





在上一篇文章中,我们创建了一个简单的索引代码,该代码可以对ElasticSearch进行数千个并发请求。 监视系统性能的唯一方法是老式的日志记录语句:
.window(Duration.ofSeconds(1))
.flatMap(Flux::count)
.subscribe(winSize -> log.debug("Got {} responses in last second", winSize));很好,但是在生产系统上,我们宁愿有一些集中的监视和图表解决方案来收集各种指标。 一旦在数千个实例中拥有数百个不同的应用程序,这一点就变得尤为重要。 具有单个图形仪表板,汇总所有重要信息变得至关重要。 我们需要两个组件来收集一些指标:
- 发布指标
- 收集并可视化它们
使用Dropwizard指标发布指标
在Spring Boot 2中, Dropwizard指标被千分尺取代。 本文使用前者,下一个将在实践中显示后者的解决方案。 为了利用Dropwizard指标,我们必须将MetricRegistry或特定指标注入我们的业务类别。
import com.codahale.metrics.Counter;
import com.codahale.metrics.MetricRegistry;
import com.codahale.metrics.Timer;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
@Component
@RequiredArgsConstructor
class Indexer {
private final PersonGenerator personGenerator;
private final RestHighLevelClient client;
private final Timer indexTimer;
private final Counter indexConcurrent;
private final Counter successes;
private final Counter failures;
public Indexer(PersonGenerator personGenerator, RestHighLevelClient client, MetricRegistry metricRegistry) {
this.personGenerator = personGenerator;
this.client = client;
this.indexTimer = metricRegistry.timer(name("es", "index"));
this.indexConcurrent = metricRegistry.counter(name("es", "concurrent"));
this.successes = metricRegistry.counter(name("es", "successes"));
this.failures = metricRegistry.counter(name("es", "failures"));
}
private Flux<IndexResponse> index(int count, int concurrency) {
//....
}
}这么多样板,以添加一些指标!
-
indexTimer测量索引请求的时间分布(平均值,中位数和各种百分位数) -
indexConcurrent度量当前有多少个待处理的请求(已发送请求,尚未收到响应); 指标随时间上升和下降 -
success和failures计算相应的成功索引请求和失败索引请求的总数
我们将在一秒钟内删除样板,但首先,让我们看一下它在我们的业务代码中的作用:
private Mono<IndexResponse> indexDocSwallowErrors(Doc doc) {
return indexDoc(doc)
.doOnSuccess(response -> successes.inc())
.doOnError(e -> log.error("Unable to index {}", doc, e))
.doOnError(e -> failures.inc())
.onErrorResume(e -> Mono.empty());
}每次请求完成时,上述此辅助方法都会增加成功和失败的次数。 而且,它记录并吞下错误,因此单个错误或超时不会中断整个导入过程。
private <T> Mono<T> countConcurrent(Mono<T> input) {
return input
.doOnSubscribe(s -> indexConcurrent.inc())
.doOnTerminate(indexConcurrent::dec);
} 上面的另一种方法是在发送新请求时增加indexConcurrent指标,并在结果或错误到达时将其递减。 此指标不断上升和下降,显示进行中的请求数。
private <T> Mono<T> measure(Mono<T> input) {
return Mono
.fromCallable(indexTimer::time)
.flatMap(time ->
input.doOnSuccess(x -> time.stop())
);
} 最终的助手方法是最复杂的。 它测量编制索引的总时间,即发送请求和接收响应之间的时间。 实际上,它非常通用,它只是计算订阅任意Mono<T>到完成之间的总时间。 为什么看起来这么奇怪? 好吧,基本的Timer API非常简单
indexTimer.time(() -> someSlowCode()) 它只需要一个lambda表达式并测量调用它花费了多长时间。 另外,您可以创建一个小的Timer.Context对象,该对象可以记住创建时间。 当您调用Context.stop()它将报告此度量:
final Timer.Context time = indexTimer.time();
someSlowCode();
time.stop(); 使用异步流,要困难得多。 任务的开始(由预订表示)和完成通常发生在代码不同位置的线程边界上。 我们可以做的是(懒惰地)创建一个新的Context对象(请参阅: fromCallable(indexTimer::time) ),并在包装的流完成时,完成Context (请参阅: input.doOnSuccess(x -> time.stop() ))。这是您构成所有这些方法的方式:
personGenerator
.infinite()
.take(count)
.flatMap(doc ->
countConcurrent(measure(indexDocSwallowErrors(doc))), concurrency);就是这样,但是用这么多低级的度量收集细节污染业务代码似乎很奇怪。 让我们用专门的组件包装这些指标:
@RequiredArgsConstructor
class EsMetrics {
private final Timer indexTimer;
private final Counter indexConcurrent;
private final Counter successes;
private final Counter failures;
void success() {
successes.inc();
}
void failure() {
failures.inc();
}
void concurrentStart() {
indexConcurrent.inc();
}
void concurrentStop() {
indexConcurrent.dec();
}
Timer.Context startTimer() {
return indexTimer.time();
}
}现在,我们可以使用一些更高级的抽象:
class Indexer {
private final EsMetrics esMetrics;
private <T> Mono<T> countConcurrent(Mono<T> input) {
return input
.doOnSubscribe(s -> esMetrics.concurrentStart())
.doOnTerminate(esMetrics::concurrentStop);
}
//...
