





如果需要从Java解析语言或文档,则从根本上讲有三种方法可以解决问题:
- 使用支持该特定语言的现有库:例如用于解析XML的库
- 手动构建自己的自定义解析器
- 生成解析器的工具或库:例如ANTLR,可用于构建任何语言的解析器
使用现有库
第一种选择最适合众所周知和受支持的语言,例如XML或HTML 。 一个好的库通常还包括API,以编程方式构建和修改该语言的文档。 这通常是您从基本解析器获得的更多信息。 问题在于这样的库不是很常见,它们仅支持最常见的语言。 在其他情况下,您不走运。
手动构建自己的自定义解析器
如果您有特殊需要,可能需要选择第二种方法。 从某种意义上说,您需要解析的语言无法用传统的解析器生成器解析,或者您有使用典型解析器生成器无法满足的特定要求。 例如,因为您需要最佳的性能或不同组件之间的深度集成。
生成解析器的工具或库
在所有其他情况下,第三个选项应为默认选项,因为这是最灵活的且开发时间较短的选项。 这就是为什么在本文中我们将重点放在与该选项相对应的工具和库上的原因。
创建解析器的工具
我们将看到:
- 可以生成可从Java(以及可能从其他语言)使用的解析器的工具
- Java库来构建解析器
可用于生成解析器代码的工具称为解析器生成器或编译器编译器 。 创建解析器的库称为解析器组合器 。
解析器生成器(或解析器组合器)并不简单:您需要一些时间来学习如何使用它们,并且并非所有类型的解析器生成器都适用于所有类型的语言。 这就是为什么我们准备了其中最知名的清单,并对每个清单进行了简短介绍。 我们还专注于一种目标语言:Java。 这也意味着(通常)解析器本身将用Java编写。
列出所有语言的所有可能的工具和库解析器会很有趣,但没那么有用。 那是因为会有太多简单的选择,而我们都会迷失其中。 通过专注于一种编程语言,我们可以进行逐个比较,并帮助您为项目选择一个选项。
有关解析器的有用信息
为了确保所有程序员都可以访问这些列表,我们为搜索语法分析器可能遇到的术语和概念作了简短说明。 我们不是在给您正式的解释,而是实际的解释。
解析器的结构
解析器通常由两部分组成: lexer (也称为扫描器或令牌生成器 )和适当的解析器。 并非所有解析器都采用这种两步模式:某些解析器不依赖词法分析器。 它们称为无扫描程序解析器 。
一个词法分析器和一个解析器按顺序工作:词法分析器扫描输入并生成匹配的令牌,解析器扫描令牌并生成解析结果。
让我们看下面的示例,并想象我们正在尝试解析数学运算。
437 + 734 词法分析器扫描文本,然后找到“ 4”,“ 3”,“ 7”,然后找到空格“”。 词法分析器的工作是识别第一个字符构成NUM类型的一个标记。 然后,词法分析器找到一个'+'符号,它对应于PLUS类型的第二个令牌,最后找到另一个NUM类型的令牌。 
解析器通常将组合词法分析器生成的令牌并将其分组。
词法分析器或解析器使用的定义称为规则或产生式 。 词法分析器规则将指定数字序列与NUM类型的令牌相对应,而分析器规则将指定数字序列NUM,PLUS,NUM类型的令牌与表达式相对应。
无扫描程序的解析器是不同的,因为它们直接处理原始文本,而不是处理由词法分析器生成的令牌列表。
现在通常会找到可以生成词法分析器和解析器的套件。 过去,更常见的是将两种不同的工具结合在一起:一种用于生成词法分析器,另一种用于生成解析器。 例如,古老的lex&yacc夫妇就是这种情况:lex生成了lexer,而yacc生成了解析器。
解析树和抽象语法树
有两个相关的术语,有时可以互换使用:解析树和抽象语法树(AST)。
