






最近准备接触分布式计算,学习分布式计算的技术栈和架构知识。目前的分布式计算方式大致分为两种:离线计算和实时计算。在大数据全家桶中,离线计算的优秀工具当属Hadoop和Spark,而实时计算的杰出代表非Flink莫属了。Hadoop算是分布式计算的鼻祖,又是用Java代码实现,我们就以Hadoop作为学习分布式计算的入门项目了。
目录
一、环境
二、创建Hadoop用户
1. 设置密码
2. 增加管理员权限
三、配置SSH免密登录
四、hosts配置主机名
五、安装JDK环境
六、安装Hadoop
1. 下载Hadoop
2. 配置Hadoop环境变量(Master节点)
1)配置环境变量
2)配置core-site.xml
3)配置hdfs-site.xml
4)配置mapred-site.xml
5)配置yarn-site.xml
6)配置masters文件
7)配置slaves文件(Master特有)
3. 配置Hadoop环境变量(Slave节点)
1)复制hadoop到node02节点
2)配置环境变量
七、启动集群
1. 格式化HDFS文件系统
2. 启动Hadoop
3. 使用jps命令查看运行情况
4. 命令查看Hadoop集群的状态
5. WEB查看Hadoop集群的状态
6. 关闭Hadoop
一、环境
三台服务器配置:CPU:4核,内存:8G,硬盘:150G,带宽:5M
三台服务器规划:node01作为主节点Master,node02和node03作为从节点Slave
操作系统:Ubuntu 16.04,需要配备ssh远程登录工具,若没有安装ssh工具,请自行安装
Hadoop版本:Hadoop 2.9.2
二、创建Hadoop用户
想安装Hadoop 那么需要创建一个Hadoop 用户,毕竟创建一个新的用户,配置环境相对更加干净一些。当然,使用已有的用户也是没问题的。为了快速搭建,我跳过了这步,直接使用root用户搭建集群。
那么打开终端,输入下面的命令创建新的用户:
$sudo useradd -m hadoop -s /bin/bash
创建一个hadoop用户,并使用/bin/bash作为shell。
1. 设置密码
然后,接着上面的操作, 再对这个用户设置密码,可以简单设置为 hadoop(可以设置成你想设置的),注意两次设置为相同的密码。
$sudo passwd hadoop
2. 增加管理员权限
为了我们后续的操作方便。我们这里对之前添加的Hadoop 用户添加管理员的权限。
$sudo adduser hadoop sudo
这样我们就成功的设置了该用户的管理员权限。
最后我们用Hadoop用户登录我们的电脑了,所以我们注销当前用户,注销后,在登录的界面中使用刚刚创建的Hadoop 用户登录。
三、配置SSH免密登录
可参考之前的一篇博文:Linux SSH免密登录,在此就不再赘述了。
四、hosts配置主机名
修改node01的hosts文件
# vi /etc/hosts
#127.0.0.1 localhost.localdomain VM-0-14-ubuntu #127.0.0.1 localhost 172.17.0.14 node01 172.17.0.17 node02 172.17.0.4 node03
注意:注释127.0.0.1的主机名映射,避免后续集群启动后DataNode无法连接NameNode的9000端口。
然后同步修改node02和node03的hosts文件
# scp /etc/hosts node02:/etc # scp /etc/hosts node03:/etc
五、安装JDK环境
如果你之前的电脑中安装了Java环境,并配置好了环境变量,那么这一步就可以直接跳过。
当然,这里不会去重点讲如何在Linux上安装Java, 网上有很多教程,如果你的Linux中还没有Java环境,那么就直接参考网上的教程, 同时在 /etc/profile 中配置好环境变量。
环境变量配置好后,可以执行 echo $JAVA_HOME 或者 java -version ,查看是否是自己安装的Java路径以及相应的版本。以上安装配置好了之后,就可以安装Hadoop了。
六、安装Hadoop
1. 下载Hadoop
Hadoop安装包可以从官网下载:https://hadoop.apache.org/releases.html
一般选择下载最新的release版本,即下载hadoop-2.x.y.tar.gz 这个格式的文件,这是编译好的,另一个包含 src 的则是 Hadoop 源代码,需要进行编译才可使用。这里我下载稳定版本的2.9.2。
下载好了之后,在你想安装的路径下进行解压, 这里选择将Hadoop 安装到/data(是一块数据盘的挂载路径)路径下:
# tar -xvzf hadoop-2.9.2.tar.gz -C /data # 解压到/data中 # cd /data/ # mv ./hadoop-2.9.2/ ./hadoop # 将文件夹名改为hadoop
注意:由于Master节点和Slave节点有些许差异,接下来的说明将会指定是Master节点或Slave节点!
