





发布-订阅消息系统在任何企业体系结构中都起着重要作用,因为它可以实现可靠的集成而无需紧密耦合应用程序。 在解耦的系统之间共享数据的能力并不是一个容易解决的问题。
考虑一个企业,其中具有使用不同语言和平台独立构建的多个应用程序。 它需要以响应方式共享数据和流程。 我们可以使用Messaging通过使用可自定义的格式频繁,立即,可靠且异步地传输数据包来实现此目的。 从根本上说,异步消息传递是对分布式系统问题的务实反应。 发送消息不需要两个系统同时启动和就绪。
发布-订阅频道
从简单的角度来看,通过添加用于传达事件通知的事件通道的概念,对这种模式的理解依赖于它对观察者模式的扩展。 观察者模式描述了将观察者与他们的主题脱钩的必要性,这样,无论有多少观察者,主题都可以轻松地向所有感兴趣的观察者提供事件通知。
每个订阅者都需要一次被通知特定事件,但不应重复通知同一事件。 在通知所有订户之前,不能认为事件已消耗。 但是,一旦所有订户都得到通知,该事件就可以视为已消耗,应该从通道中消失[2]。
代理,队列,主题和订阅
代理消息传递支持真实时间解耦系统的场景,在这种情况下,不能保证消息生产者或使用者的可用性。 对于代理消息传递,队列是保留由生产者创建的消息的代理,并且消费者在准备就绪时可以在其中检索消息。
队列提供了最简单的邮件传递选项。 队列中的消息是按照先进先出(FIFO)进行组织的,并且每个消息都应由单个使用者处理。 但是,主题和订阅构成了一种发布/订阅模式,允许N个消费者处理同一条消息。
可以将单个消息添加到主题,并且对于满足的每个订阅规则,将消息的副本添加到该订阅。 在这种情况下,每个订阅都会成为队列,消费者可以在其中单独处理订阅上的消息。
行业领先者正在使用的可靠且成熟的项目之一是Apache Kafka,它为我们提供了每秒处理大量消息的能力,而不是传统的消息传递系统,该系统在传统场景中非常有用,但效率和价值却不高在处理大数据场景中。
除消息传递外,Apache Kafka还可以应用于流处理,网站活动跟踪,日志聚合,指标,基于时间的消息存储,提交日志和事件源。 在下一节中,我们将深入介绍Apache Kafka的组件和特征。
卡夫卡
Kafka是一个分布式的发布-订阅消息系统,通过其设计,分区和复制的提交日志服务,其本质上是快速,可伸缩的并且分布式的。 它与传统消息传递系统的不同之处在于,它非常易于扩展,提供高吞吐量,支持多订户并在故障期间自动平衡使用者,并具有允许实时应用程序或ETL将其用作批处理消耗的能力磁盘上的持久消息数。
组件[1]
- 生产者 –生产者是将消息发布给Kafka经纪人的任何应用程序/程序。
- 使用者 -使用者是使用来自Kafka经纪人的消息的应用程序。 这些使用者可以是简单的应用程序,实时流处理引擎等。
- 主题和分区 – Apache Kafka支持消息主题的概念,这些主题允许对消息进行分类。 它使我们能够为不同类型的消息创建不同的主题,并让不同的消费者使用消息。 此外,Apache Kafka允许在一个Topic中创建多个分区,以允许并行使用消息,因为我们可以同时从不同的分区中消费不同的使用者。 每个分区都有一个领导节点,负责处理来自消费者/生产者对该分区的读/写请求。
- 代理 – Kafka代理通常是指安装了Kafka的计算机。 但是,可以在非生产设置中在一台计算机上设置多个代理。 Kafka经纪人负责管理消息日志并接受生产者/消费者的请求。 卡夫卡经纪人是无国籍的。 这意味着消费者必须保持已经消费了多少。 消费者自己维护它,经纪人不会做任何事情。
- 存储 – Kafka具有非常简单的存储布局。 主题的每个分区都对应一个逻辑日志。 从物理上讲,日志是作为一组大小相等的段文件实现的。 每次生产者将消息发布到分区时,代理都将消息简单地附加到最后一个段文件。 在发布了可配置数量的消息或经过一定时间后,段文件将刷新到磁盘。 消息在清除后会暴露给使用者。
- 集群 – Kafka集群是Kafka经纪人的集合。 集群中的所有Kafka经纪人共同工作,以管理已配置的消息及其副本。
动物园管理员
ZooKeeper用于管理和协调Kafka经纪人。 每个Kafka经纪人都使用ZooKeeper与其他Kafka经纪人进行协调。 ZooKeeper服务会通知生产者和消费者有关Kafka系统中是否存在新代理或代理失败的信息。 从Zookeeper收到的有关经纪人存在或失败的通知中,生产者和消费者做出决定并开始与其他经纪人协调工作。 同样,它负责为分区选择新的领导者。
案例分析
稍作调整后,专注于练习。 因此,我们的案例研究使用Apache Kafka 2.3.1作为消息系统,在发布-订阅上下文中模拟了使用Spring Boot微框架v2.1.8.RELEASE构建的两个微服务之间的通信。 为了验证我们的研究,我们将设置并执行一个集成测试,该测试重点在于使用JUnit 4/5测试框架在端到端场景中集成应用程序的不同层。