从概念上讲,它们非常相似:
- 它们都是树 :有一个表示整个已解析代码的根。 然后有较小的子树表示代码的一部分,这些子树变得越来越小,直到树中出现单个令牌为止
- 区别在于抽象级别:分析树包含程序中出现的所有标记以及可能的一组中间规则。 AST而是解析树的完善版本,其中删除了可能衍生或对于理解代码段不重要的信息
在AST中,某些信息会丢失,例如,注释和分组符号(括号)未显示。 对于程序来说,诸如注释之类的东西是多余的,而分组符号则由树的结构隐式定义。
解析树是更接近具体语法的代码表示。 它显示了解析器实现的许多细节。 例如,规则通常对应于节点的类型。 通常,在解析器生成器的帮助下,用户通常将其转换为AST。
AST的图形表示如下所示。
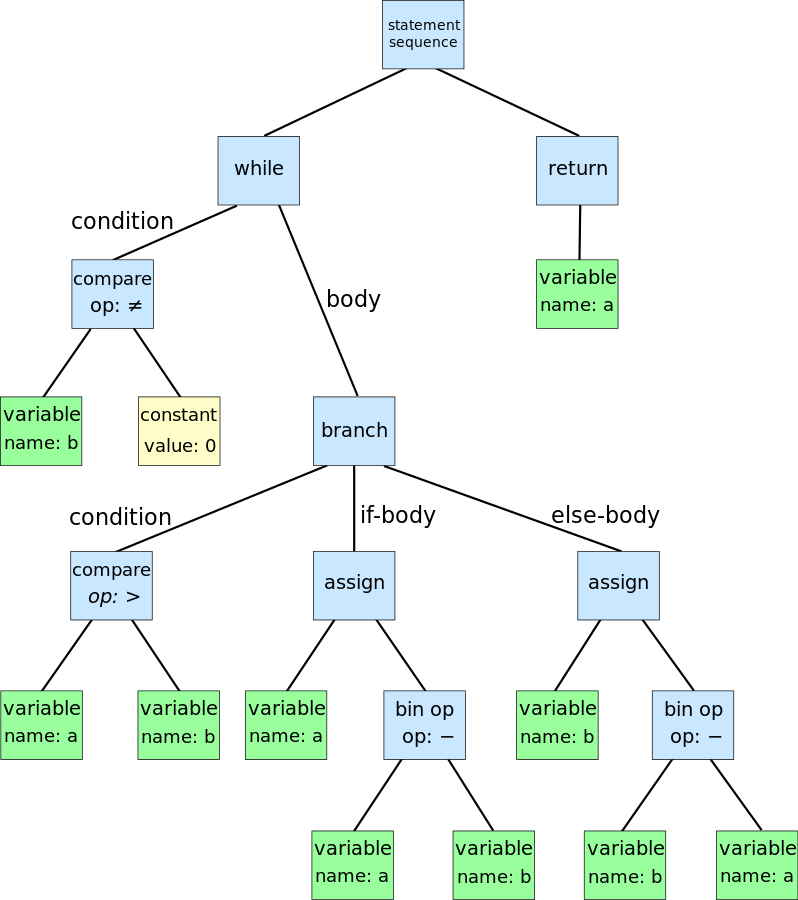
有时您可能想开始生成一个解析树,然后从中派生AST。 这是有道理的,因为解析树更易于为解析器生成(它是解析过程的直接表示),但是AST更简单且易于通过以下步骤进行处理。 通过执行以下步骤,我们表示您可能希望在树上执行的所有操作:代码验证,解释,编译等。
语法
语法是对语言的形式描述,可用于识别其结构。
简而言之,是一列定义如何构造每个构造的规则列表。 例如,if语句的规则可以指定它必须以“ if”关键字开头,后跟左括号,表达式,右括号和语句。
规则可以引用其他规则或令牌类型。 在if语句的示例中,关键字“ if”,左括号和右括号是标记类型,而expression和statement是对其他规则的引用。
描述语法最常用的格式是Backus-Naur形式(BNF) ,它也有很多变体,包括Extended Backus-Naur形式 。 Extented变体的优点是包括一种表示重复的简单方法。 Backus-Naur语法中的典型规则如下所示:
<symbol> ::= __expression__ <simbol>通常是非终结符,这意味着可以用右边的元素组__expression__ 。 元素__expression__可以包含其他非终止符号或终止符号。 终端符号只是在语法中的任何地方都不会显示为<symbol> 。 终端符号的典型示例是一串字符,例如“ class”。
左递归规则
在解析器的上下文中,一个重要功能是对左递归规则的支持。 这意味着规则可以从对自身的引用开始。 此引用也可以是间接的。
考虑例如算术运算。 一个加法可以描述为两个用加号(+)分隔的表达式,但是一个表达式也可以包含其他加法。
addition ::= expression '+' expression
multiplication ::= expression '*' expression
// an expression could be an addition or a multiplication or a number
expression ::= addition | multiplication |// a number此描述还匹配5 + 4 + 3之类的多个加法项。这是因为它可以解释为表达式(5)('+')expression(4 + 3)。 然后4 + 3本身可以分为两个部分。
问题是这种规则可能无法与某些解析器生成器一起使用。 另一种选择是一长串表达式,它还要注意运算符的优先级。
一些解析器生成器支持直接的左递归规则,但不支持间接的规则。
语言和文法的类型
我们主要关心的是可以使用解析器生成器解析的两种类型的语言: 常规语言和无上下文语言 。 我们可以根据乔姆斯基语言的层次结构为您提供正式的定义,但是它没有那么有用。 让我们来看一些实际的方面。