2. 配置Hadoop环境变量(Master节点)
1)配置环境变量
# vi /etc/profile
export HADOOP_HOME=/data/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
使得hadoop命令在当前终端立即生效
# source /etc/profile
接下来的配置,文件都在 /data/hadoop/etc/hadoop/ 路径下
2)配置core-site.xml
修改Hadoop核心配置文件 /usr/local/hadoop/etc/hadoop/core-site.xml ,通过 fs.default.name 指定NameNode的IP地址和端口号,通过 hadoop.tmp.dir 指定hadoop数据存储的临时文件夹。
<configuration> <property> <name>hadoop.tmp.dir</name> <value>/data/hadoop/cellphone/tmp</value> <description>Abase for other temporary directories.</description> </property> <property> <name>fs.defaultFS</name> <value>hdfs://node01:9000</value> </property> <property> <name>hadoop.http.staticuser.user</name> <value>root</value> </property> </configuration>
注意:如没有配置 hadoop.tmp.dir 参数,此时系统默认的临时目录为:/tmp/hadoo-hadoop。而这个目录在每次重启后都会被删除,必须重新执行format才行,否则会出错。
3)配置hdfs-site.xml
修改HDFS核心配置文件 /usr/local/hadoop/etc/hadoop/hdfs-site.xml ,通过 dfs.replication 指定HDFS的备份因子为3,通过 dfs.name.dir 指定NameNode节点的文件存储目录,通过 dfs.data.dir 指定DataNode节点的文件存储目录。
<configuration> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/data/hadoop/cellphone/tmp/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/data/hadoop/cellphone/tmp/dfs/data</value> </property> <property> <name>dfs.datanode.http.address</name> <value>0.0.0.0:50075</value> </property> </configuration>
4)配置mapred-site.xml
拷贝mapred-site.xml.template为mapred-site.xml,再进行修改
# cp mapred-site.xml.template mapred-site.xml # vi mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
5)配置yarn-site.xml
<configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.resourcemanager.hostname</name> <value>node01</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>node01:9088</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>node01:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>node01:8030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>node01:8031</value> </property> <property> <name>yarn.resourcemanager.admin.address</name> <value>node01:8033</value> </property> </configuration>
6)配置masters文件
修改 $HADOOP_HOME/etc/hadoop/masters 文件(如果没有就新增),该文件指定NameNode节点所在的服务器机器。删除localhost,添加NameNode节点的主机名node01;不建议使用IP地址,因为IP地址可能会变化,但是主机名一般不会变化。
# vi masters ## 内容 node01
7)配置slaves文件(Master特有)
修改 $HADOOP_HOME/etc/hadoop/slaves 文件,该文件指定哪些服务器节点是DataNode节点。删除locahost,添加所有DataNode节点的主机名
# vi slaves
## 内容
node02
node03
3. 配置Hadoop环境变量(Slave节点)
1)复制hadoop到node02节点
# scp -r /data/hadoop node02:/data
登录node02节点,删除slaves内容
# rm /data/hadoop/etc/hadoop/slaves
2)配置环境变量
# vi /etc/profile
export HADOOP_HOME=/data/hadoop export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
使得hadoop命令在当前终端立即生效
# source /etc/profile
依次配置其它slave节点
# scp /etc/profile node03:/etc
七、启动集群
1. 格式化HDFS文件系统
进入node01(Master)的hadoop目录,执行以下操作
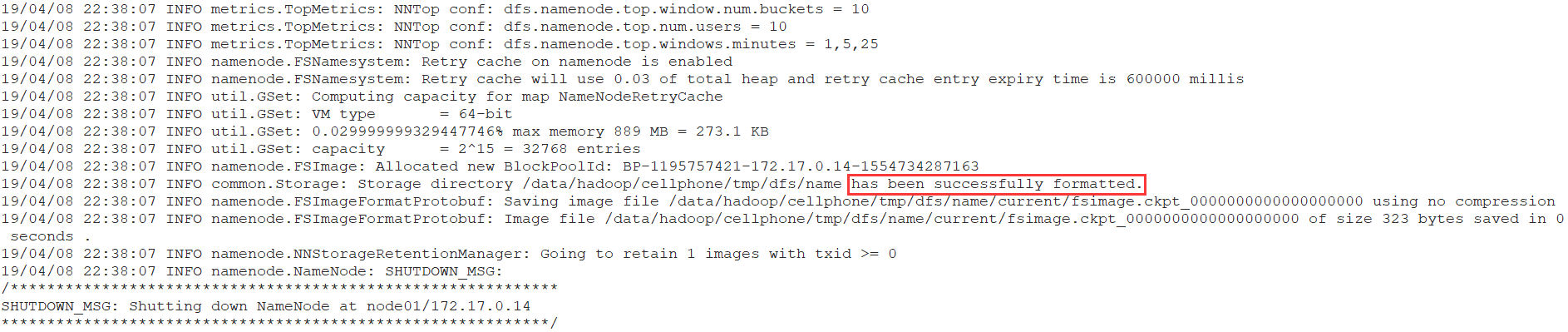
# bin/hadoop namenode -format
格式化NameNode,第一次启动服务前执行的操作,以后不需要执行。
2. 启动Hadoop
# ./hadoop/sbin/start-yarn.sh # ./hadoop/sbin/start-dfs.sh
3. 使用jps命令查看运行情况
#Master 执行jps查看运行情况 21890 Jps 16537 ResourceManager 17193 SecondaryNameNode 16958 NameNode
#Slave 执行jps查看运行情况 8692 DataNode 8472 NodeManager 21820 Jps
4. 命令查看Hadoop集群的状态
