






*钟皓曦(长者、钟百万)老师授课*
图:由边集E和点集V构成。
有向图:含有至少一条有向边的图。
无向图:只含有无向边的图。
→例:左图是有向图,因为其含有有向边。
右图是有向图。虽然无向边相当于两条有向边,但无向边的两条有向边的权值相同,而右图的两条有向边权值不一定相同。

路径:点和边组成的序列。
简单路径:序列中不出现重复点与重复边。
→例:下图用红色标记的就是一条简单路径。

树:由n个点,n-1条边组成的无向图。
→结论:一棵n个点的树只有n-1条边。
→证明:每连一条边就相当于连通了两点,共需要n-1条边将n个点连通。
外向树:有从根向外趋势的有向树。
内向树:有从根向内趋势的有向树。
→例:左图为外向树,右图为内向树。

↓而上面的树既是外向树(左点为根时),又是内向树(右点为根时)。下面的树既不是外向树,也不是内向树。

基环树(环套树、树套环、章鱼图):任何无向树上连一条边,就会形成一棵基环树。
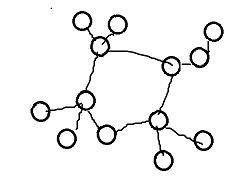
→性质:①有n条边。
②有且只有一环。
点仙人掌:图上任一点最多在一个环中。
→例:不是点仙人掌

边仙人掌:图上任一边最多在一个环中。
→例:不是边仙人掌
→P.S.:有关基环树和仙人掌的题目一般是DP,图论很少涉及。
DAG(有向无环图):没有环的有向图。
→结论:把有向环中的任一边反向,就会形成DAG。

二分图:将一个图中的点分成两个集合,图中所有的边都是从一个集合指向另一个集合,且两个集合内部都各没有边。
→例:
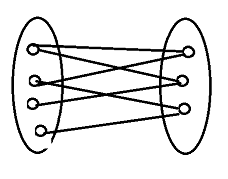
→结论:
①树是一个二分图。(将奇数层的点归为一个集合,偶数层的点归为一个集合,所有点都是从奇数层向偶数层连边)
②方格图(网格图)也是一个二分图。
将方格染成黑白两色,将相邻两方格之间连边。可知所有边都是一端为白格、一端为黑格,将原图分成了两部分。
→ 红色为边。
红色为边。
补图:把原有边删去,把原来没有的边加上,两图互为补图。
→例:
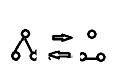
→二分图的补图:左集合中的点各自之间都有边,右集合也是这样。
与 互为补图。对二分图的补图再求一次补图,可将问题转化为二分图问题。
互为补图。对二分图的补图再求一次补图,可将问题转化为二分图问题。
存图方式:
→邻接矩阵:


#include<cstdio> #include<cstdlib> #include<cstring> using namespace std; int main() { return 0; } int n,m; int map[1000][1000]; for (int a=1;a<=m;a++) { cin >> s >> e >> d; map[s][e] = d; map[e][s] = d; } memset(map,-1,sizeof(map)); memset(map,0,sizeof(map)); //memset不是你想memset啥就memset啥 不能memset(-2/1/2...)啥的 memset(map,0x7f,sizeof(map));//0x7f7f7f7f //最好不要memset(0x7f) 因为这样容易爆int memset(map,0x3f,sizeof(map));//0x3f3f3f3f //常memset(0x3f),这样不会爆int
→前向星:(这么恶心的东西就直接上长者的代码了)
#include<algorithm> pair<int,int> ed[maxm]; cin >> n >> m; for (int a=1;a<=m;a++) { cin >> s >> e; ed[a] = make_pair(s,e);//s=起点 e=终点 } sort(ed+1,ed+m+1); //排序 int first[maxn]; for (int a=m;a>=1;a--) first[ed[a].first] = a; //倒序更新,最后更新完的first[]数组一定代表每个点所连的第一条边 first[n+1] = m+1; for (int a=n;a>=1;a--) if (first[a] == 0) first[a] = first[a+1]; //将没有边的点的first数组直接指向它下一个点的第一条边。 for (int a=first[s];a<first[s+1];a++) cout << ed[a].first << ed[a].second; //zhe li kai shi shi bian biao struct edge { int e; edge *next; }*v[maxn],ed[maxm]; void add_edge(int s,int e) { en++; ed[en].next = v[s];v[s]=ed+en;v[s]->e = e; } for (edge *e=v[s];e;e=e->next) cout << e->e; //er fen cha zhao int z[maxn]; sort(z+1,z+n+1); //cha xun x shi fou cun zai int l=0,r=n; while (l+1!=r) { int m=(l+r)/2; if (z[m]>=x) r=m; else l=m; }
→邻接表(边表):
#include<cstdio> #include<cstring> #include<algorithm> using namespace std; struct node { int to,nxt,w; }e[M<<1]; int head[N],tot; void add(int u,int v,int w) { e[++tot]=(node){to,head[u],w}; head[u]=tot; } int main() { int n,m; scanf("%d%d",&n,&m); for(int i=1;i<=m;i++) { int u,v,w; scanf("%d%d%d",&u,&v,&w); add(u,v,w); add(v,u,w);//无向图存正反两条边 } }
优点 缺点
邻接矩阵:O(1)定位、好写、快、支持动态加边。 O(n^2)空间(适用于n<=1000的情况)、枚举以u为起点的边O(n)。
前向星:比较快速地定位一条边是否存在O(logm) 难写、加边O(mlogn)、不支持动态加边。
(唯一用处,因为边集已是有序的,
所以可以二分查找)
邻接表(边表):比较好写,遍历以u为起点的边最快 不能快速判断某边是否存在O(m)、链表不能排序,必须枚举。














 148
148











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