生产者API是一个模块,用于实现业务实体服务的操作,以协调和协调与企业,机构和实体组有关的经济信息。 消费者API是同一解决方案中的另一个模块,旨在集中所有业务实体统计信息,并接收来自不同来源的数据输入。
为了简单起见,API使用H2内存数据库。 项目结构由三个模块组成。 Producer和Consumer这两个主要模块都具有Common模块的依赖性,在Common模块中,它与系统的其余部分共享诸如错误处理和辅助类之类的内容。
可从GitHub存储库访问该示例; 要下载它,请点击此链接 。
让我们开始吧。
将Spring Kafka与Apache Kafka消息系统集成
用于Apache Kafka的Spring项目将核心Spring概念应用于基于Kafka的消息传递解决方案的开发。 它提供了一个“模板”作为发送消息的高级抽象。 它还通过@KafkaListener批注和“侦听器容器”为消息驱动的POJO提供支持。 这些库促进了依赖注入和声明性[3]的使用。
生产者API
我们需要两个步骤来配置生产者。 第一个是config类,其中定义生产者Map对象,生产者工厂和Kafka模板。 当我们将消息生成器设置为在Kafka代理中发布时,第二种尊重服务类。
生产者配置
在配置类中,在application.properties中设置了常数“ bootstrapServers” (即Kafka服务器)。 使用@Value(“ $ {spring.kafka.bootstrap-servers}”)批注表示受影响参数的默认值表达式。
要创建Kafka生产者,我们定义一些属性,这些属性将传递给Kafka生产者的构造函数。 在“ producerconfigs ” @Bean中,我们将BOOTSTRAP_SERVERS_CONFIG属性设置为我们先前在application.properties中定义的代理地址列表。 BOOTSTRAP_SERVERS_CONFIG值是主机/端口对的逗号分隔列表,生产者用来建立与Kafka群集的初始连接。
package com.BusinessEntityManagementSystem;
import ...
@Configuration
public class KafkaProducerConfig {
@Value("${spring.kafka.bootstrap-servers}")
private String bootstrapServers;
@Bean
public Map<String, Object> producerConfigs() {
Map<String, Object> props = new HashMap<>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, JsonSerializer.class);
return props;
}
@Bean
public ProducerFactory<String, BusinessEntity> producerFactory() {
return new DefaultKafkaProducerFactory<>(producerConfigs());
}
@Bean
public KafkaTemplate<String, BusinessEntity> kafkaTemplate() {
return new KafkaTemplate<String, BusinessEntity>(producerFactory());
}
}
KEY_SERIALIZER_CLASS_CONFIG是用于Kafka记录键的Kafka序列化器类,该类实现了Kafka序列化器接口。 注意,我们将其设置为StringSerializer.class作为消息ID。 VALUE_SERIALIZER_CLASS_CONFIG是一个Kafka序列化程序类,我们将其设置为JsonSerializer.class作为消息主体。
要创建消息,首先,我们需要配置一个ProducerFactory,该工厂设置创建Kafka Producer实例的策略。 然后,我们需要一个KafkaTemplate,它包装一个Producer实例,并提供使用数据传输对象“ BusinessEntity ”将消息发送到Kafka主题的便捷方法。
生产者服务
在Kafka Producer服务类中, @ Service注释表示带注释的类是“服务”。 在此类中,我们实现了将消息发送到Kafka代理的方法,在application.properties中预定义的标头上声明了topic属性。
package com.BusinessEntityManagementSystem.kafka;
import ...