通过简单的jps命令虽然可以查看HDFS文件管理系统、MapReduce服务是否启动成功,但是无法查看到Hadoop整个集群的运行状态。我们可以通过 hdfs dfsadmin -report 进行查看。用该命令可以快速定位出哪些节点挂掉了,HDFS的容量以及使用了多少,以及每个节点的硬盘使用情况。
# hdfs dfsadmin -report
Configured Capacity: 316799934464 (295.04 GB) Present Capacity: 297909989376 (277.45 GB) DFS Remaining: 297909932032 (277.45 GB) DFS Used: 57344 (56 KB) DFS Used%: 0.00% Under replicated blocks: 0 Blocks with corrupt replicas: 0 Missing blocks: 0 Missing blocks (with replication factor 1): 0 Pending deletion blocks: 0 ------------------------------------------------- Live datanodes (2): Name: 172.17.0.17:50010 (node02) Hostname: node02 Decommission Status : Normal Configured Capacity: 158399967232 (147.52 GB) DFS Used: 28672 (28 KB) Non DFS Used: 1375121408 (1.28 GB) DFS Remaining: 148954976256 (138.73 GB) DFS Used%: 0.00% DFS Remaining%: 94.04% Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 1 Last contact: Tue Apr 09 13:43:57 CST 2019 Last Block Report: Tue Apr 09 11:50:48 CST 2019 Name: 172.17.0.4:50010 (node03) Hostname: node03 Decommission Status : Normal Configured Capacity: 158399967232 (147.52 GB) DFS Used: 28672 (28 KB) Non DFS Used: 1375141888 (1.28 GB) DFS Remaining: 148954955776 (138.73 GB) DFS Used%: 0.00% DFS Remaining%: 94.04% Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 1 Last contact: Tue Apr 09 13:43:57 CST 2019 Last Block Report: Tue Apr 09 08:28:15 CST 2019
5. WEB查看Hadoop集群的状态
成功启动后,可以访问 Web 界面查看 NameNode 和 Datanode 信息,还可以在线查看 HDFS 中的文件。
Yarn Web页面:http://node01:9088
HDFS Web页面:http://node01:50070
6. 关闭Hadoop
