







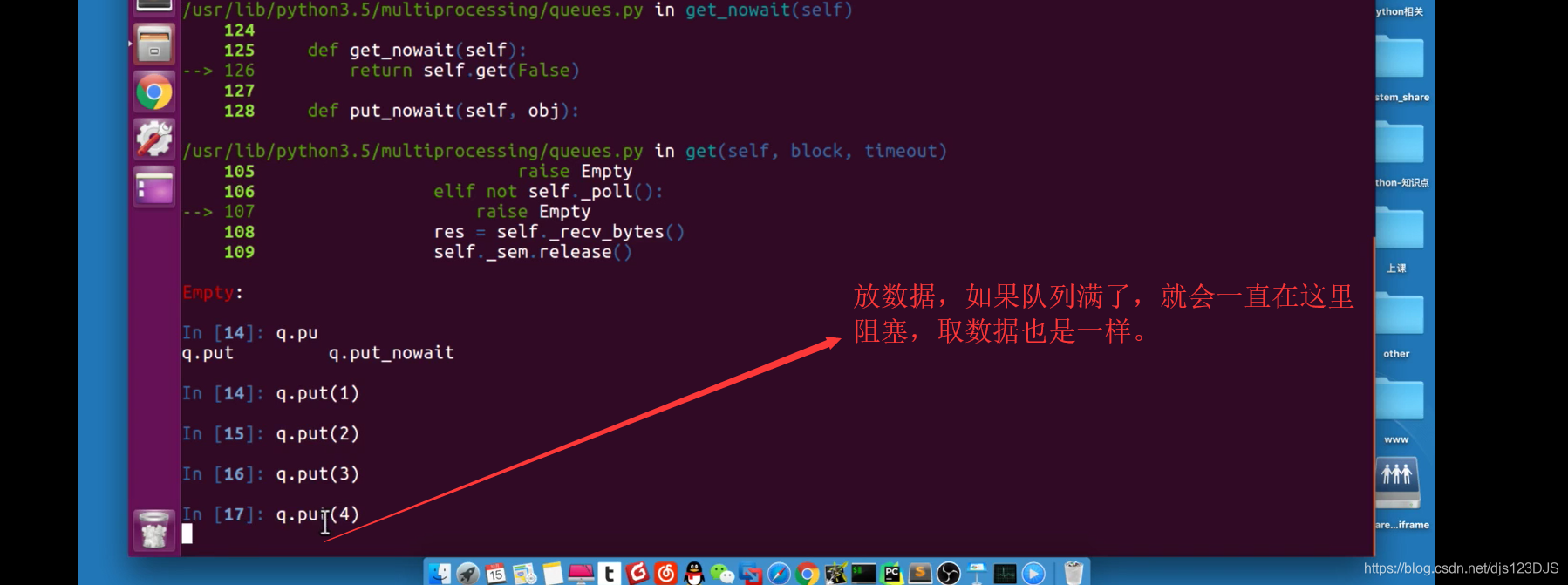
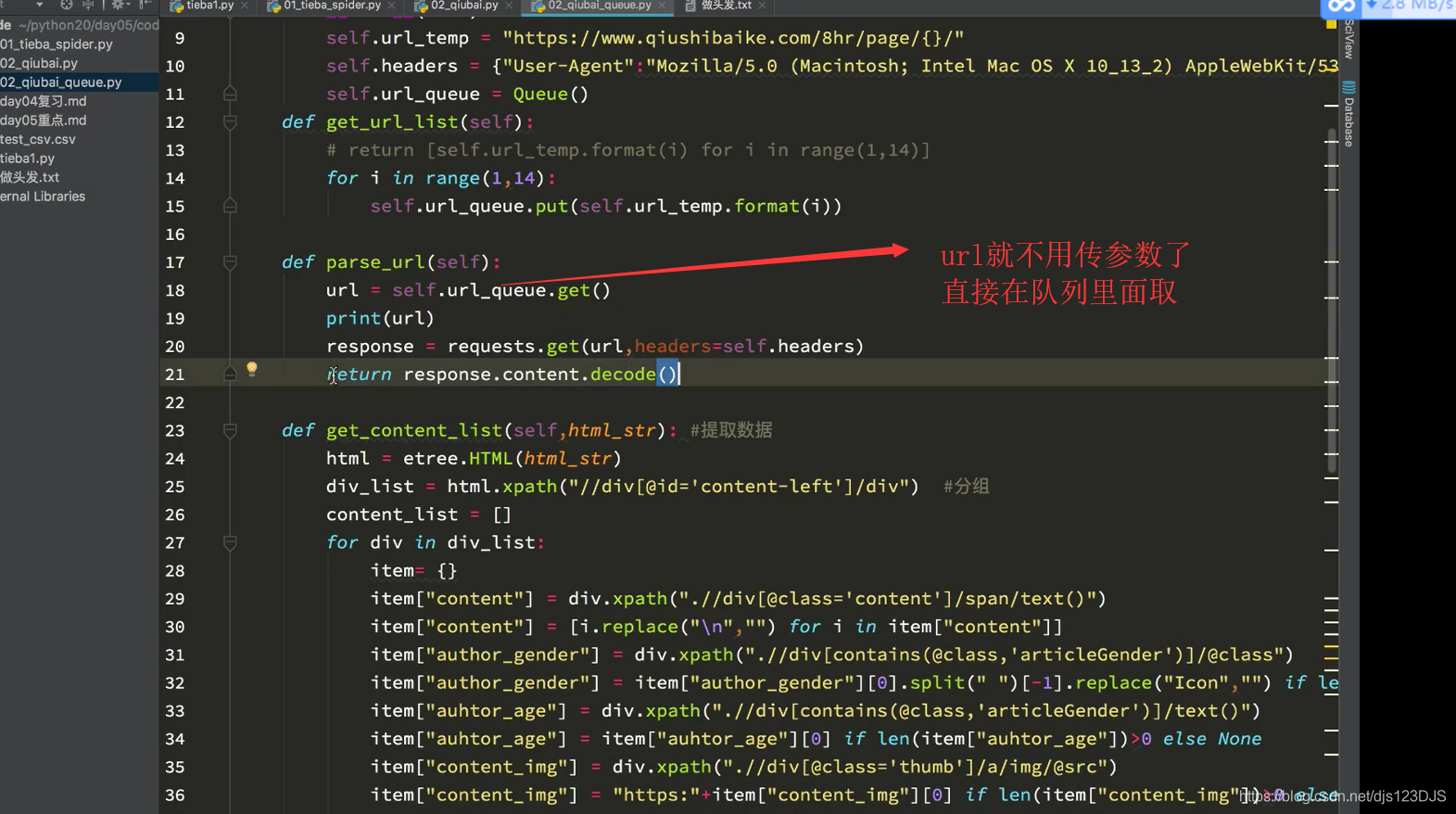
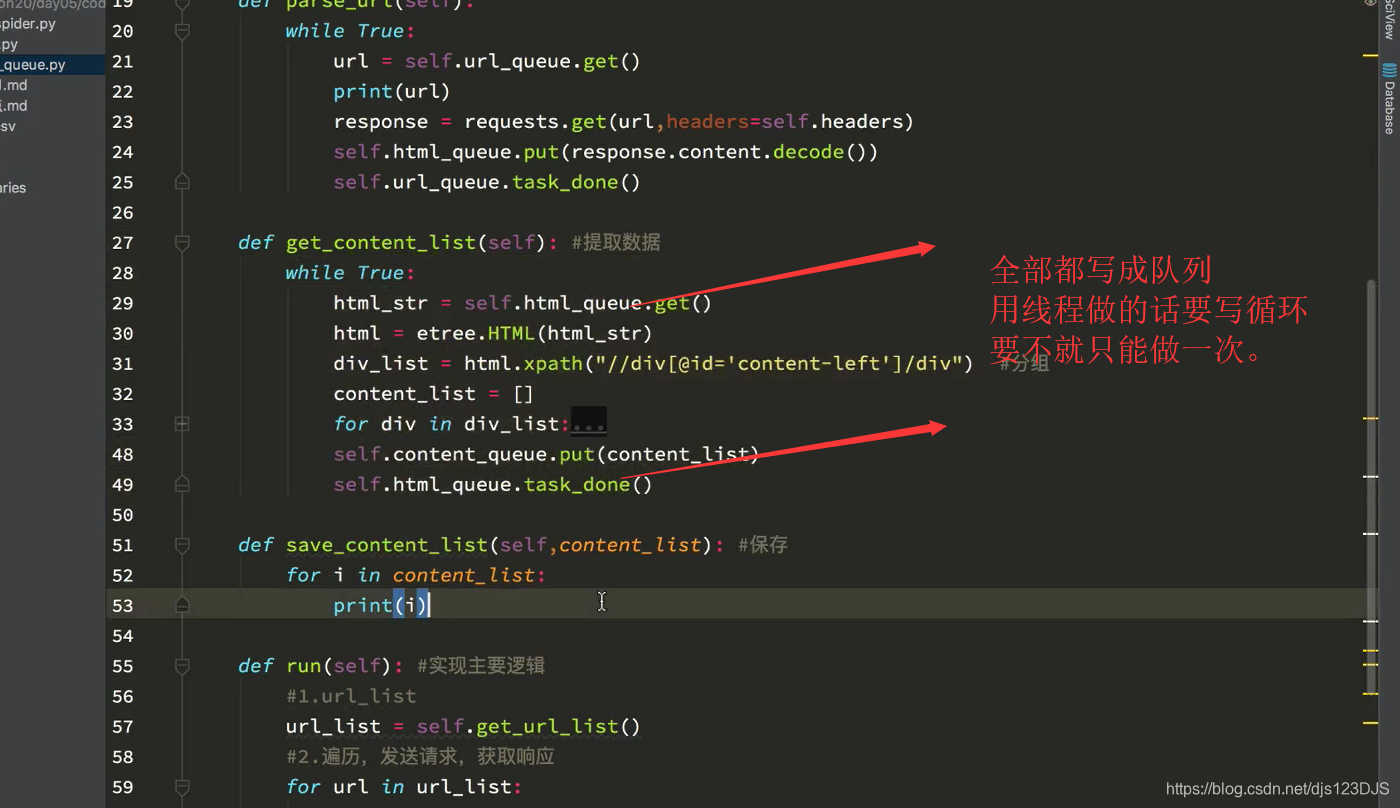
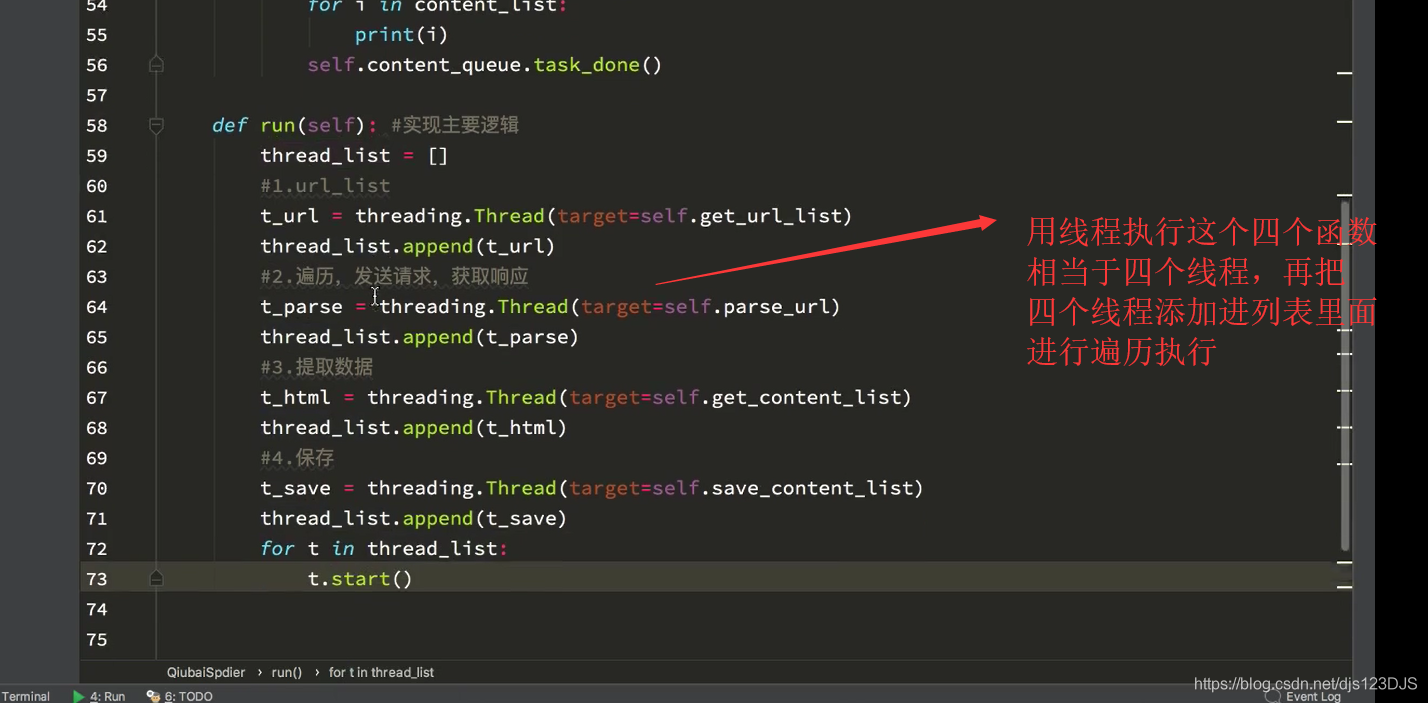
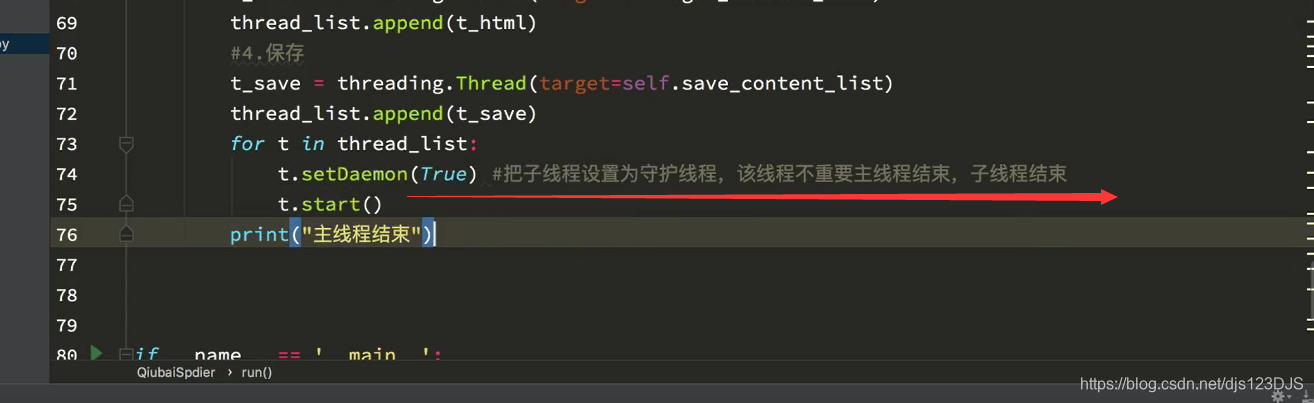