@Service
public class KafkaProducer {
@Autowired
private KafkaTemplate<String, BusinessEntity> kafkaTemplate;
@Value("${statistics.kafka.topic}")
String kafkaTopic;
public void send(BusinessEntity payload) {
Message<BusinessEntity> message = MessageBuilder
.withPayload(payload)
.setHeader(KafkaHeaders.TOPIC, kafkaTopic)
.build();
kafkaTemplate.send(message);
}
}
消费者API
在Consumer中,我们需要添加适当的Deserializer,该Deserializer可以将JSON byte []转换为Java Object。 要设置它,我们需要使用config和带有@components注释的类,当使用基于注释的配置和类路径扫描时,它们将自动检测此类以进行依赖项注入。
消费者配置
同样,当我们指定KEY_SERIALIZER_CLASS_CONFIG,VALUE_SERIALIZER_CLASS_CONFIG来序列化生产者发布的消息时,我们还需要通知Spring Kafka有关反序列化的常量值,例如KEY_DESERIALIZER_CLASS_CONFIG和VALUE_DESERIALIZER_CLASS_CONFIG。 除了上面引用的常量之外,我们还指定了GROUP_ID_CONFIG和AUTO_OFFSET_RESET_CONFIG作为最早的常量,从而允许使用者读取代理中最后插入的消息。
要启用Kafka侦听器,我们使用@EnableKafka批注。 这注释了由AbstractListenerContainerFactory在后台创建的端点。 KafkaListenerContainerFactory负责为特定端点创建侦听器容器。 它可以检测容器中任何受Spring管理的bean上的KafkaListener批注。
作为典型的实现, ConcurrentKafkaListenerContainerFactory提供了基础MessageListenerContainer支持的必要配置选项。
package com.BusinessStatisticsUnitFiles;
import ...
@Configuration
@EnableKafka
public class KafkaConsumerConfig {
@Value("${spring.kafka.bootstrap-servers}")
private String bootstrapServers;
@Bean
public Map<String, Object> consumerConfigs() {
Map<String, Object> props = new HashMap<>();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, JsonDeserializer.class);
props.put(ConsumerConfig.GROUP_ID_CONFIG, "statistics-BusinessStatisticsUnitFiles-group");
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
return props;
}
@Bean
public ConsumerFactory<String, BusinessEntity> consumerFactory() {
return new DefaultKafkaConsumerFactory<>(
consumerConfigs(),
new StringDeserializer(),
new JsonDeserializer<>(BusinessEntity.class, false));
}
@Bean
public ConcurrentKafkaListenerContainerFactory<String, BusinessEntity> kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<String, BusinessEntity> factory =
new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
return factory;
}
}
在消费者工厂,我们可以禁用标题的使用。 现在,这可以通过将新JsonDeserializer <>(BusinessEntity.class,false))中的第二个参数设置为false来实现; 。 这使使用者可以信任来自任何程序包的消息。
消费者“服务”
为了使用消息,有必要像上面一样配置ConsumerFactory和KafkaListenerContainerFactory。 一旦这些bean在Spring bean工厂中可用,就可以使用@KafkaListener注释配置基于POJO的使用者。
在用@KafkaListener注释的类中, @ KafkaHandler还需要将方法标记为Kafka消息侦听器的目标。 重要的是要了解,当消息到达时,选择的方法取决于有效负载类型。 该类型与单个非注释参数匹配,或与@Payload注释的参数匹配。 绝不能有歧义-系统必须能够根据有效载荷类型选择恰好一种方法。
package com.BusinessStatisticsUnitFiles.kafka;
import ...
@Component
public class KafkaConsumer {
@Autowired
IBusinessEntityRepository businessEntityRepository;
private static final Logger LOG = LoggerFactory.getLogger(BusinessEntity.class);
@KafkaListener(topics = "${statistics.kafka.topic.create.entity}", groupId = "statistics-BusinessEntityManagementSystem-group")
@KafkaHandler
public void receiveCreatedEntity(@Payload BusinessEntity data,
@Headers MessageHeaders headers) {
businessEntityRepository.save(RetrieveConsumerFromReceivedProducerObject.Binding(new BusinessEntityModel(), data));
}
}
@Payload批注将方法参数绑定到消息的有效负载。 它还可以用于将有效负载与方法调用相关联。 有效负载可以通过MessageConverter传递,以将其从具有特定MIME类型的序列化形式转换为与目标方法参数匹配的Object。 用@Payload注释的类是“ BusinessEntity” DTO。
Spring Boot还支持使用侦听器中的@Headers批注检索一个或多个消息头。 可以为一个主题实现多个侦听器,每个侦听器具有不同的组ID。 此外,一个消费者可以收听来自各种主题的消息。
您可能已经注意到,我们创建的主题建筑只有一个分区。 但是,对于具有多个分区的主题, @ KafkaListener可以显式订阅具有初始偏移量的主题的特定分区。
Application.properties
最后但并非最不重要的一点是,在我们的配置中,我们指定一些与生产者和消费者之间的通信行为有关的值。
生产者/消费者
在每个Producer和Consumer API上,我们都使用spring.kafka.bootstrap-servers = localhost:9092定义了我们希望微服务连接的Kafka集群。 同样,有必要定义主题名称以产生和接收消息,密钥以及组ID。
... ## Application.properties Kafka config spring.kafka.bootstrap-servers=localhost:9092 statistics.kafka.topic=test statistics.kafka.key=test statistics.kafka.topic.create.entity=test spring.kafka.producer.group-id=statistics-BusinessStatisticsUnitFiles-group spring.kafka.template.default-topic=test ...