常规语言可以由一系列常规表达式定义,而无上下文的语言则需要更多。 一个简单的经验法则是,如果一种语言的语法具有递归元素,则它不是常规语言。 例如,正如我们在其他地方所说, HTML不是常规语言 。 实际上,大多数编程语言都是上下文无关的语言。
通常对一种语言对应一种语法。 也就是说,存在分别对应于常规和无上下文语言的常规语法和无上下文语法。 但是使事情变得复杂的是,有一种相对较新的语法(创建于2004年),称为解析表达语法(PEG)。 这些语法与无上下文语法一样强大,但是根据他们的作者,他们描述了更自然的编程语言。
PEG和CFG的区别
PEG和CFG之间的主要区别在于,选择的顺序在PEG中有意义,而在CFG中没有意义。 如果有许多可能的有效方法来解析输入,则CFG会模棱两可,因此是错误的。 取而代之的是,将选择第一个适用的PEG,这将自动解决一些歧义。
另一个区别是PEG使用无扫描器解析器:它们不需要单独的词法分析器或词法分析阶段。
传统上,PEG和某些CFG都无法处理左递归规则,但是一些工具已找到解决方法。 通过修改基本的解析算法,或者使该工具以非递归方式自动重写左递归规则。 这两种方法都有缺点:要么使生成的解析器难以理解,要么使其性能变差。 但是,实际上,更容易,更快的开发的优点胜于缺点。
解析器生成器
解析器生成器工具的基本工作流程非常简单:编写定义语言或文档的语法,然后运行该工具以生成可从Java代码使用的解析器。
解析器可能会生成AST,您可能必须遍历自己,也可以使用其他现成的类(例如Listeners或Visitors)来遍历。 相反,有些工具提供了将代码嵌入语法中的机会,以便在每次匹配特定规则时都执行该代码。
通常,您需要运行时库和/或程序才能使用生成的解析器。
常规(词法分析器)
分析常规语言的工具通常是词法分析器。
JFlex
JFlex是基于确定性有限自动机(DFA)的词法分析器(lexer)生成器。 JFlex词法分析器根据定义的语法(称为规范)匹配输入,并执行相应的操作(嵌入在语法中)。
它可以用作独立工具,但作为词法分析器生成器旨在与解析器生成器一起使用:通常与CUP或BYacc / J一起使用。 它也可以与ANTLR一起使用。
典型的语法(规范)分为三部分,以'%%'分隔:
- 用户代码,该代码将包含在生成的类中,
- 选项/宏,
- 最后是词法分析器规则。
JFlex规范文件
// taken from the documentation
/* JFlex example: partial Java language lexer specification */
import java_cup.runtime.*;
%%
// second section
%class Lexer
%unicode
%cup
[..]
LineTerminator = \r|\n|\r\n
%%
// third section
/* keywords */
<YYINITIAL> "abstract" { return symbol(sym.ABSTRACT); }
<YYINITIAL> "boolean" { return symbol(sym.BOOLEAN); }
<YYINITIAL> "break" { return symbol(sym.BREAK); }
<STRING> {
\" { yybegin(YYINITIAL);
return symbol(sym.STRING_LITERAL,
string.toString()); }
[..]