爬虫中的队列能够起到线程安全的作用,比如说一个线程访问队列中的数据的时候,另外一个线程就就能访问了。这样取数据就不会发生数据重复。但是列表就不可以了,列表你一个线程访问列表里面的数据,其他线程也可能会重复访问这个数据,这样拿出来的数据就有可能重复。即是队列中的数据同一时刻只能被一个线程访问,列表中的数据可能同一时刻可能被多个线程访问,造成数据重复,不安全。
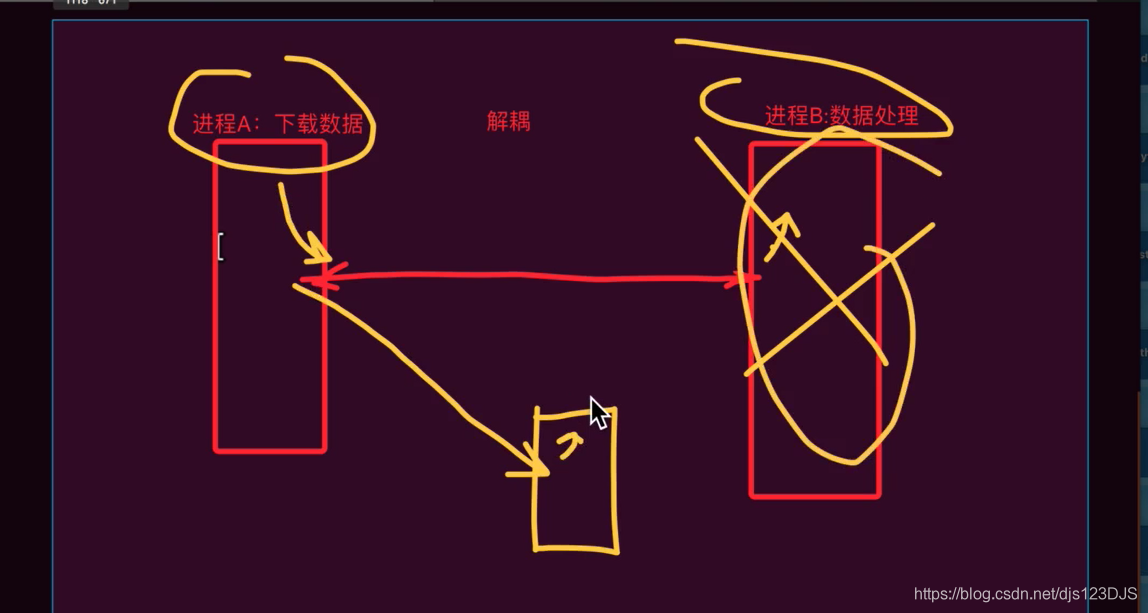