准备Kafka和Zookeeper进行集成测试
下面定义的步骤演示了如何在Windows 10操作系统上运行和测试Kafka。
下载带有嵌入式Zookeeper的Kafka
- 下载Kafka二进制文件 。 这篇文章基于Kafka 2.3.1,因此我们假设您正在下载Scala 2.12的2.3.1版本。
- 解压缩kafka_2.12-2.3.1.tgz文件。
设置zookeeper.properties
为了使其正常工作,我们需要更改Zookeeper数据目录的位置。
打开kafka \ config \ zookeeper.properties文件,然后将Zookeeper数据/ log目录位置配置更改为有效的Windows目录位置。
dataDir=C:\\kafka\\zookeeper-logs
设置server.properties
我们还需要对Kafka配置进行一些更改。 打开kafka \ config \ server.properties并将主题默认设置为1。 我们将运行一个单节点Kafka。 另外,为防止Kafka创建不必要的偏移量,我们将副本指定为1。我们在Windows环境中使用最新的Kafka 2.3.1版本遇到此问题。 这导致Kafka停止,因为内存不足,无法处理在启动服务器的初始阶段自动创建的大量数据。
############################# Log Basics ############################# log.dirs=C:\\kafka\\kafka-logs ####################### Internal Topic Settings ##################### offsets.topic.replication.factor=1 offsets.topic.num.partitions = 1 min.insync.replicas=1 default.replication.factor = 1 ...
要完成Kafka配置,请将Kafka bin \ windows目录添加到PATH环境变量中。
创建和执行集成测试
顾名思义,集成测试专注于集成应用程序的不同层,其中不涉及任何模拟。 集成测试需要启动一个容器来执行测试用例。 因此,为此需要一些额外的设置,但是使用spring boot时,使用一些注释和库可以很容易地完成这些步骤。
测试班
第一个注释@RunWith(SpringRunner.class)用于在Spring Boot测试功能和JUnit之间建立桥梁。 SpringRunner.class在测试中全面支持Spring上下文加载和Bean的依赖项注入。 @SpringBootTest通过SpringApplication创建ApplicationContext测试,这些测试将在我们的测试中使用。 自嵌入式服务器以来,它将引导整个容器,并创建一个Web环境。
在我们的测试中,我们模仿的是真实的Web环境,将其设置为RANDOM_PORT也会加载WebServerApplicationContext。 嵌入式服务器将启动并在随机端口上进行侦听。
@RunWith(SpringRunner.class)
@SpringBootTest(classes = {BusinessEntityManagementApplication.class}, webEnvironment = SpringBootTest.WebEnvironment.RANDOM_PORT)
class BusinessEntityIntegrationTest {
@LocalServerPort
private int port;
@Autowired
TestRestTemplate restTemplate;
HttpHeaders headers = new HttpHeaders();
@LocalServerPort批注为我们提供了在运行时分配的注入的HTTP端口。 这是@Value("${local.server.port}")的便捷替代方法。
要访问Spring应用程序中的第三方REST服务,我们使用Spring RestTemplate或TestRestTemplate ,这是一种适合集成测试的便捷替代方法,方法是将其注入我们的测试类中。 通过在项目中使用spring-boot-starter-test依赖项,我们可以在运行时访问“ TestRestTemplate”类。
测试方法
在我们的方法测试中,我们使用“ junit-json-params ”,这是一个Junit 5库,提供注释以从JSON字符串或参数化测试中的文件加载数据。 我们还使用@ParameterizedTest注释对方法进行了注释,以补充下面的库。 它用于表示带注释的方法是参数化测试方法。 该方法不得为私有或静态。 他们还必须通过@ArgumentsSource或相应的组合批注指定至少一个ArgumentsProvider 。