}
/* error fallback */
[^] { throw new Error("Illegal character <"+
yytext()+">"); }上下文无关
让我们看看生成上下文无关解析器的工具。
ANTLR可能是Java最常用的解析器生成器。 ANTLR基于作者开发的新LL算法,并在本文中进行了描述: 自适应LL(*)解析:动态分析的能力(PDF) 。
它可以输出多种语言的解析器。 但是广大社区的真正附加值是大量可用的语法 。 版本4支持直接的左递归规则。
它提供了两种遍历AST的方式,而不是将动作嵌入语法中:访问者和听众。 第一个适用于您必须操纵树的元素或与之交互的情况,而第二个适用于在规则匹配时只需要做一些事情的情况。
典型的语法分为两部分:词法分析器规则和解析器规则。 该划分是隐式的,因为所有以大写字母开头的规则都是词法分析器规则,而以小写字母开头的规则是解析器规则。 另外,可以在单独的文件中定义词法分析器和解析器语法。
一个非常简单的ANTLR语法
grammar simple;
basic : NAME ':' NAME ;
NAME : [a-zA-Z]* ;
COMMENT : '/*' .*? '*/' -> skip ;如果您对ANTLR感兴趣,可以查看我们编写的这个庞大的ANTLR教程 。
APG
APG是一种递归下降解析器,它使用了增强BNF的变体,他们称之为超集增强BNF。 ABNF是BNF的特定变体,旨在更好地支持双向通信协议。 APG还支持其他运算符,例如语法谓词和自定义用户定义的匹配函数。
它可以使用C / C ++,Java e JavaScript生成解析器。 对最后一种语言的支持似乎更好,并且是最新的:它具有更多功能,并且似乎已更新。 实际上,文档说它的设计具有JavaScript RegExp的外观。
因为它是基于ABNF的,所以它特别适合解析许多Internet技术规范的语言,并且实际上是许多大型电信公司的首选解析器。
APG语法非常简洁易懂。
APG语法
// example from a tutorial of the author of the tool available here
// https://www.sitepoint.com/alternative-to-regular-expressions/
phone-number = ["("] area-code sep office-code sep subscriber
area-code = 3digit ; 3 digits
office-code = 3digit ; 3 digits
subscriber = 4digit ; 4 digits
sep = *3(%d32-47 / %d58-126 / %d9) ; 0-3 ASCII non-digits
digit = %d48-57 ; 0-9BYACC / J
BYACC是生成Java代码的Yacc。 这就是整个想法,它定义了它的优点和缺点。 众所周知,它可以更轻松地将Yacc和C程序转换为Java程序。 尽管显然您仍然需要将语义动作中嵌入的所有C代码转换为Java代码。 另一个优点是您不需要单独的运行时,生成的解析器便是您所需要的。
另一方面,它已经很老了,解析世界已经取得了很多进步。 如果您是经验丰富的Yacc开发人员,并且具有要升级的代码库,那么这是个不错的选择,否则,您应该考虑使用更多现代替代方案。
典型的语法分为三部分,以'%%'分隔:声明,操作和代码。 第二个包含语法规则,第三个包含自定义用户代码。
BYacc语法
// from the documentation
%{
import java.lang.Math;
import java.io.*;
import java.util.StringTokenizer;
%}
/* YACC Declarations */
%token NUM
%left '-' '+'
%left '*' '/'
%left NEG /* negation--unary minus */
%right '^' /* exponentiation */
/* Grammar follows */
%%
input: /* empty string */
| input line
;
line: '\n'
| exp '\n' { System.out.println(" " + $1.dval + " "); }
;
%%
public static void main(String args[])
{
Parser par = new Parser(false);
[..]
}可可/ R
Coco / R是一个编译器生成器,它采用属性语法并生成扫描器和递归下降解析器。 属性语法意味着可以多种方式对以EBNF变体编写的规则进行注释,以更改生成的解析器的方法。
扫描程序包括处理诸如编译指示之类的编译指示的支持。 解析器可以忽略它们,而自定义代码可以处理它们。 扫描仪也可以被压制,并用手动构建的扫描仪代替。
从技术上讲,所有语法都必须为LL(1),也就是说,解析器必须能够仅在前面看一个符号的情况下选择正确的规则。 但是Coco / R提供了几种绕过此限制的方法,包括语义检查,这些检查基本上是必须返回布尔值的自定义函数。 该手册还提供一些建议,以重构您的代码以遵守此限制。
Coco / R语法如下所示。
Coco / R语法
[Imports]
// ident is the name of the grammar
"COMPILER" ident
// this includes arbitrary fields and method in the target language (eg. Java)
[GlobalFieldsAndMethods]
// ScannerSpecification
CHARACTERS
[..]
zero = '0'.
zeroToThree = zero + "123" .
octalDigit = zero + "1234567" .
nonZeroDigit = "123456789".
digit = '0' + nonZeroDigit .
[..]
TOKENS
ident = letter { letter | digit }.
[..]
// ParserSpecification
PRODUCTIONS
// just a rule is shown
IdentList =
ident <out int x> (. int n = 1; .)
{',' ident (. n++; .)
} (. Console.WriteLine("n = " + n); .)
.