用队列另外一个好处是可以解耦,可以让两个函数耦合性降低,互不影响,一个函数出现问题了,也不会对另外一个函数造成很大的影响。
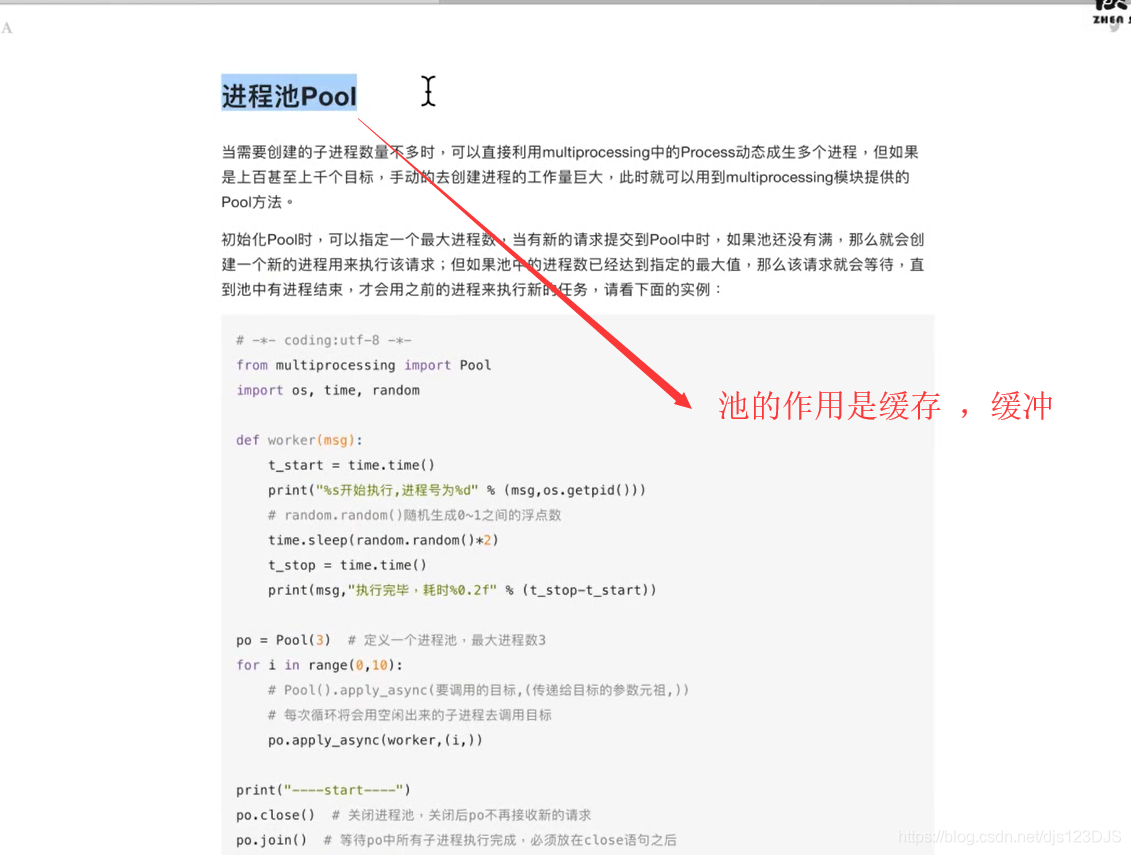
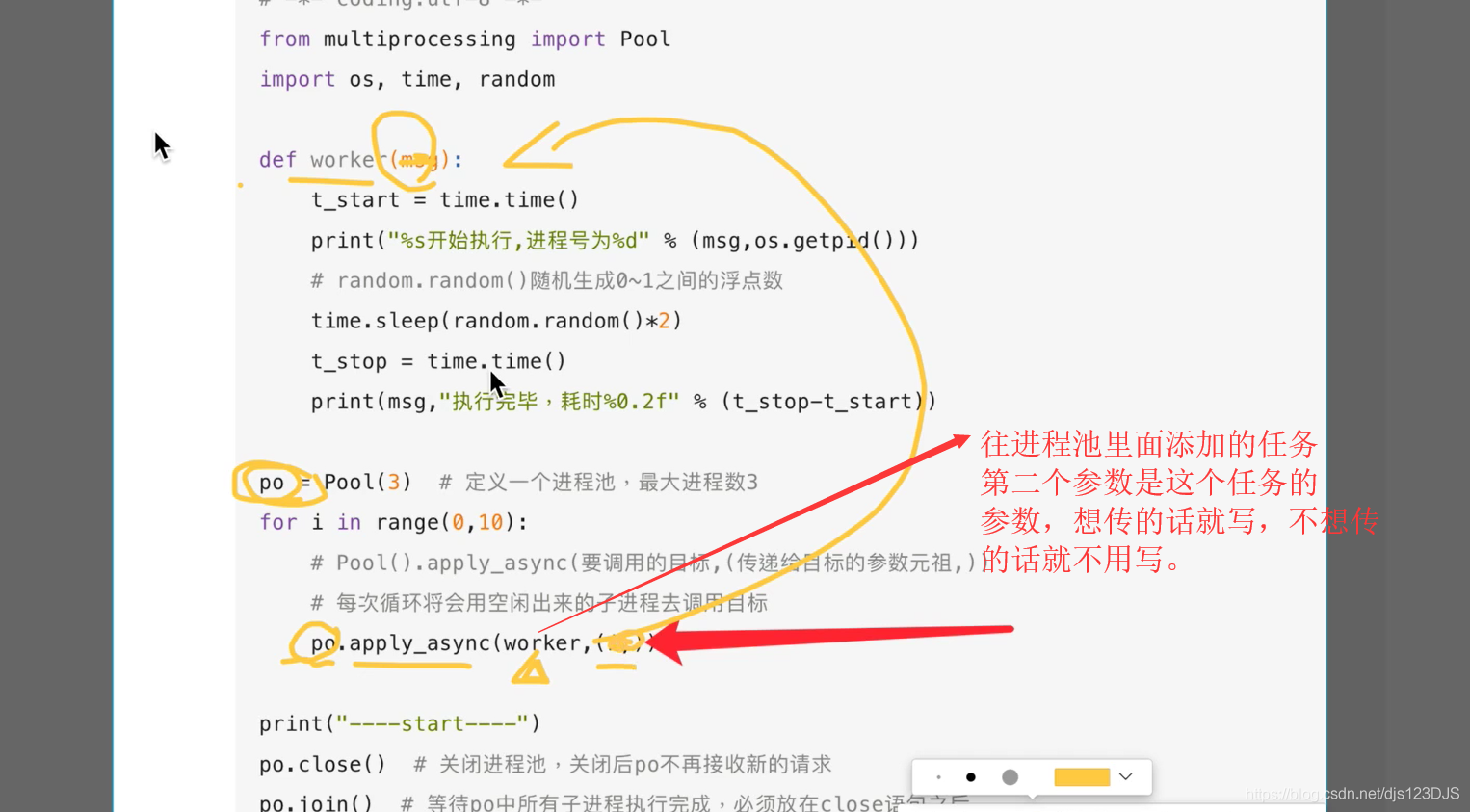
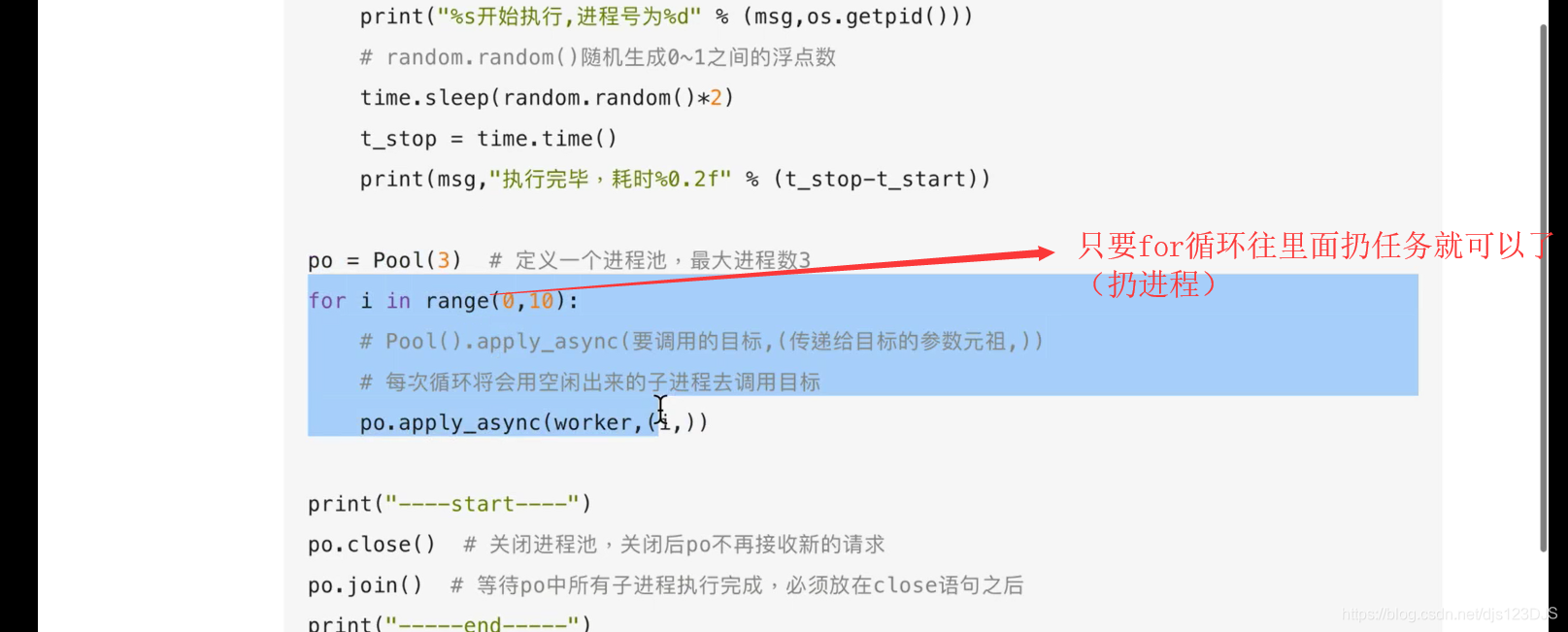
