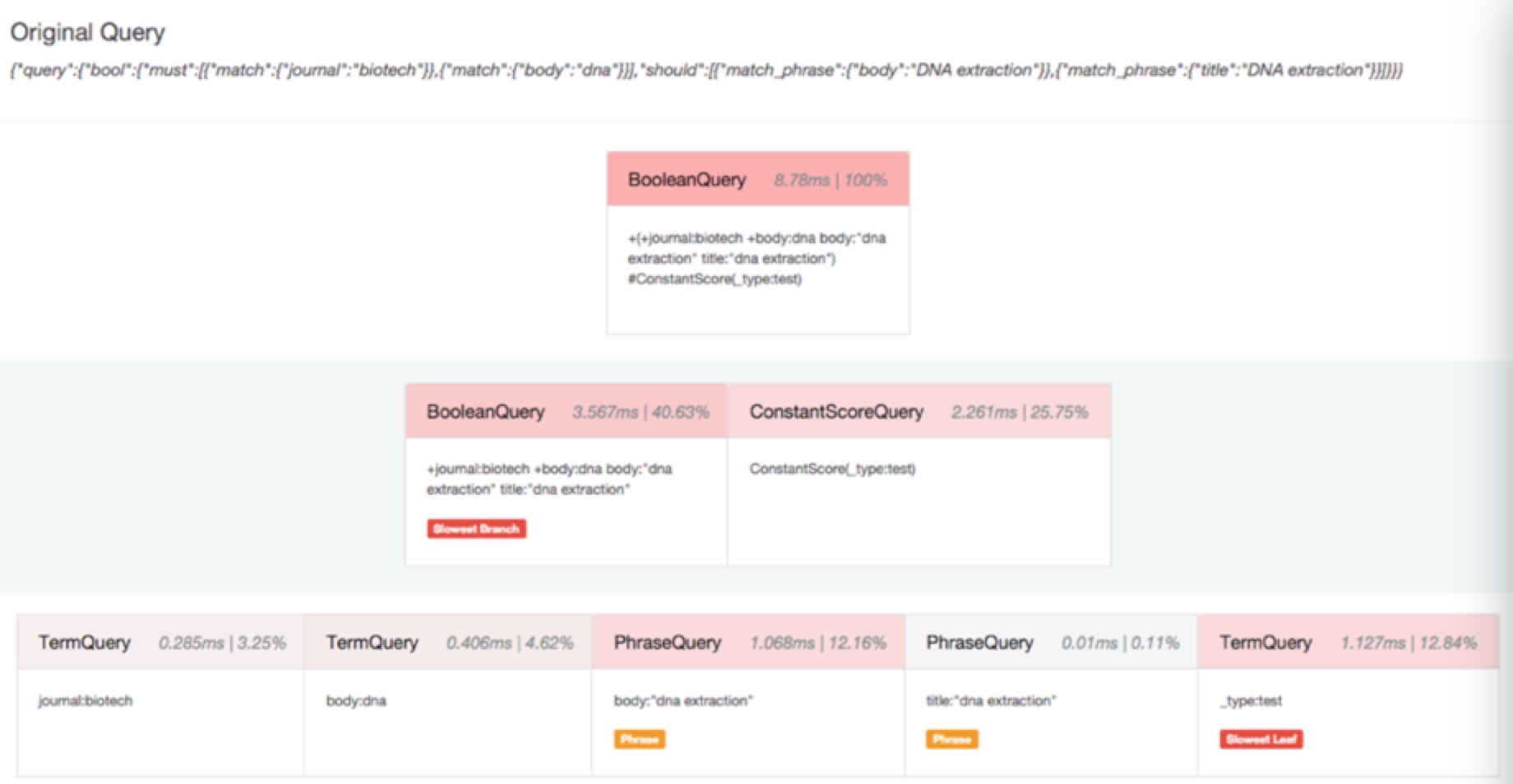
那个子查询耗时多少,占比多少,一目了然,同时支持search和aggregation的profile!
Usage
Any _search request can be profiled by adding a top-level profile parameter:
|
| Setting the top-level |
This will yield the following result:
{
"took": 25,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped" : 0,
"failed": 0
},
"hits": {
"total": 4,
"max_score": 0.5093388,
"hits": [...]
},
"profile": {
"shards": [
{
"id": "[2aE02wS1R8q_QFnYu6vDVQ][twitter][0]",
"searches": [
{
"query": [
{
"type": "BooleanQuery",
"description": "message:some message:number",
"time_in_nanos": "1873811",
"breakdown": {
"score": 51306,
"score_count": 4,
"build_scorer": 2935582,
"build_scorer_count": 1,
"match": 0,
"match_count": 0,
"create_weight": 919297,
"create_weight_count": 1,
"next_doc": 53876,
"next_doc_count": 5,
"advance": 0,
"advance_count": 0
},
"children": [
{
"type": "TermQuery",
"description": "message:some",
"time_in_nanos": "391943",
"breakdown": {
"score": 28776,
"score_count": 4,
"build_scorer": 784451,
"build_scorer_count": 1,
"match": 0,
"match_count": 0,
"create_weight": 1669564,
"create_weight_count": 1,
"next_doc": 10111,
"next_doc_count": 5,
"advance": 0,
"advance_count": 0
}
},
{
"type": "TermQuery",
"description": "message:number",
"time_in_nanos": "210682",
"breakdown": {
"score": 4552,
"score_count": 4,
"build_scorer": 42602,
"build_scorer_count": 1,
"match": 0,
"match_count": 0,
"create_weight": 89323,
"create_weight_count": 1,
"next_doc": 2852,
"next_doc_count": 5,
"advance": 0,
"advance_count": 0
}
}
]
}
],
"rewrite_time": 51443,
"collector": [
{
"name": "CancellableCollector",
"reason": "search_cancelled",
"time_in_nanos": "304311",
"children": [
{
"name": "SimpleTopScoreDocCollector",
"reason": "search_top_hits",
"time_in_nanos": "32273"
}
]
}
]
}
],
"aggregations": []
}
]
}
}
|
| Search results are returned, but were omitted here for brevity |
Even for a simple query, the response is relatively complicated. Let’s break it down piece-by-piece before moving to more complex examples.
First, the overall structure of the profile response is as follows:
{
"profile": {
"shards": [
{
"id": "[2aE02wS1R8q_QFnYu6vDVQ][twitter][0]",
"searches": [
{
"query": [...],
"rewrite_time": 51443,
"collector": [...]
}
],
"aggregations": [...]
}
]
}
}
|
| A profile is returned for each shard that participated in the response, and is identified by a unique ID |
|
| Each profile contains a section which holds details about the query execution |
|
| Each profile has a single time representing the cumulative rewrite time |
|
| Each profile also contains a section about the Lucene Collectors which run the search |
|
| Each profile contains a section which holds the details about the aggregation execution |















 897
897

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









