






线性回归
线性回归介绍
[理解] 线性回归
线性回归是利用回归方程(函数)对一个或多个自变量(特征值)和因变量(目标值)之间关系进行建模的一种分析方式
注意事项:
1 为什么叫线性模型?因为求解的w,都是w的零次幂(常数项)所以叫成线性模型
2 在线性回归中,从数据中获取的规律其实就是学习权重系数w
3 某一个权重值w越大,说明这个权重的数据对房子价格影响越大\
[知道]线性回归分类
一元线性回归
y = kx+b
目标值只与一个因变量有关系
多元线性回归
y = w1x1 + w2x2 + w3x3 + ... + b
目标值只与多个因变量有关系
[掌握]损失函数
需要设置一个评判标准
误差概念: 用预测值y-真实值y就是误差
损失函数: 衡量每个样本预测值与真实值效果的函数
损失函数就是关于k, b的函数,展开会变成二元二次方程
为简化计算,先固定截距b,x=0时, b可设置成一个负值,b固定成-100
当损失函数取最小值时,得到k就是最优解
想要一条直线更好的拟合所有点 y = kx + b
* 引入损失函数(衡量预测值和真实值效果)Loos(k,b)
* 通过一个优化方法,求损失函数最小值, 得到k最优解
回归的损失函数
导数和矩阵
[知道]常见的数据表述
*为什么要学习标量, 向量, 矩阵,张量?
因为机器学习, 深度学习中经常用, 不要因是数学就害怕
宗旨:用到什么就学什么,不要盲目展开,大篇幅学数学
*标量scalar: 一个独立存在的数,只有大小没有方向
*向量vector: 向量值一列顺序排列的元素.默认是列向量
*矩阵matrix: 二维数组
*张量Tensor: 多维数组,张量是基于向量和矩阵的推广
[知道]导数
当函数 y=f(x)的自变量x在一点 X上产生一个增量Δx时,函数输出值的增量Ay与自变量增量Ax的比值在Ax趋于0时的极限A如果存在,A即为在X处的导数,记作f'(Xo)
函数 y=f(x)在点x,处的导数的几何意义,就是曲线y=f(x)在点P(x。,f(x,))处的切线的斜率,即曲线y=f(x)在点P(x。,f(x,))处的切线的斜率是f(x)
导数是函数的局部性质. 一个函数在某一点的导数描述了这个函数在这一点附近的变化率
函数在某一点的导数就是该函数所代表的曲线在这一点的切线斜率
复合函数求导:g(h)是外函数 h(x)是内函数。先对外函数求导,再对内函数求导
导数求极值:
导数为0的位置是函数的极值点
[知道]偏导
U是关于x、y、z的函数,记为u(x, y, z),只在x分量上求导,则为求偏导。
• 各个分量上求偏导,会形成一个向量这就组成了导数
[知道]向量

[知道]矩阵
矩阵是数学中的一种基本概念,表达m行n列的数据等
矩阵在机器学习中的表达

矩阵加法和减法
![]()
矩阵乘法:对应行列元素相乘,然后再加和在一起
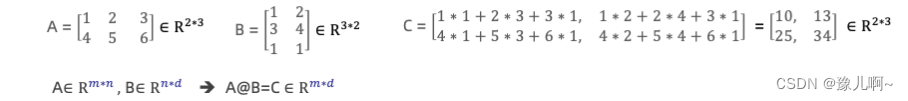
矩形转置
![]()
矩阵@矩阵转置
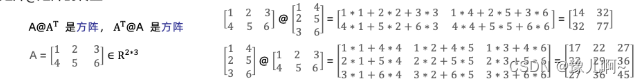
方阵 :一种特殊的矩阵,其行数=列数
对方阵: 一种特殊的方阵, 沿住对角线,其元素对称
单位阵: 一种特殊的方阵 符号E或者I
对角线为1, 其他为0
矩阵乘法的性质
矩阵的乘法不满足交换律: A×B不等于B×A
特殊条件下满足: AB=BA 的前提是A.B是同阶方阵
矩阵的乘法满足结合律.即: A× (B×C) = (A ×B) ×C
矩阵与单位矩阵相乘等于矩阵本身
矩阵的逆
![]()
矩阵转置的性质

梯度下降算法
[掌握]梯度下降算法思想
什么是梯度
单变量函数中, 梯度就是某一点切线斜率(某一点的导数);有方向为函数增长最快的方向
多变量函数中,梯度就是某一个点的偏导数; 有方向:为函数增长最快的方向
梯度下降公式

梯度下降优化过程
1.给定出位置,步长(学习率)
2.计算该店当前的梯度负方向
3.向该负方向移动步长
4.重复 2-3 收敛
两次差距小于指定的值
打到指定的迭代次数
梯度下降公式中,为什么梯度要乘以一个负号
梯度的方向实际就是函数在此点上升最快的方向!
余姚朝着下降最快的方向走,负梯度方向,所以加我张负号
有关学习率步长
1步长也定了再梯度下降迭代的过程中,每一步沿梯度负方向前进的长度
2.学习效率太小,下降的速度会慢
3.学习效率太大.容易造成错过最低点.产生下降过程中的震荡.甚至梯度爆炸
[了解]梯度算法分类
全梯度下降算法 FGD
每次迭代时,使用全部样本的梯度值

随机梯度下降算法 SGD
每次迭代时,随机选择并使用一个样本梯度值
![]()
小批量梯度下降算法 mini-bantch
每次迭代时,随机选择并使用小批量的样本梯度值
从m个样本中,选择x个样本进行迭代(1<x<m)