// end
"END" ident '.'Coco / R有一个很好的文档,并提供了一些示例语法。 它支持多种语言,包括Java,C#和C ++。
CookCC
CookCC是用Java编写的LALR(1)解析器生成器。 可以用三种不同的方式指定语法:
- 以Yacc格式:它可以读取为Yacc定义的语法
- 以自己的XML格式
- 通过使用特定注释在Java代码中
一个独特的功能是它还可以输出Yacc语法。 如果您需要与支持Yacc语法的工具进行交互,这将非常有用。 就像一些旧的C程序,您必须与之保持兼容性。
它需要Java 7来生成解析器,但是它可以在早期版本上运行。
使用注释定义的典型解析器将如下所示。
CookCC解析器
// required import
import org.yuanheng.cookcc.*;
@CookCCOption (lexerTable = "compressed", parserTable = "compressed")
// the generated parser class will be a parent of the one you define
// in this case it will be "Parser"
public class Calculator extends Parser
{
// code
// a lexer rule
@Shortcuts ( shortcuts = {
@Shortcut (name="nonws", pattern="[^ \\t\\n]"),
@Shortcut (name="ws", pattern="[ \\t]")
})
@Lex (pattern="{nonws}+", state="INITIAL")
void matchWord ()
{
m_cc += yyLength ();
++m_wc;
}
// a typical parser rules
@Rule (lhs = "stmt", rhs = "SEMICOLON")
protected Node parseStmt ()
{
return new SemiColonNode ();
}
}对于解析器生成器的标准,使用Java批注是一个奇特的选择。 与诸如ANTLR之类的替代方法相比,语法和动作之间的划分肯定不够清晰。 这可能会使解析器更难以维护复杂的语言。 另外移植到另一种语言可能需要完全重写。
另一方面,这种方法允许将语法规则与匹配规则时要执行的动作混合在一起。 此外,由于它只是Java代码,因此具有集成到您选择的IDE中的优势。
杯子
CUP是“有用的解析器构造”的缩写,它是Java的LALR解析器生成器。 它只是生成正确的解析器部分,但非常适合与JFlex一起使用。 尽管显然您也可以手动构建词法分析器以与CUP一起使用。 语法具有类似于Yacc的语法,并且允许为每个规则嵌入代码。
它可以自动生成一个分析树,但不能自动生成一个AST。
它还具有一个Eclipse插件来帮助您创建语法,因此有效地具有其自己的IDE。
典型的语法类似于YACC。
CUP语法
// example from the documentation
// CUP specification for a simple expression evaluator (w/ actions)
import java_cup.runtime.*;
/* Preliminaries to set up and use the scanner. */
init with {: scanner.init(); :};
scan with {: return scanner.next_token(); :};
/* Terminals (tokens returned by the scanner). */
terminal SEMI, PLUS, MINUS, TIMES, DIVIDE, MOD;
terminal UMINUS, LPAREN, RPAREN;
terminal Integer NUMBER;
/* Non-terminals */
non terminal expr_list, expr_part;
non terminal Integer expr;
/* Precedences */
precedence left PLUS, MINUS;
precedence left TIMES, DIVIDE, MOD;
precedence left UMINUS;
/* The grammar */
expr_list ::= expr_list expr_part
|
expr_part;
expr_part ::= expr:e
{: System.out.println("= " + e); :}
SEMI
;
[..]语法学
Grammatica是C#和Java解析器生成器(编译器编译器)。 它读取语法文件(采用EBNF格式),并为解析器创建注释清晰且易于阅读的C#或Java源代码。 它支持LL(k)语法,自动错误恢复,可读错误消息以及语法和源代码之间的清晰分隔。
Grammatica网站上的描述本身就是Grammatica的一个很好的代表:简单易用,文档完善,功能丰富。 您可以通过对生成的类进行子类化来构建侦听器,但不能对访问者进行子类化。 有很好的参考,但例子并不多。
Grammatica的典型语法分为三个部分:标头,标记和产生式。 它也很干净,几乎和ANTLR一样。 尽管格式略有不同,但它也基于类似的扩展BNF。
语法语法
%header%
GRAMMARTYPE = "LL"
[..]
%tokens%
ADD = "+"
SUB = "-"
[..]
NUMBER = <<[0-9]+>>
WHITESPACE = <<[ \t\n\r]+>> %ignore%
%productions%
Expression = Term [ExpressionTail] ;
ExpressionTail = "+" Expression
| "-" Expression ;
Term = Factor [TermTail] ;
[..]