private Mono<IndexResponse> indexDocSwallowErrors(Doc doc) {
return indexDoc(doc)
.doOnSuccess(response -> esMetrics.success())
.doOnError(e -> log.error("Unable to index {}", doc, e))
.doOnError(e -> esMetrics.failure())
.onErrorResume(e -> Mono.empty());
}
}在下一篇文章中,我们将学习如何更好地组合所有这些方法。 并避免一些样板。
发布和可视化指标
仅仅收集指标是不够的。 我们必须定期发布汇总指标,以便其他系统可以使用,处理和可视化它们。 一种这样的工具是Graphite和Grafana 。 但是,在开始配置它们之前,让我们首先将指标发布到控制台。 我发现在对度量进行故障排除或开发时特别有用。
import com.codahale.metrics.MetricRegistry;
import com.codahale.metrics.Slf4jReporter;
@Bean
Slf4jReporter slf4jReporter(MetricRegistry metricRegistry) {
final Slf4jReporter slf4jReporter = Slf4jReporter.forRegistry(metricRegistry.build();
slf4jReporter.start(1, TimeUnit.SECONDS);
return slf4jReporter;
} 这个简单的代码片段采用现有的MetricRegistry并注册Slf4jReporter 。 每秒您将看到所有度量标准被打印到日志中(Logback等):
type=COUNTER, name=es.concurrent, count=1
type=COUNTER, name=es.failures, count=0
type=COUNTER, name=es.successes, count=1653
type=TIMER, name=es.index, count=1653, min=1.104664, max=345.139385, mean=2.2166538118720576,
stddev=11.208345077801448, median=1.455504, p75=1.660252, p95=2.7456, p98=5.625456, p99=9.69689, p999=85.062713,