我们的@ArgumentsSource是@ArgumentsSource中的JSON文件@JsonFileSource(resources =“ /business-entity-test-param.json”)。 @JsonFileSource允许您使用类路径中的JSON文件。 它支持单个对象,对象数组和JSON原语。
从文件中检索的JSON对象绑定到方法参数“对象”,该方法将其转换为POJO对象,在本例中为我们的实体模型。
@ParameterizedTest
@JsonFileSource(resources = "/business-entity-test-param.json")
@DisplayName("create business entity with json parameter")
void createBusinessEntity(JsonObject object) throws IOException, URISyntaxException {
BusinessEntityModel businessEntityModel;
businessEntityModel = new BusinessEntityModel();
ObjectMapper mapper = new ObjectMapper();
businessEntityModel = mapper.readValue(object.toString(), BusinessEntityModel.class);
HttpEntity<BusinessEntityModel> request = new HttpEntity<>(businessEntityModel, headers);
try {
ResponseEntity<String> response = this.restTemplate.postForEntity(createURLWithPort("/api/businessEntityManagementSystem/v1/businessEntity"), request, String.class);
assertAll(
() -> assertThat(response.getStatusCodeValue()).isEqualTo(HttpStatus.CREATED.value()),
() -> assertThat(response.getHeaders().getLocation().getPath()).contains("/v1")
);
}
catch(HttpClientErrorException ex) {
assertAll(
() -> Assert.assertEquals(HttpStatus.BAD_REQUEST.value(), ex.getRawStatusCode()),
() -> Assert.assertEquals(true, ex.getResponseBodyAsString().contains("Missing request header"))
);
}
}
在安排并执行操作之后,我们断言对其余API的调用是否返回了所需的结果。
运行集成测试
在我们的开发环境中,我们需要确保我们的Kafka和Zookeeper在两个不同的控制台中启动并运行,如图所示
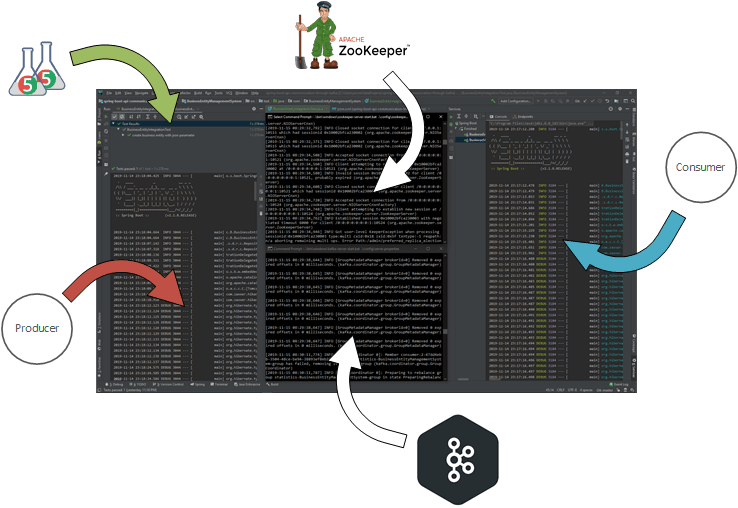
Kafka需要Zookeeper,因此我们将首先使用以下命令启动Zookeeper。
c:\kafka>.\bin\windows\zookeeper-server-start.bat .\config\zookeeper.properties
它应该启动Zookeeper服务器。 最小化命令窗口,并让Zookeeper在该窗口中运行。 启动一个新的命令窗口,并使用以下命令启动Kafka Broker。
c:\kafka>.\bin\windows\kafka-server-start.bat .\config\server.properties
接下来,我们将按照我们的想法运行Consumer API,或者将其部署在任何兼容的Web服务器中。
最后,我们可以将测试类作为JUnit测试执行。 它将按正常方式启动服务器并部署API。 然后它将执行测试。 您可以在“ JUnit”选项卡中验证测试。
结论
在本文中,我们看到了如何使用发布-订阅模式以可响应的方式在两个不同的微服务之间使用可定制格式频繁,立即,可靠和异步地共享数据,并通过在不同层中的不同层进行集成测试来对其进行验证。端到端场景。
参考文献
[1] Kafka 2.3文档 ;[2] Gregor Hohpe,Bobby Woolf,企业集成模式设计,构建和部署消息解决方案,2003年;
[3] 适用于Apache Kafka 2.3.3的Spring 。















 7246
7246

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









