





在本SpringApache Kafka课程中,我们将学习如何在Spring Boot项目中开始使用Apache Kafka,并开始生成和使用我们所选主题的消息。 除了一个简单的项目外,我们还将深入探讨Kafka的术语以及分区概念在Kafka中的工作方式。 让我们开始吧。
1.简介
随着的起义微服务 ,涉及的服务之间的异步通信的必要性成为主流需求。 实际上,这就是Apache Kafka在LinkedIn上出现的方式 。 他们需要的新异步通信系统的主要要求是消息持久性和高吞吐量 。 一旦LinkedIn能够面对Kafka进行项目开发,他们便将该项目捐赠给Apache Software Foundation,该基金会后来被称为Apache Kafka 。
目录
2.什么是Apache Kafka?
Kafka于2010年在LinkedIn上开发,并捐赠给Apache Software Foundation,该基金会到2012年成为顶级项目之一。Apache Kafka在其生态系统中具有三个主要组成部分:
- Publisher-Subscriber :Kafka的此组件负责跨Kafka节点(将在后面的部分中详细介绍节点)和可以以很高的吞吐量扩展的消费者应用程序之间发送和使用数据
- Kafka Streams :使用Kafka流API,可以将接近实时的输入数据处理到kafka中
- Connect API :使用Connect API,可以将许多外部数据源和数据接收器与Kafka集成
对于高级定义,我们可以为Apache Kafka提供一个简单的定义:
Apache Kafka是一个分布式的,可容错的,可水平扩展的提交日志。
让我们详细说明一下:
- 分布式 :Kafka是一个分布式系统,其中所有消息都在各个节点上复制,因此每个服务器都能够响应客户端包含的消息。 此外,即使一个节点发生故障,其他节点也可以快速接管而无需停机
- 容错 :由于Kafka没有单点故障 ,即使其中一个节点发生故障,最终用户也几乎不会注意到这一点,因为其他部分对由于故障节点而丢失的消息负责
- 可水平扩展 :Kafka允许我们以零停机时间向群集添加更多计算机。 这意味着,如果由于集群中服务器数量少而开始出现消息滞后的情况,我们可以快速添加更多服务器并保持系统性能
- 提交日志 :提交日志是指类似于链接列表的结构。 消息的插入顺序得以维持,并且直到达到阈值时间后,才能从此日志中删除数据
在接下来的部分中,我们将讨论关于Apache Kafka的基本术语的更多概念将变得更加清晰。
3. Apache Kafka术语
在继续进行Kafka概念和示例项目之前,我们必须了解与Apache Kafka相关的基本术语。 其中一些是:
- 生产者 :此组件将消息发布到Kafka集群
- 使用者 :此组件使用来自Kafka集群的消息
- 消息 :这是生产者发送到集群的数据
- 连接 :生产者需要建立一个TCP连接以发布消息。 消费者应用程序也需要同样的条件来消耗Kafka集群中的数据
- 主题 :主题是类似消息的逻辑分组。 生产者应用可以将消息发布到特定主题,并且可以从特定主题中消费
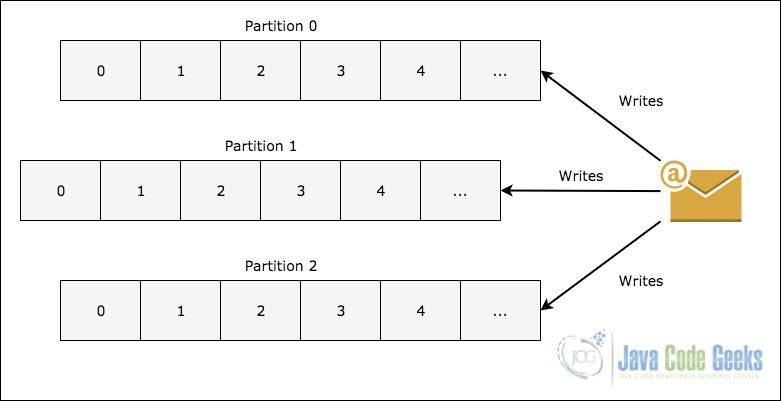
- 主题分区 :为了扩展主题内存,因为它可以包含很多消息,因此将一个主题划分为多个分区,每个分区可以位于群集中的任何节点上,下图显示了如何将消息写入多个分区:

卡夫卡中的主题划分
- 副本 :如上图所示,有关主题分区,每个消息都在各个节点之间复制,以维持顺序并防止其中一个节点死亡时数据丢失
- 消费者组 :可以将对一个主题感兴趣的多个消费者归为一组,称为“消费者组”。
- 偏移量 :Kafka不存储有关哪个消费者将要读取哪些数据的信息。 每个使用者都保留有关他们最后阅读的消息是什么的偏移值。 这意味着不同的消费者可以同时阅读不同的消息
- 节点 :节点只是集群中的单个服务器。 我们可以选择在集群中添加几乎任何数量的节点
- 群集 :一组节点称为群集。
4.安装Kafka并制作主题
要下载并安装Kafka,我们可以参考此处提供的Kafka官方指南。 当Kafka服务器启动并运行时,我们可以使用以下命令创建一个名为javacodegeeks的新主题:
创建一个话题