mean_rate=408.56403102372764, m1=0.0, m5=0.0, m15=0.0, rate_unit=events/second, duration_unit=milliseconds 但这仅仅是为了解决问题,为了将指标发布到外部Graphite实例,我们需要一个GraphiteReporter :
import com.codahale.metrics.MetricRegistry;
import com.codahale.metrics.graphite.Graphite;
import com.codahale.metrics.graphite.GraphiteReporter;
@Bean
GraphiteReporter graphiteReporter(MetricRegistry metricRegistry) {
final Graphite graphite = new Graphite(new InetSocketAddress("localhost", 2003));
final GraphiteReporter reporter = GraphiteReporter.forRegistry(metricRegistry)
.prefixedWith("elastic-flux")
.convertRatesTo(TimeUnit.SECONDS)
.convertDurationsTo(TimeUnit.MILLISECONDS)
.build(graphite);
reporter.start(1, TimeUnit.SECONDS);
return reporter;
} 在这里,我向localhost:2003报告,其中带有Graphite + Grafana的Docker镜像恰好在其中。 每秒将所有度量标准发送到该地址。 我们稍后可以在Grafana上可视化所有这些指标:
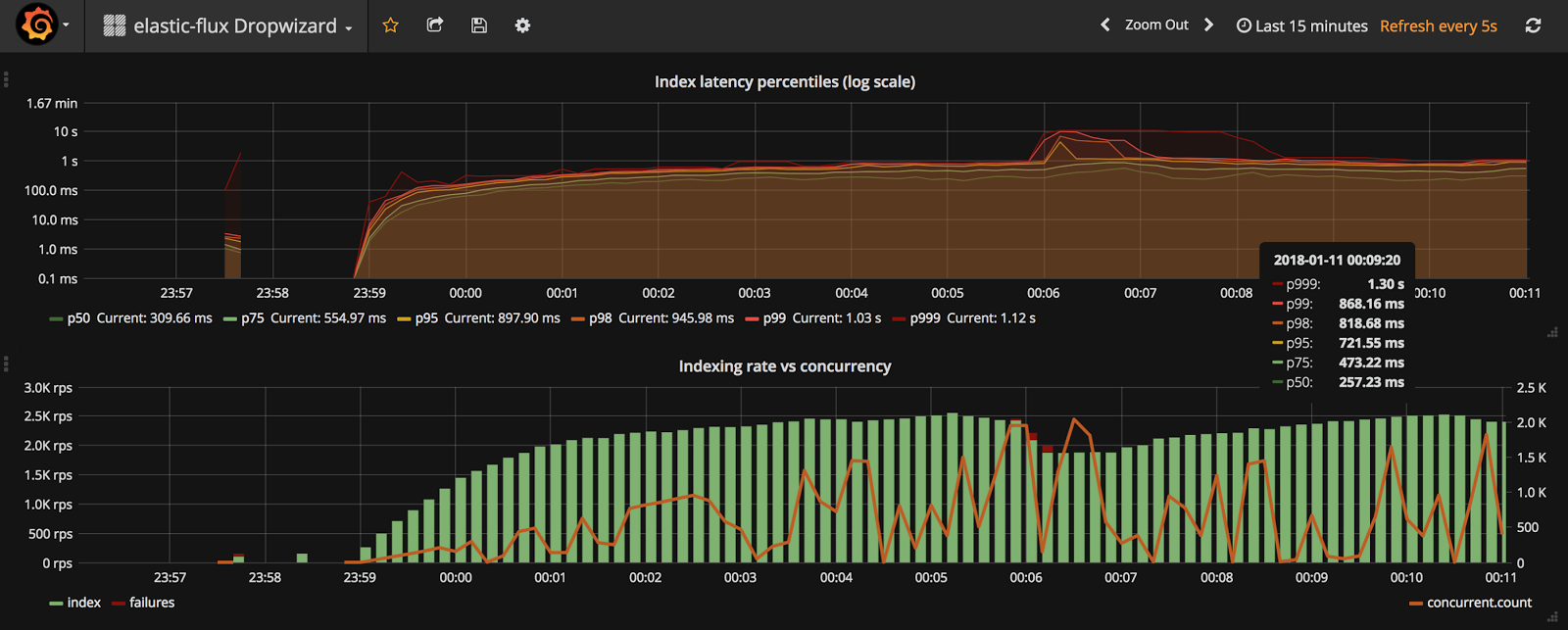
上图显示了索引时间分布(从第50个百分位数到第99.9个百分位数)。 使用此图,您可以快速发现典型性能(P50)和(几乎)最坏情况的性能(P99.9)。 对数标度是不寻常的,但是在这种情况下,我们可以看到上下百分位。 底部图更加有趣。 它结合了三个指标:
- 成功执行索引操作的速率(每秒请求数)
- 操作失败率(红色条,堆叠在绿色条上)
- 当前并发级别(右轴):进行中的请求数
此图显示了系统吞吐量(RPS),故障和并发性。 故障太多或并发级别异常高(许多操作正在等待响应)可能表明您的系统存在某些问题。 仪表板定义在GitHub存储库中可用。
在下一篇文章中,我们将学习如何从Dropwizard指标迁移到微米。 一个非常愉快的经历!














 568
568











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









