






“ 大模型虽然看起来很复杂,但我们只要具备工具思想,那么就可以轻松地玩转大模型。”
在对大模型的了解和应用过程中发现一个问题,就是很多人对大模型抱着神秘和高大上的想法;认为搞大模型的都是技术大拿或者高学历的精英人才,甚至有些人会认为大模型无所不能。
但事实上,大模型没有大家想象中的那么神秘和复杂;大模型也有自己的能力边界,它也无法做到超出它能力范围的事;而且现在大模型也存在各种各样的问题,否则大模型技术就不再需要发展了。
大模型祛魅
首先从纯粹的技术理论来讲,大模型本身就是一个模仿人脑神经网络的数学模型;通过统计和概率学的方法来模仿人脑的学习过程,虽然其中提出了各种各样的模型架构,但本质上来说都是数学问题。
只不过其主要是基于向量和多维矩阵这个数学工具来进行相似度计算,通过这种方式来表示数据之间的关系;以此来完成语义,图片理解和生成。
从大模型的运行过程上来说,大模型主要有理解和生成两个步骤;对应用人员来说,大模型就是一个黑箱,有一个输入口和一个输出口;大模型接受用户的输入并理解用户意图,这个过程就是理解过程;而大模型在理解用户意图之后,通过模型参数来生成用户所需要的东西,这个过程就是生成过程。
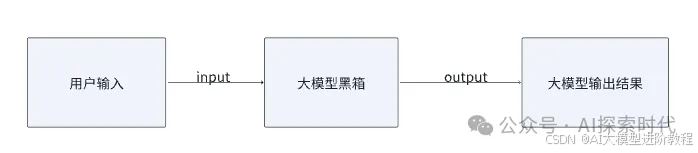
虽然根据不同的任务场景,有多种执行不同任务的模型类型;但本质上来说都是输入理解和结果生成的过程;其中包括推理类模型,只不过推理类模型会存在一个“思考”的过程。
不同任务的大模型因为根据不同的任务类型会设计不同的技术架构,其目的就是为了更好的处理任务数据;而除了模型架构的区别之外,还一个就是训练数据的区别;不同任务的模型,需要使用特定形式或格式的训练数据。
比如说分类模型需要使用不同分类的数据进行训练;聊天模型需要使用对话数据进行训练等;而不同的任务类型,需要使用特定任务或领域的数据进行训练。
至于模型实现过程中需要使用的损失计算,优化函数,反向传播,反馈学习,强化学习等技术;基本上都属于模型通用的技术流程,只不过由于任务的特性可能会进行适当的调整和使用不同的算法来实现。
而从技术开发者的角度来说,使用大模型的能力,基本上就是调用几个接口就行了;应该说,大模型本身也就一到两个接口,只不过根据不同的需求,设计不同的提示词或角色扮演等来约束大模型的输出。
而那些大模型服务提供商或者一些平台,它们虽然看似提供了很多功能接口;但这些接口基本上都是它们自己封装的业务接口,然后背后依然是调用大模型的一个或两个接口,和大模型没太大关系。
所以,如果你不是搞模型开发,需要很强的数学和编程功底之外;从应用的角度来说,大模型使用起来很简单,你给一个输入,大模型给一个输出。而本质上就是提示词的编写,也就是说在大模型应用中,提示词才是其中的核心部分。
-
文本生成类(Text Generation)
-
文本理解类(Text Understanding)
-
多模态任务类(Multimodal Tasks)
-
决策与推理类(Decision Making & Reasoning)
-
序列转换类(Sequence Transformation)
-
Embedding模型类
-
强化学习对齐类(RL-Aligned)
只不过,把大模型应用到具体的产品或系统开发中,会延伸出一系列的问题;比如说模型记忆问题,文档的处理问题,格式化输出问题,提示词的优化问题;以及怎么挖掘大模型的潜力,让大模型在业务中表现得更好,这就需要结合大量的工程化能力来解决。
比如说通过更好的提示词来激发大模型的潜力,使用RAG技术来增强大模型的知识,使用训练微调等技术来提升大模型的能力,使用Agent技术来充当大模型的手和脚,使用工作流来串联功能模块等等。
最后
如果你真的想学习大模型,请不要去网上找那些零零碎碎的教程,真的很难学懂!
你可以根据我这个学习路线和系统资料,制定一套学习计划,只要你肯花时间沉下心去学习,它们一定能帮到你!

















 1250
1250

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









