





分类判别任务必然是面向特定任务或特定代价的。分类的目的在于重建我们所感知到的模式的内在模型。获得一个好的模式表达,是几乎所有模式识别中的一个中心任务。模式分类不同于“图像处理”,在图像处理中,输入的是一副图像输出的也是一副图像。图像处理的步骤常包括图像旋转,对比增强和其他能保持所有原始信息的图像变换。而特征提取,比如检测出图像中的峰谷点,边缘点等。特征提取输入模式,输出特征值。决策在模式判别信息中至关重要,它的本质是一个信息压缩的过程。
回归分析,函数内插,(概率)密度估计也经常用到模式识别中。
在回归(regression)分析中,我们的目的是对输入数据找到合适的函数表示,常用于预测新数据的值。线性回归,其中的函数形式对输入数据而言是线性的,
在函数内插(interpolation)中,我们已知的是一定范围内的输入数据对应的函数值,而要解决的问题是如何求出这些输入点之间的数据点的函数值。
密度函数估计(density estimation)用于求解具有某种特定特征的类别成员(样本)出现的(概率)密度问题。
模式识别系统:
模式识别系:
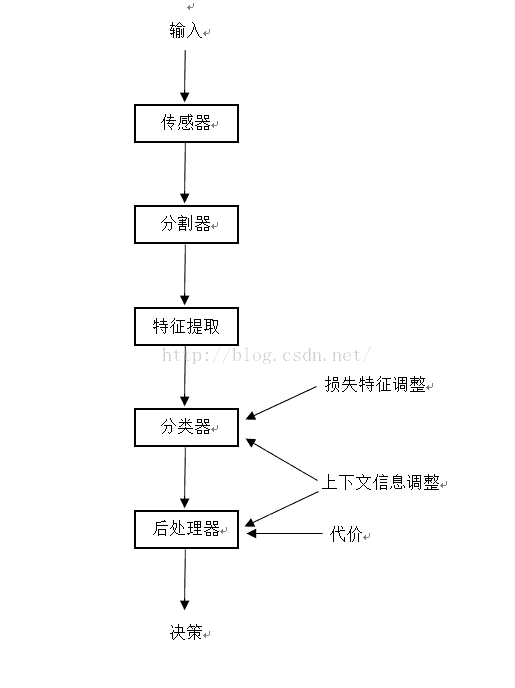
传感器:摄像机等。
分割:就是将所需要的物体在图像中分割出来,只对其做处理。
特征提取:要提取最有鉴别能力的特征,这些类别特征对于类别不相关的变换具有不变性,理想情况下,特征应该是平移不变的,旋转不变的,尺度不变的。
分类器作用:根据特征提取器得到的特征向量累给一个北侧对象赋予一个类别标记。最简单的分类器性能度量是分类误差率,就是新模式被判别为错误类别的百分比。
噪声的概念:如果一个感知到的模式的属性并非来自真正模式的模型,而是来自环境中的某种随机性或者是传感器的性能缺憾,这就是噪声。
设计循环:
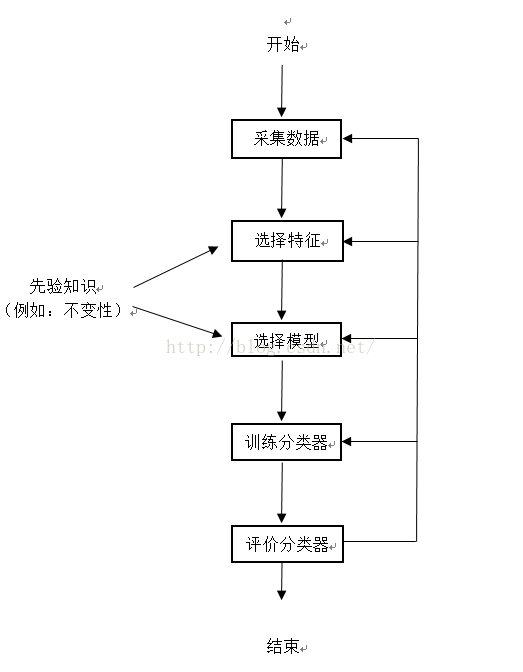
尽管一个过分复杂的系统单纯对训练样本集能获得完美的表现,但对于新样本则可能不令人满意。这种观察到的现象称为“过拟合(overfitting)”。
学习算法的形式:
有监督学习:在有监督学习中,存在一个教师信号,对训练样本集中的每个输入样本能提供分类标记和分类代价,并寻找能够降低总体代价的方向。
无监督学习:系统对输入的样本自动形成聚类或自然地组织。
强化学习:给定一个输入样本,计算他的输出类别,把它与已知的类别标记做比较,根据差异来改变分类器的性能。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