Atom = NUMBER
| IDENTIFIER ;雅克
Jacc与BYACC / J相似,不同之处在于Jacc是用Java编写的,因此它可以在程序可以运行的任何地方运行。 根据经验,它是作为Yacc的更新版本开发的。 作者介绍了在错误消息,模块化和调试支持等方面的小改进。
如果您知道Yacc并且没有任何代码库可升级,那么它可能是一个不错的选择。
JavaCC
JavaCC是另一种广泛使用的Java解析器生成器。 语法文件包含动作和解析器所需的所有自定义代码。
与ANTLR相比,语法文件不那么干净,并且包含许多Java源代码。
JavaCC语法
javacc_options
// "PARSER_BEGIN" "(" <IDENTIFIER> ")"
PARSER_BEGIN(SimpleParser)
public final class SimpleParser { // Standard parser class setup...
public static void main(String args[]) {
SimpleParser parser;
java.io.InputStream input;
}
PARSER_END(SimpleParser)
// the rules of the grammar
// token rules
TOKEN :
{
< #DIGIT : ["0"-"9"] >
| < #LETTER : ["A"-"Z","a"-"z"] >
| < IDENT : <LETTER> (<LETTER> | <DIGIT>)* >
[..]
}
SKIP : { " " | "\t" | "\n" | "\r" }
// parser rules
[..]
void IdentDef() : {}
{
<IDENT> ("*" | "-")?
}由于其悠久的历史,它被用于JavaParser等重要项目。 这在文档和用法上有一些古怪之处。 例如,从技术上讲,JavaCC本身并不构建AST,但是它附带了一个可实现AST的工具JTree,因此它确实可以构建。
有一个语法存储库 ,但其中没有很多语法。 它需要Java 5或更高版本。
型号CC
ModelCC是基于模型的解析器生成器,可将语言规范与语言处理[..]分离。 ModelCC接收概念模型作为输入,以及对其进行注释的约束。
实际上,您可以使用注释定义语言的模型,该模型在Java中用作语法。 然后,将创建的模型提供给ModelCC,以获取解析器。
使用ModelCC,您可以独立于所使用的解析算法来定义语言。 相反,它应该是语言的最佳概念表示。 尽管它在后台使用了传统的解析算法。 因此,语法本身使用独立于任何解析算法的形式,但是ModelCC并不使用魔术,而是生成普通的解析器。
对于工具作者的意图有明确的描述,但是文档有限。 尽管如此,还是有可用的示例,包括下面部分显示的计算器模型。
public abstract class Expression implements IModel {
public abstract double eval();
}
[..]
public abstract class UnaryOperator implements IModel {
public abstract double eval(Expression e);
}
[..]
@Pattern(regExp="-")
public class MinusOperator extends UnaryOperator implements IModel {
@Override public double eval(Expression e) { return -e.eval(); }
}
@Associativity(AssociativityType.LEFT_TO_RIGHT)
public abstract class BinaryOperator implements IModel {
public abstract double eval(Expression e1,Expression e2);
}
[..]
@Priority(value=2)
@Pattern(regExp="-")
public class SubtractionOperator extends BinaryOperator implements IModel {
@Override public double eval(Expression e1,Expression e2) { return e1.eval()-e2.eval(); }
}
[..]SableCC
SableCC是为论文而创建的解析器生成器,目的是易于使用并在语法和Java代码之间提供清晰的分隔。 第3版还应该提供一种包括在内的现成的使用访客走AST的方式。 但这只是理论上的全部,因为实际上没有文档,而且我们也不知道如何使用这些东西。
此外,第4版于2015年开始发布,显然已被放弃。
UrchinCC
Urchin(CC)是一种解析器生成器,可用于定义称为Urchin解析器定义的语法。 然后,您从中生成一个Java解析器。 Urchin还从UPD吸引了一位访客。
这里有详尽的教程,还可以用来解释Urchin的工作原理及其局限性,但是手册内容有限。
UPD分为三个部分:终端,令牌和规则。
UPD文件
terminals {
Letters ::= 'a'..'z', 'A'..'Z';
Digits ::= '0'..'9';
}
token {
Space ::= [' ', #8, #9]*1;
EOLN ::= [#10, #13];
EOF ::= [#65535];
[..]
Identifier ::= [Letters] [Letters, Digits]*;
}
rules {
Variable ::= "var", Identifier;
Element ::= Number | Identifier;
PlusExpression ::= Element, '+', Expression;
[..]