# ./hadoop/sbin/stop-dfs.sh # ./hadoop/sbin/stop-yarn.sh
问题
完成搭建后,出现过以下几个错误:
1. xxx: Error: JAVA_HOME is not set and could not be found
出现该错误说明没有找到JDK的环境变量,需要在hadoop-env.sh配置
# vi $HADOOP_HOME/etc/hadoop/hadoop-env.sh
## 配置项export JAVA_HOME=/data/jdk
2. Hadoop 9000端口拒绝访问,导致HDFS Web页面中Live Nodes数为0
使用start-all.sh启动整个集群后,jps查看每个节点该启动的进程都启动了,可以访问http://node01:50070页面,但是其中的Live Nodes项显示为0, 可实际有两个DataNode节点。出现此问题后查看DataNode的日志:
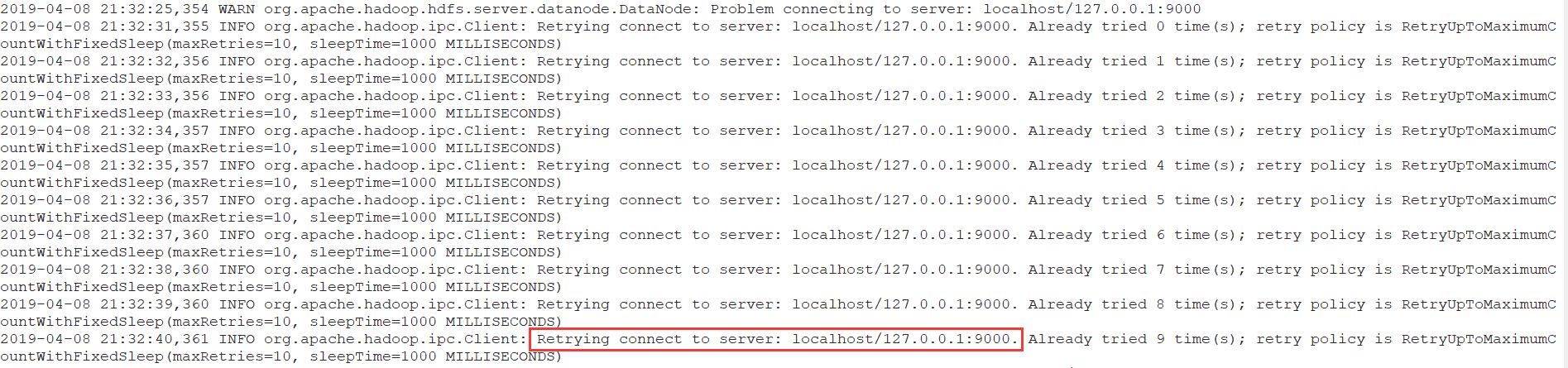
日志显示,DataNode尝试连接127.0.0.1:9000,但实际9000服务是在NameNode,后来发现是core-site.xml中 fs.defaultFS 配置错了,配成了hdfs://127.0.0.1:9000,修改成hdfs://node01:9000可解决问题。
3. Yarn 8031端口拒绝访问,导致Yarn Web页面中Active Nodes数为0
使用start-all.sh启动整个集群后,jps查看每个节点该启动的进程都启动了,可以访问http://node01:9088页面,但是其中的Active Nodes项显示为0, 可实际有两个NodeManager节点。出现此问题后查看NodeManager的日志:
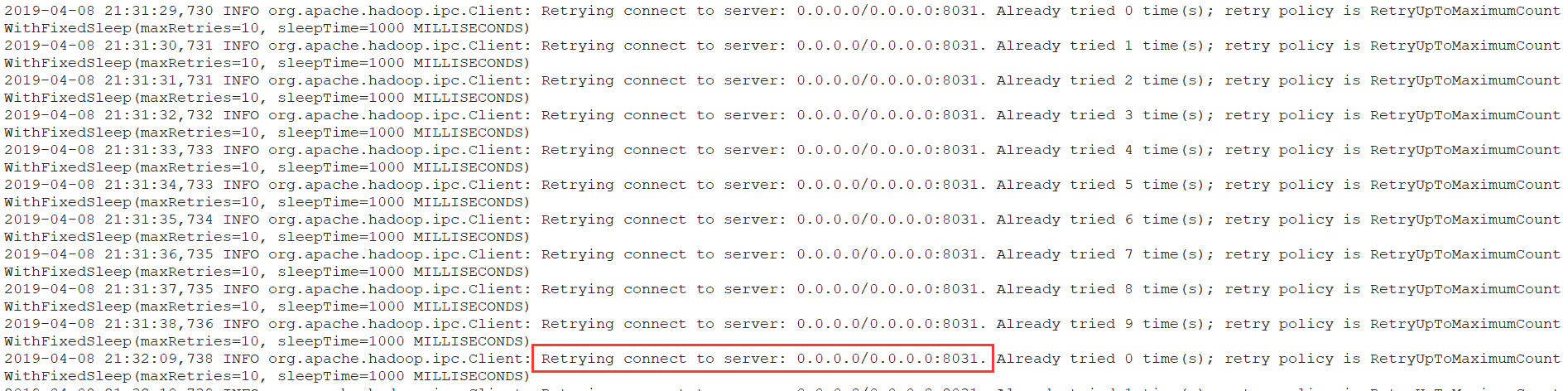
日志显示,NodeManager尝试连接0.0.0.0:8031,但失败了,后来在yarn-site.xml配置 yarn.resourcemanager.resource-tracker.address 参数为node01:8031即可解决问题。
4. 重新format namenode后,DataNode无法正常启动
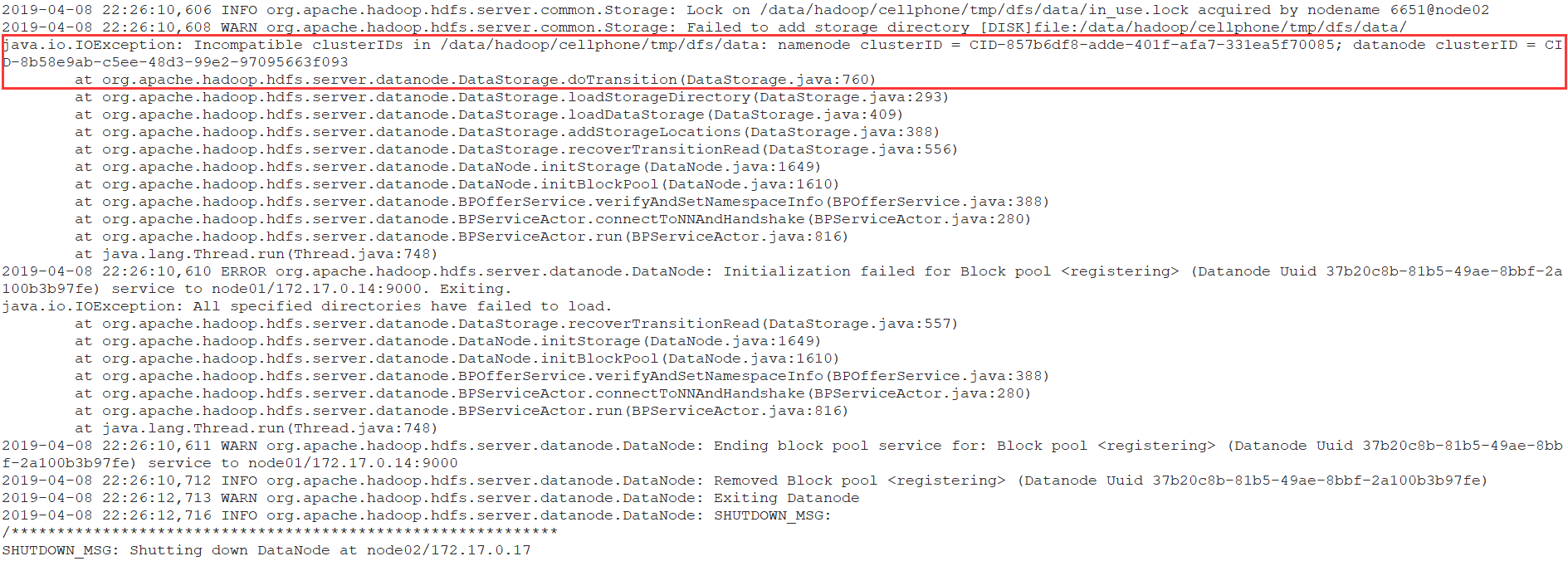
根据日志描述,原因是datanode的clusterID 和 namenode的clusterID 不匹配。打开hdfs-site.xml中关于datanode和namenode对应的目录,分别打开其中的current/VERSION文件,进行对比,发现确实不一致。
原因:
执行hdfs namenode -format后,current目录会删除并重新生成,其中VERSION文件中的clusterID也会随之变化,而datanode的VERSION文件中的clusterID保持不变,造成两个clusterID不一致。
所以为了避免这种情况,可以再执行的namenode格式化之后,删除datanode的current文件夹,或者修改datanode的VERSION文件中出clusterID与namenode的VERSION文件中的clusterID一样,然后重新启动datanode。
重新format namenode后,datanode无法正常启动















 1405
1405











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