bin/kafka-topics --create \
--zookeeper localhost:2181 \
--replication-factor 1 --partitions 1 \
--topic javacodegeeks一旦执行此命令,我们将看到以下输出:
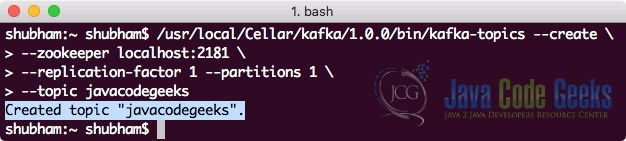
Kafka创建主题
5.使用Maven制作Spring Boot项目
我们将使用许多Maven原型之一为我们的示例创建一个示例项目。 要创建项目,请在将用作工作空间的目录中执行以下命令:
创建一个项目
mvn archetype:generate -DgroupId=com.javacodegeeks.example -DartifactId=JCG-BootKafka-Example -DarchetypeArtifactId=maven-archetype-quickstart -DinteractiveMode=false如果您是第一次运行maven,则完成生成命令将花费几秒钟,因为maven必须下载所有必需的插件和工件才能完成生成任务。 运行该项目后,我们将看到以下输出并创建该项目:
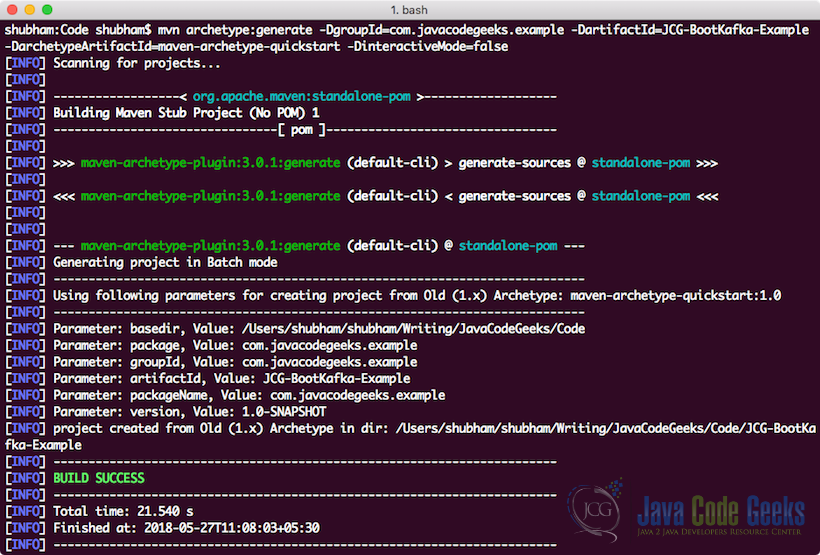
创建Kafka项目
6.添加Maven依赖项
创建项目后,请随时在您喜欢的IDE中打开它。 下一步是向项目添加适当的Maven依赖关系。 我们将在项目中使用以下依赖项:
-
spring-boot-starter-web:此依赖关系将该项目标记为Web项目,并且添加了依赖关系以创建控制器并创建与Web相关的类。 -
spring-kafka:这是将所有与Kafka相关的依赖项引入项目类路径的依赖项 -
spring-boot-starter-test:此依赖项将所有与测试相关的JAR收集到项目中,例如JUnit和Mockito 。
这是pom.xml文件,其中添加了适当的依赖项:
pom.xml
<groupId>com.javacodegeeks.example</groupId>
<artifactId>JCG-BootKafka-Example</artifactId>
<packaging>jar</packaging>
<version>1.0-SNAPSHOT</version>
<name>JCG-BootKafka-Example</name>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>1.5.10.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<version>1.1.3.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>在Maven Central上找到最新的Maven依赖项。
最后,要了解添加此依赖项时添加到项目中的所有JAR,我们可以运行一个简单的Maven命令,当我们向其添加一些依赖项时,该命令使我们能够查看项目的完整依赖关系树。 这是我们可以使用的命令:
检查依赖树
mvn dependency:tree当我们运行此命令时,它将向我们显示以下依赖关系树:
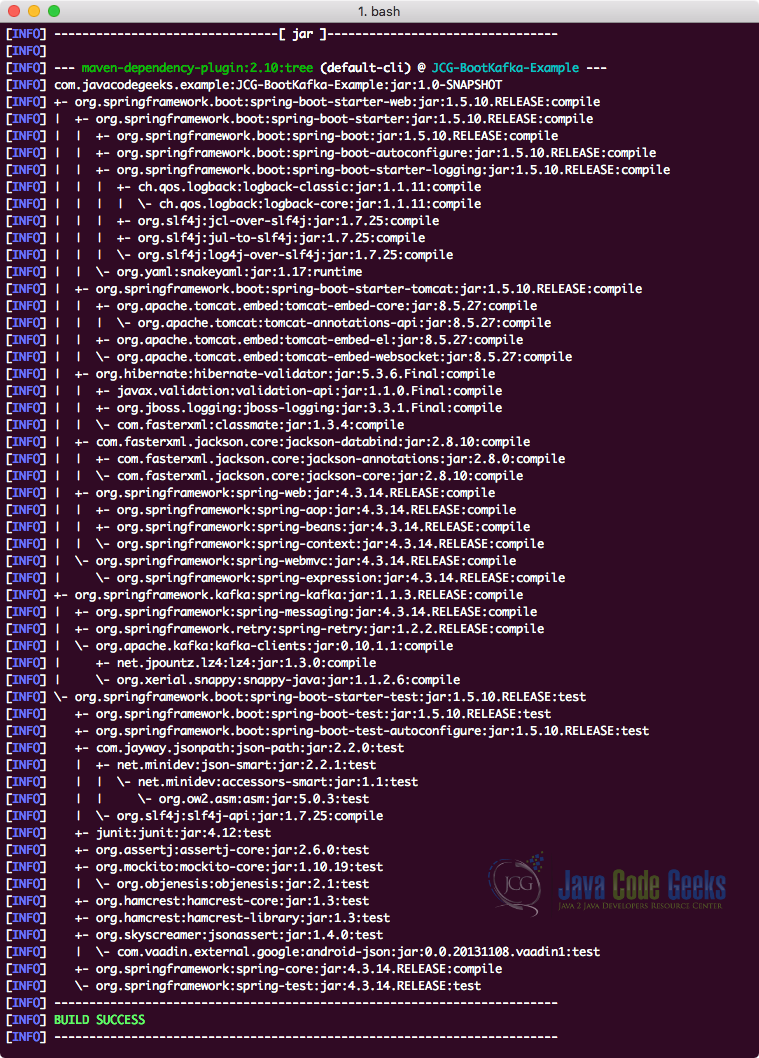
检查依赖
注意到了什么? 通过向项目中添加四个依赖项,添加了如此多的依赖项。 Spring Boot本身会收集所有相关的依赖项,因此在此方面不做任何事情。 最大的优势在于, 所有这些依赖项都保证相互兼容 。
7.项目结构
在继续进行并开始处理项目代码之前,让我们在这里介绍完成所有代码添加到项目后将拥有的项目结构:
项目结构
我们将项目分为多个包,以便遵循关注点分离的原则,并且代码保持模块化。
8.添加配置
在开始为项目编写代码之前,我们需要在Spring Boot项目的application.properties文件中提供一些属性:
application.properties
#Kafka Topic
message.topic.name=javacodegeeks
spring.kafka.bootstrap-servers=localhost:9092