随机平均梯度下降算法 SAG
每次迭代时, 随机选择一个样本的梯度和以往样本的梯度值的平均值
1.随机选择一个样本,假设原则 D样本,计算其梯度值并存储到列表: [D],然后使用列表中的梯度平均值,更新模型参数
2.随机再选择一个样本,假设又选择了 G 样本,计算其梯度值并存储到列表:[D,G], 然后使用列表中的梯度值均值,更新模型参数.
3.随机再选择一个样本的梯度值,假设又选择了D样本,重新计算该样本梯度值,并更新列表中D样本的梯度值,使用列表中梯度值均值,更新模型参数.
4....以此类推, 直到算法收敛
![]()
全体度下降算法 FGD
由于使用全部数据集,训练速度较慢
随机梯度下降算法 SGD
简单,高效,不稳定.SG每次只使用一个样本迭代,若遇上噪声则容易陷入局部最优解
小批量梯度下降算法 minni-bantch
结合了SG的胆大和FG的心细,它的表现也正好居于 SG 和 FG 二者之间
目前使用最多,正式因为它避开了FG运算效率低成本和 SG 瘦脸效果不稳定的特点
随机平均梯度下降算法 SAG
训练初期表现不佳,优化速度较慢.这是因为我们常将初始梯度设为0,
而SAG每轮梯度更新都结合了上一轮梯度值
目前使用较多的是: 小批量梯度下降
[理解]正规方程和梯度下降算法的对比
梯度下降
需要选择学习效率
需要迭代求解
特征数量较大可以使用
应用场景: 更加普适,迭代的计算方式,适合于嘈杂,大数据应用场景
注意: 梯度下降在各个损失函数(目标函数) 求解中大量使用.深度学习中更是如此,深度学习模型参数很轻松就上亿,只能通过迭代的方式求最优解
正规方程
不需要学习率
一次运算得出,一蹴而就
应用场景:小数据量场景,精准的数据场景
缺点: 计算量打,容易受到噪声,特征强相关性的影响
注意: 计算XTX的逆矩阵非常耗时
如果数据规律不是线性的,无法使用或效果不好
回归评估方法
为什么要进行线性回归模型的评估
我们希望衡量预测值和真实值之间的差距
会用到MAE,MSE,RMSE多种测评函数进行评价
[知道]平均绝对误差
上面的公式中:n为样本数量,y为实际值.y^为预测值
MAE越小模型预测越准确
SKlearn中MSE的API
from sklearn.metrics import mean_squared_error
mean_squared_error(y_test,y_predict)
[知道]均方误差
上面的公式中: n为样本数量,y为实际值,y^为预测值
MSE越小模型预测越准确
Sklearn 中MSE的API:
from sklearn.metrics import mean_squared_error
mean_squared_error(y_test,y_predict)
[知道]均方根误差
上述的公式中: n 为样本数量.y为实际值,y^为预测值
RMSE 越小模型预测越准确
[了解]三种指标的比较
假设数据中有少数异常偏差很大,如果此时根据 RMSE 选择性回归模型,可能会选出过拟合的模型阿里
在这种情况下,由于数据中的异常点极少,选择具有最低 MAE 的回归模型可能更合适
除此之外, 当两个模型计算REMSE时数据量不一致,也不适合在一起比较
正则化
[理解]欠拟合与过拟合
过拟合:一个假设在训练数据上能够获得比其他假设更好的拟合,但是在测试数据集上却不能很好地拟合数据(体现在准确率下降),此时认为这个假设出现了过拟合的现象,(模型过于复杂)
欠拟合: 一个假设 在训练数据上不能获得更好的拟合,并且在测试数据集上也不能很好地拟合数据,此时认为这个假设出现了欠拟合的现象.(模型过于简单)
过拟合和欠拟合的区别:
欠拟合在训练集和测试集上的误差都较大
过拟合在训练集上误差较小,而测试集上误差较大
[理解] 原因以及解决方法
欠拟合产生的原因:学习到数据的特征过少
解决办法
1.添加其他特征项,有时出现欠拟合是因为特征项不够导致,可以添加其他特征来解决
2.添加多项式特征,模型过于简单时的常用套路,例如将线性模型通过添加二次项或三次项使模型繁华能力更强
过拟合产生原因:原始特征过多,存在一些嘈杂特征,模型过于复杂是因为模型尝试去兼顾所有测试样本
解决办法:
1.重新清洗数据, 导致过拟合的原因有可能是数据不纯,如果出现了过拟合就需要重新清洗数据
2.增大数据的训练量,还有一个原因就是我们用于训练的数据量太小导致的,训练数据占总数据的比例过小
3.正则化
4,较少特征维度
[理解]正则化
在解决回归拟合中,我们选择正则化.但是对于其他机器学习算法如分类算法来说也会出现这样的问题,除了一些算法本身作用之外(决策树,神经网络),我们更多的也是去自己做特征选择,包括之前说的删除,合并一些特征
尽量减小高次项特征的影响
在学子的时候,数据提供的特征有些影响模型复杂度或者这个特征的数据点异常较多,所以算法在学习的时候尽量减小这个特征的影响(甚至删除某个特征的影响),这就是正则化
注: 调整的时候,算法并不知道某个特征影响,而是去调整参数得住优化的结果
L1正则化
作用:用来进行特征选择,主要原因在于L1正则化会使得较多的参数为0,从而产生稀疏解,可以将0对应的特征遗弃,进行用来选择特征.一定程度上L1正则也可以防止模型过拟合
L2正则化
假设𝐿(𝑊)是未加正则项的损失,𝜆是一个超参,控制正则化项的大小。
作用:主要用来防止模型过拟合,可以减小特征的权重
优点:越小的参数说明模型越简单,越简单的模型则越不容易产生过拟合现象















 1938
1938

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