}聚乙二醇
在CFG解析器之后,就该看看Java中可用的PEG解析器了。
天篷
Canopy是针对Java,JavaScript,Python和Ruby的解析器编译器。 它获取一个描述解析表达式语法的文件,并将其编译为目标语言的解析器模块。 生成的解析器对Canopy本身没有运行时依赖性。
它还提供了对解析树节点的轻松访问。
Canopy语法具有使用动作注释在解析器中使用自定义代码的简洁功能。 实际上。 您只需在规则旁边写一个函数的名称,然后在源代码中实现该函数。
带动作的冠层语法
// the actions are prepended by %
grammar Maps
map <- "{" string ":" value "}" %make_map
string <- "'" [^']* "'" %make_string
value <- list / number
list <- "[" value ("," value)* "]" %make_list
number <- [0-9]+ %make_number包含操作代码的Java文件。
[..]
import maps.Actions;
[..]
class MapsActions implements Actions {
public Pair make_map(String input, int start, int end, List<TreeNode> elements) {
Text string = (Text)elements.get(1);
Array array = (Array)elements.get(3);
return new Pair(string.string, array.list);
}
[..]
}拉贾
Laja是一个两阶段的无扫描器,自顶向下,回溯解析器生成器,支持运行时语法规则。
Laja是代码生成器和解析器生成器,主要用于创建外部DSL。 这意味着它具有一些独特的功能。 使用Laja,您不仅必须指定数据的结构,还必须指定如何将数据映射到Java结构中。 这种结构通常是层次结构或平面组织中的对象。 简而言之,它使解析数据文件变得非常容易,但是不太适合通用编程语言。
Laja选项(例如输出目录或输入文件)在配置文件中设置。
Laja语法分为规则部分和数据映射部分。 看起来像这样。
Laja语法
// this example is from the documentation
grammar example {
s = [" "]+;
newline = "\r\n" | "\n";
letter = "a".."z";
digit = "0".."9";
label = letter [digit|letter]+;
row = label ":" s [!(newline|END)+]:value [newline];
example = row+;
Row row.setLabel(String label);
row.setValue(String value);
Example example.addRow(Row row);
}老鼠
鼠标是将PEG转录为用Java编写的可执行解析器的工具。
它不使用packrat,因此它比典型的PEG解析器使用更少的内存(该手册将Mouse和Rats进行了显式比较!)。
它没有语法存储库,但是有适用于Java 6-8和C的语法。
鼠标语法很干净。 要包含自定义代码(一种称为语义谓词)的功能,您需要执行与Canopy中相似的操作。 您在语法中包含一个名称,然后在Java文件中实际编写自定义代码。
鼠标语法
// example from the manual
// http://mousepeg.sourceforge.net/Manual.pdf
// the semantics are between {}
Sum = Space Sign Number (AddOp Number)* !_ {sum} ;
Number = Digits Space {number} ;
Sign = ("-" Space)? ;
AddOp = [-+] Space ;
Digits = [0-9]+ ;
Space = " "* ;老鼠!
老鼠! 是xtc(eXTensible编译器)的解析器生成器部分。 它基于PEG,但是使用“生成实际解析器所必需的附加表达式和运算符”。 它支持左递归生产。 它可以自动生成AST。
它需要Java 6或更高版本。
语法可能很简洁,但是您可以在每次制作后嵌入自定义代码。
老鼠! 语法
// example from Introduction to the Rats! Parser Generator
// http://cs.nyu.edu/courses/fall11/CSCI-GA.2130-001/rats-intro.pdf
/* module intro */
module Simple;
option parser(SimpleParser);
/* productions for syntax analysis */
public String program = e:expr EOF { yyValue = e; } ;
String expr = t:term r:rest { yyValue = t + r; } ;
String rest = PLUS t:term r:rest { yyValue = t + "+" + r; }
/ MINUS t:term r:rest { yyValue = t + "-" + r; }
/ /*empty*/ { yyValue = ""; } ;
String term = d:DIGIT { yyValue = d; } ;
/* productions for lexical analysis */
void PLUS = "+";
void MINUS = "-";
String DIGIT = [0-9];
void EOF = ! ;解析器组合器
通过组合与语法规则等效的不同模式匹配功能,它们使您可以简单地用Java代码创建解析器。 通常认为它们适合于更简单的解析需求。 由于它们只是Java库,因此您可以轻松地将它们引入项目中:您不需要任何特定的生成步骤,并且可以在自己喜欢的Java编辑器中编写所有代码。 它们的主要优点是可以集成到传统工作流程和IDE中。
实际上,这意味着它们对于您发现的所有小解析问题都非常有用。 如果典型的开发人员遇到问题(对于简单的正则表达式而言过于复杂),则通常可以使用这些库。 简而言之,如果您需要构建解析器,但实际上并不需要,解析器组合器可能是您的最佳选择。
Jparsec
Jparsec是Haskell的parsec库的端口。
解析器组合器通常在一个阶段中使用,也就是说它们没有词法分析器。 这仅仅是因为它很快变得太复杂而无法直接在代码中管理所有组合器链。 话虽这么说,jparsec有一个特殊的类来支持词法分析。
它不支持左递归规则,但是它为最常见的用例提供了一个特殊的类:管理运算符的优先级。
用jparsec编写的典型解析器与此类似。
使用Jparsec的计算器解析器
// from the documentation
public class Calculator {
static final Parser<Double> NUMBER =
Terminals.DecimalLiteral.PARSER.map(Double::valueOf);
private static final Terminals OPERATORS =
Terminals.operators("+", "-", "*", "/", "(", ")");
[..]