#Unique String which identifies which consumer group this consumer belongs to
spring.kafka.consumer.group-id=jcg-group 这些是我们将在项目中使用的一些属性,这些属性将用作我们将发布和使用的消息的主题和组ID。 另外, 9092是Apache Kafka的默认端口。 请注意,我们可以在此处定义多个主题,并为键指定不同的名称。
9.定义生产者配置
我们将从定义生产者的配置开始。 我们需要为Kafka Producer强制定义的唯一属性是带有端口的Kafka服务器的地址。
KafkaProducerConfig.java
package com.javacodegeeks.example.config;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.common.serialization.StringSerializer;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.core.DefaultKafkaProducerFactory;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.core.ProducerFactory;
import java.util.HashMap;
import java.util.Map;
@Configuration
public class KafkaProducerConfig {
@Value("${spring.kafka.bootstrap-servers}")
private String bootstrapAddress;
@Bean
public ProducerFactory<String, String> producerFactory() {
Map<String, Object> configProps = new HashMap<>();
configProps.put(
ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapAddress);
configProps.put(
ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
configProps.put(
ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
return new DefaultKafkaProducerFactory<>(configProps);
}
@Bean
public KafkaTemplate<String, String> kafkaTemplate() {
return new KafkaTemplate<>(producerFactory());
}
}尽管上面的类定义非常简单,但是我们仍然需要了解一些要点:
-
@Configuration:此类定义为配置类,这意味着该类将由Spring Boot自动选择,并且定义在该类内的所有bean将由Spring容器自动管理。 - 我们为
ProducerFactory定义了一个bean,该bean接受输入作为各种属性,例如Kafka服务器地址和其他序列化属性,这些属性有助于对通过Kafka生产者bean发送的消息进行编码和解码。 - 最后,我们为
KafkaTemplate定义了一个bean,它是实际的API对象,将用于在Kafka主题上发布消息。
10.定义使用者配置
当我们出于演示目的而在同一应用中制作Kafka生产者和消费者时,我们还将定义一个消费者配置类,该类仅包含Kafka消费者的基本属性。 可以将此类放在任何既不是生产者又仅仅是Kafka消费者的项目中,而无需进行任何更改。 让我们看一下配置定义:
KafkaConsumerConfig.java
package com.javacodegeeks.example.config;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.annotation.EnableKafka;