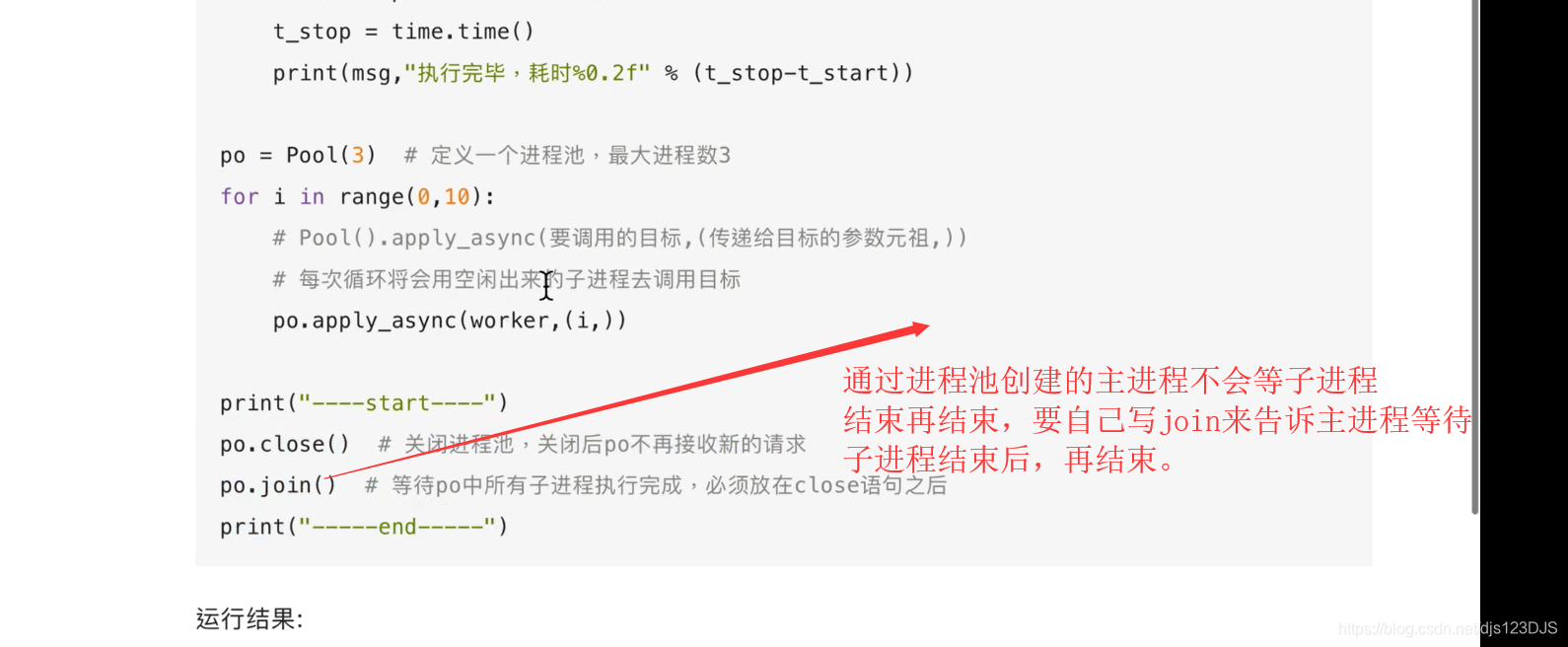
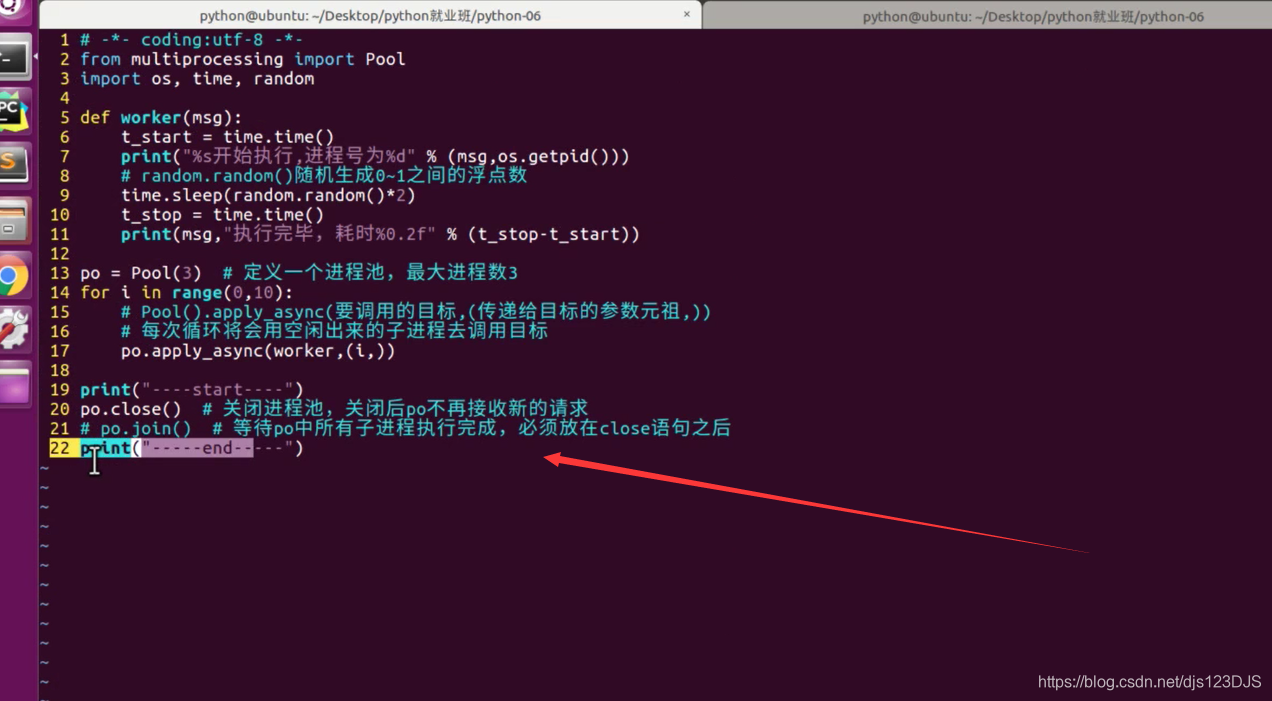
任务量固定用普通的进程,任务数不固定,或者量大,用进程池,进程池会自己管理,能重复利用,不用去管。
def test1():
while True:
print('......')
time.sleep(1)
def test2():
while True:
print('......')
time.sleep(1)
def main():
p1 = multiprocessing.Process(target=test1) #通过multiprocessing模块里面的一个类创建了一个对象
p2 = multiprocessing.Process(target=test2)
p1.start()
p2.start()
##多进程完成队列之间的通信
def download_from_web(q):
#模拟从网上下载数据
data = [11,12,13]
#向队列中写入数
for temp in data:
q.put(temp)
print("已把数据传入到队列中")
def analysis_data(q):
shuju = list() #列表和写[]一样
while True:
data = q.get()
shuju.append(data)
if q.empty():
break
print(shuju)
"""处理数据"""
def main():
#1.创建一个队列
q = multiprocessing.Queue(3) #如果里面不写多少个队列默认是最大,这个看你内存
#2.创建多个进程,将队列的引用当做实参进行传递到里面
p1 = multiprocessing.Process(target=download_from_web,args=(q,)) #把队列当做一个实参传进去
p2 = multiprocessing.Process(target=analysis_data,args=(q,))
p1.start()
p2.start()
##进程池
if __name__ == '__main__':
main()




















 5486
5486











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









