






 该篇文章介绍了一项新的研究,提出MuDI框架解决多对象个性化文本到图像模型中的身份混合问题。通过对象分割、数据增强、初始化策略和模块化定制等方法,MuDI能生成具有明确对象身份的高质量图像。论文还讨论了相关研究和解决思路,并展示了与现有方法的对比效果。
该篇文章介绍了一项新的研究,提出MuDI框架解决多对象个性化文本到图像模型中的身份混合问题。通过对象分割、数据增强、初始化策略和模块化定制等方法,MuDI能生成具有明确对象身份的高质量图像。论文还讨论了相关研究和解决思路,并展示了与现有方法的对比效果。
大家好,今天和大家分享一篇最新的文生图工作,代码已开源
标题:Identity Decoupling for Multi-Subject Personalization of Text-to-Image Models
单位:KAIST
论文:https://arxiv.org/pdf/2404.04243.pdf
代码:https://github.com/agwmon/MuDI
主页:https://mudi-t2i.github.io/

这篇论文在做的一件事是,输入几张包含不同对象的图片(如上面红色框中所示),利用文生图模型(例如SDXL)生成包含输入参考图对象的图片结果,而且能够有效保留输入参考图的身份信息。
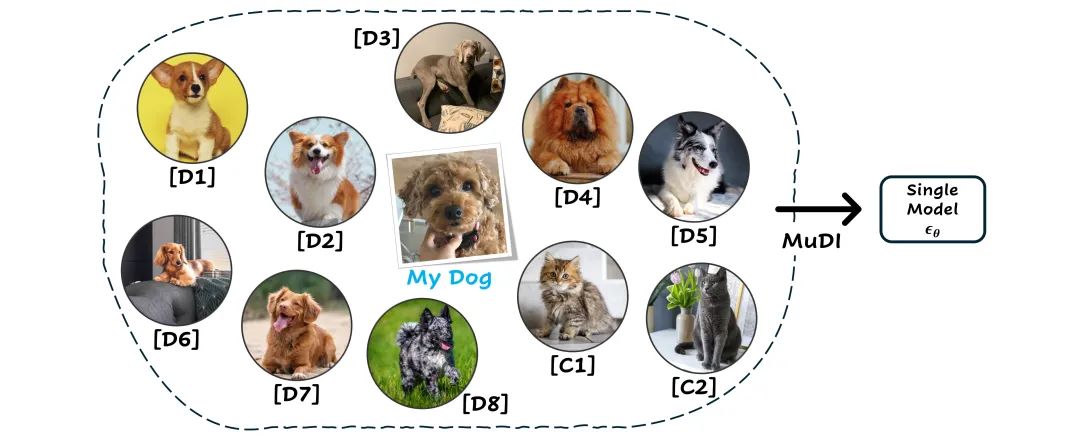
如上图所示,我们可以将不同品种的狗标记为 D1 - D9, 同样的将猫标记为C1-C2,再利用 文生图模型即可生成下面的自定义组合结果:

1、解决的问题
这篇论文试图解决的问题是在多对象个性化文本到图像模型中处理多个对象时,现有方法常常导致不同对象的属性混合,形成混合身份的图像。为了解决这个问题,论文提出了一个名为MuDI(Multi-subject Personalization for Decoupled Identities)的新框架,旨在通过有效地将多个对象的身份解耦来生成高质量的个性化图像,避免身份混合。
论文中提到的关键点包括:
利用分割对象进行数据增强:通过使用Segment Anything Model (SAM) 生成的分割主题来进行训练和推理,作为数据增强的一种形式,以提高模型对不同对象的区分能力。
初始化生成过程:在推理过程中,使用从分割对象生成的均值偏移随机噪声来初始化样本生成,而不是从高斯噪声开始,这为模型提供了有关对象分离的有用提示。
描述性类别的使用:通过使用更具体的类别名称或在一般类别名称前添加详细描述来提高模型对相似对象的区分能力。
相对大小控制:MuDI提供了一种直观的方法来控制个性化主题之间的相对大小,通过在Seg-Mix中调整分割对象的大小来实现。
模块化定制:MuDI的Seg-Mix可以应用于模块化定制,允许独立微调每个对象的模型,然后在不需要从头开始训练的情况下进行有效合并。
LLM引导的推理初始化:使用大型语言模型(LLM)生成与给定提示对齐的布局,以在初始化中定位分割对象,从而增强渲染复杂主题间互动的能力。
2、相关研究
这篇论文提到了多个与多主题个性化文本到图像模型相关的研究领域和具体工作,包括但不限于:
文本到图像的个性化:
Textual Inversion [13]:通过优化新文本嵌入来表示指定的主题。
DreamBooth [39]:通过微调预训练模型的权重来绑定新概念与唯一标识符。
布局引导的多主题组合:
Anydoor [8]:通过重新组合提取的特征在用户指定的场景图像中放置多个概念。
Cones2 [26]:使用用户提供的边界框和交叉注意力图提供的空间引导来组合主题。
ControlNet [53]:通过预设的空间条件(如关键姿势或草图)控制生成过程。
模块化定制:
Custom Diffusion [23]:通过解决约束优化合并独立微调的模型。
Mixof-Show [14]:引入梯度融合来合并单概念LoRAs。
文本到图像扩散模型:
Stable Diffusion XL (SDXL) [34]:作为预训练文本到图像扩散模型使用。
图像编辑和生成:
Segment Anything Model (SAM) [22]:用于自动获取分割主题。
Open Vocabulary Object Detection Model (OWLv2) [28]:用于提取对象边界框。
3、解决思路
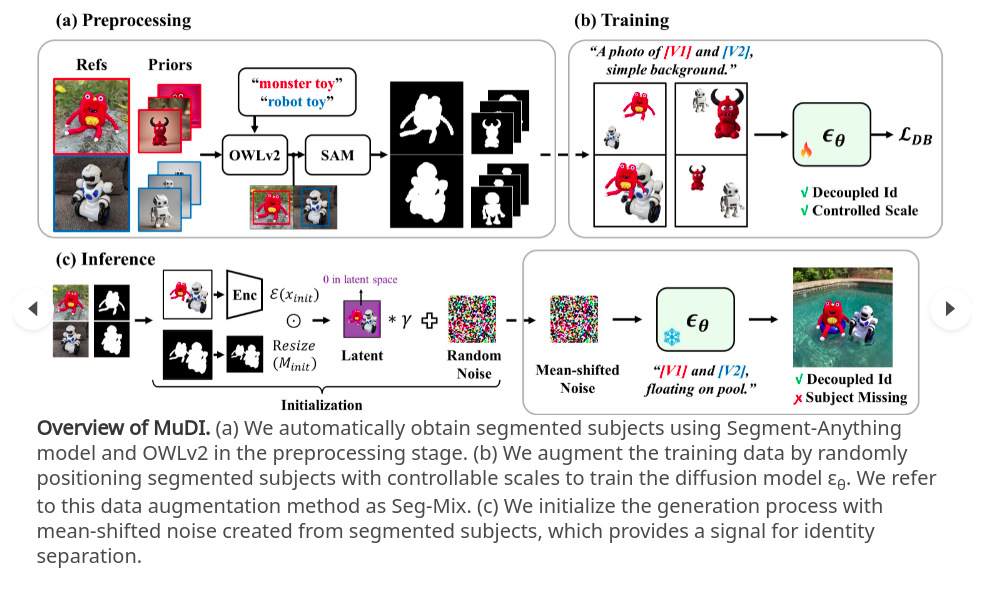
算法的整体框架如上所述:
1、数据预处理:利用SAM + OWLv2(开放词汇的物体检测算法)获取例如 “robot toy” 和对应的一系列不同的mask
2、训练过程:通过随机放置分割好的多个对象,以及调整对象在图片的大小,来增强训练数据,并训练一个扩散模型 (上面的数据增强方案称为:Seg-Mix)
3、推理阶段:初始化生成过程是由分割后的对象创造的mean-shifted noise,利用噪声+标记不同对象的prompt (这里标注的V1和V2)输入到模型即可得到解偶不同身份信息的图像结果