import org.springframework.kafka.config.ConcurrentKafkaListenerContainerFactory;
import org.springframework.kafka.core.ConsumerFactory;
import org.springframework.kafka.core.DefaultKafkaConsumerFactory;
import java.util.HashMap;
import java.util.Map;
@EnableKafka
@Configuration
public class KafkaConsumerConfig {
@Value("${spring.kafka.bootstrap-servers}")
private String bootstrapAddress;
@Value("${spring.kafka.consumer.group-id}")
private String groupId;
@Bean
public ConsumerFactory<String, String> consumerFactory() {
Map<String, Object> props = new HashMap<>();
props.put(
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapAddress);
props.put(
ConsumerConfig.GROUP_ID_CONFIG, groupId);
props.put(
ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
props.put(
ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
return new DefaultKafkaConsumerFactory<>(props);
}
@Bean
public ConcurrentKafkaListenerContainerFactory<String, String> kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<String, String> factory
= new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
return factory;
}
}我们提供的配置与生产者配置非常相似。 这里唯一要注意的区别是:
- 我们定义了一个
ConsumerFactory类对象bean,该对象bean同时考虑了该Kafka消费者应用程序所属的Kafka服务器地址和消费者组ID。 我们已经为消费者提供了唯一的字符串,因为只有唯一的字符串是可以接受的 - 最后,我们定义了
ConcurrentKafkaListenerContainerFactory,以确保此使用者应用程序可以并发的速度使用Kafka消息,并且即使已发布的消息数量很高,也可以提供一致的吞吐量。
11.定义Spring Boot类
在最后阶段,我们将使Spring Boot类用于发布消息,并在同一主题上使用消息。 这是主类的类定义:
KafkaApp.java
package com.javacodegeeks.example;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.boot.CommandLineRunner;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.core.KafkaTemplate;
@SpringBootApplication
public class KafkaApp implements CommandLineRunner {
private static final Logger LOG = LoggerFactory.getLogger("KafkaApp");
@Value("${message.topic.name}")
private String topicName;
private final KafkaTemplate<String, String> kafkaTemplate;
@Autowired
public KafkaApp(KafkaTemplate<String, String> kafkaTemplate) {
this.kafkaTemplate = kafkaTemplate;
}
public static void main(String[] args) {
SpringApplication.run(KafkaApp.class, args);
}
@Override
public void run(String... strings) {
kafkaTemplate.send(topicName, "Hello Geek!");
LOG.info("Published message to topic: {}.", topicName);
}
@KafkaListener(topics = "javacodegeeks", group = "jcg-group")
public void listen(String message) {
LOG.info("Received message in JCG group: {}", message);
}
} 我们使用了CommandLineRunner接口来使此类运行代码,从而可以测试所编写的生产者和配置类代码。 在此类中,我们将消息发布到指定的主题,并在同一类中定义的侦听器方法中侦听该消息。
在下一节中,我们将使用简单的Maven命令运行项目。
12.运行项目
既然完成了主类定义,我们就可以运行我们的项目。 使用maven可以轻松运行应用程序,只需使用以下命令:
运行项目
mvn spring-boot:run一旦执行了上面的命令,我们将看到一条消息已在指定主题上发布,并且同一应用程序也使用了该消息:
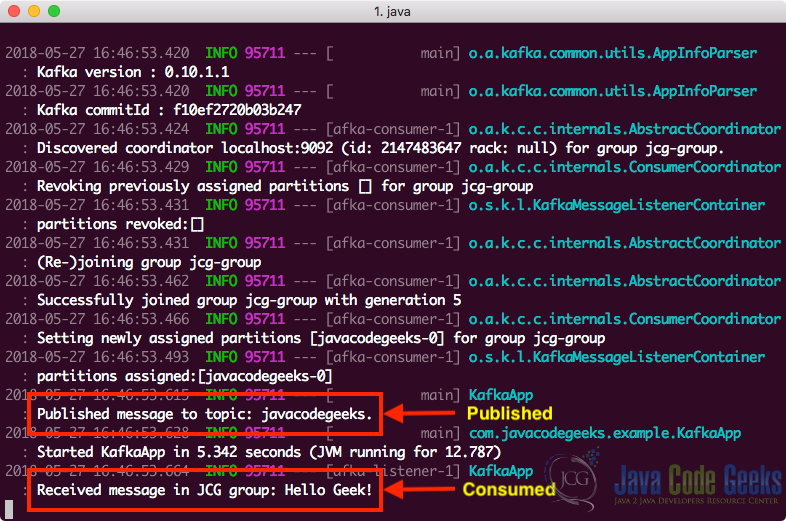
运行Spring Boot Kafka项目
13. Kafka分区
作为最后一个概念,我们将介绍如何在Apache Kafka中完成主题分区。 我们将从一个非常简单的说明性图像开始,该图像显示领导者在主题分区中的存在方式:
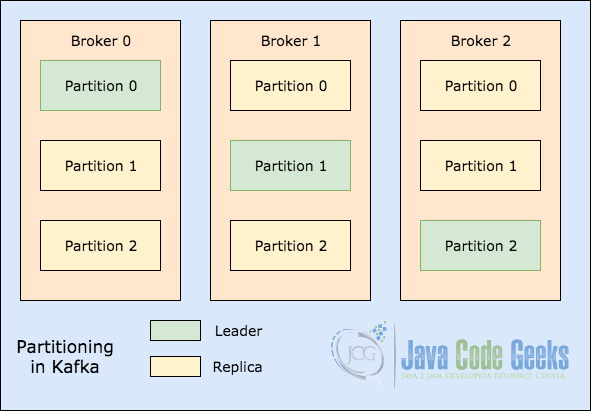
主题划分
当在Broker 0中的Partition 0是领导者的位置上写主题时,此数据将在节点之间复制,从而使消息保持安全。 这意味着将为上图中显示的所有三个代理在分区0之间复制消息。
Kafka中的复制过程是通过节点打开的多个线程并行完成的。 随着线程的开放以尽可能多地利用并行性,Kafka中获得了非常高的吞吐量系统。 将消息复制一定次数后, 将调用写入操作,但是消息的复制将继续进行,直到达到数据的复制因子为止。
14.结论
在本课程中,我们研究了构建集成有Apache Kafka的Spring Boot应用是多么容易和快捷。 Apache Kafka已从一个简单的Apache项目发展到一个生产级项目,当在其群集中以正确数量的节点进行部署,分配适当的内存并通过Zookeeper进行正确管理时,它每秒可以管理数百万个请求。 Apache Kafka是软件工程师工作中最有前途的技能之一,可以涵盖许多用例,例如网站跟踪,实时消息传递应用程序等等。
Apache Kafka可以管理有关其主题和分区的消息的规模确实很小,而使其具有如此高的可扩展性所需的体系结构路线也启发了许多其他项目。 它承诺提供的可扩展性和实时处理速度可确保它解决了需要非常扩展的项目中的许多问题。
15.下载源代码
这是Apache Kafka与Spring Framework集成的示例。
您可以在此处下载此示例的完整源代码: JCG-BootKafka-Example
翻译自: https://www.javacodegeeks.com/2018/05/spring-apache-kafka-tutorial.html















 2872
2872

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