(a) 通过 SMT 控制相对尺寸。使用大小控制的 Seg-Mix 对 MuDI 生成的样本进行可视化。(b) 模块化定制。合并 LoRA 后应用 Seg-Mix 可以显著改善身份解耦。(c) 个性化两个以上的对象。MuDI 可以解耦两个以上的相似对象。(d) MuDI 和 MuDI 对相同随机种子进行迭代训练生成的样本的比较。迭代训练改善了身份解耦,KL 正则化缓解了过饱和。
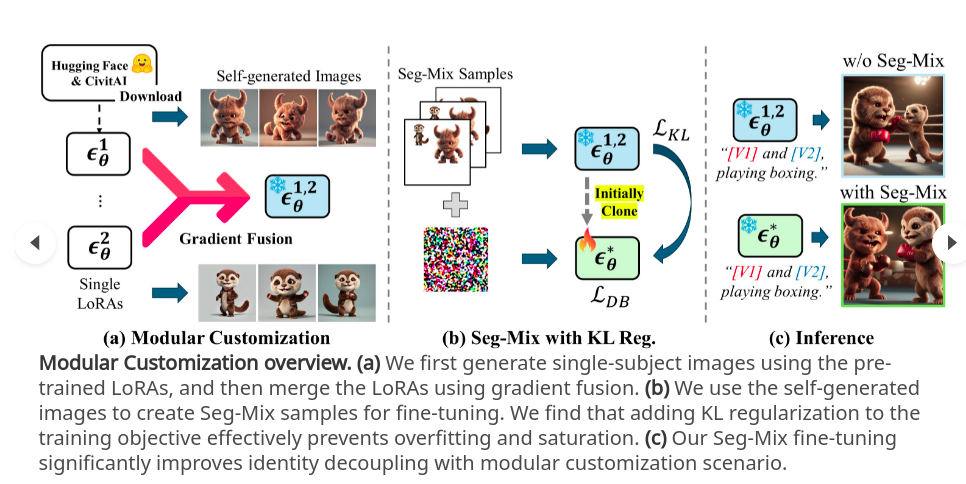
Modular Customization overview。(a) 首先使用预先训练的 LoRA 生成单对象图像,然后使用梯度融合合并 LoRA。(b) 使用自生成的图像来创建 Seg-Mix 样本以进行微调。我们发现将 KL 正则化添加到训练目标中可以有效防止过度拟合和饱和。(c) Seg-Mix 微调显著改善了模块化定制场景的身份解耦。
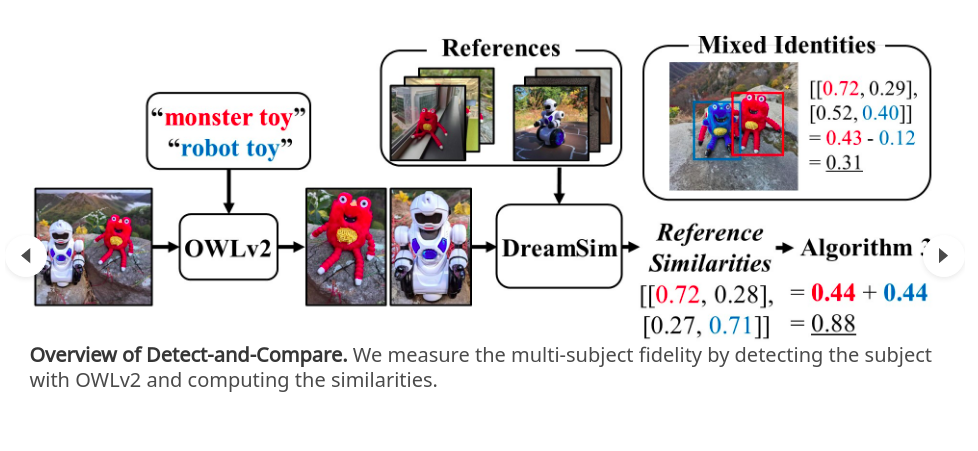
检测和比较概述。通过使用 OWLv2 检测对象并计算相似度来测量多对象保真度。
4、效果展示
来自Sora的素材测试:



与现有方法效果对比:























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