static final Parser<?> TOKENIZER =
Parsers.or(Terminals.DecimalLiteral.TOKENIZER, OPERATORS.tokenizer());
[..]
static Parser<Double> calculator(Parser<Double> atom) {
Parser.Reference<Double> ref = Parser.newReference();
Parser<Double> unit = ref.lazy().between(term("("), term(")")).or(atom);
Parser<Double> parser = new OperatorTable<Double>()
.infixl(op("+", (l, r) -> l + r), 10)
.infixl(op("-", (l, r) -> l - r), 10)
.infixl(Parsers.or(term("*"), WHITESPACE_MUL).retn((l, r) -> l * r), 20)
.infixl(op("/", (l, r) -> l / r), 20)
.prefix(op("-", v -> -v), 30)
.build(unit);
ref.set(parser);
return parser;
}
public static final Parser<Double> CALCULATOR =
calculator(NUMBER).from(TOKENIZER, IGNORED);
}煮熟的
Parboiled提供了递归下降PEG解析器实现,该实现可对您指定的PEG规则进行操作。
煮熟的目的是提供一种易于使用和理解的方式来用Java创建小型DSL。 它把自己放在一堆简单的正则表达式和一个工业强度的解析器生成器(如ANTLR)之间的空间中。 简要语法可以包括带有自定义代码的动作,这些动作可以直接包含在语法代码中,也可以通过接口包含。
煮熟的解析器示例
// example parser from the parboiled repository
// CalculatorParser4.java
package org.parboiled.examples.calculators;
[..]
@BuildParseTree
public class CalculatorParser4 extends CalculatorParser<CalcNode> {
@Override
public Rule InputLine() {
return Sequence(Expression(), EOI);
}
public Rule Expression() {
return OperatorRule(Term(), FirstOf("+ ", "- "));
}
[..]
public Rule OperatorRule(Rule subRule, Rule operatorRule) {
Var<Character> op = new Var<Character>();
return Sequence(
subRule,
ZeroOrMore(
operatorRule, op.set(matchedChar()),
subRule,
push(new CalcNode(op.get(), pop(1), pop()))
)
);
}
[..]
public Rule Number() {
return Sequence(
Sequence(
Optional(Ch('-')),
OneOrMore(Digit()),
Optional(Ch('.'), OneOrMore(Digit()))
),
// the action uses a default string in case it is run during error recovery (resynchronization)
push(new CalcNode(Double.parseDouble(matchOrDefault("0")))),
WhiteSpace()
);
}
//**************** MAIN ****************
public static void main(String[] args) {
main(CalculatorParser4.class);
}
}它不会为您构建AST,但会提供一个解析树和一些类来简化构建它。
该文档非常好,它解释了功能,显示了示例,并将精简的想法与其他选项进行了比较。 存储库中有一些示例语法,其中一个用于Java。
它被多个项目使用,包括像neo4j这样的重要项目。
PetitParser
PetitParser结合了无扫描程序解析,解析器组合器,解析表达式语法和packrat解析器的思想,将语法和解析器建模为可以动态重新配置的对象。
PetitParser是解析器组合器和传统解析器生成器之间的交叉。 所有信息都写在源代码中,但是源代码分为两个文件。 在一个文件中,您定义了语法,而在另一个文件中,您定义了与各种元素相对应的动作。 这个想法是,它应该允许您动态地重新定义语法。 虽然设计精巧,但如果设计精巧,也值得商bat。 您可以看到示例JSON语法的冗长超出了人们的预期。
JSON的示例语法文件的摘录。
示例PetitParser语法
package org.petitparser.grammar.json;
[..]
public class JsonGrammarDefinition extends GrammarDefinition {
// setup code not shown
public JsonGrammarDefinition() {
def("start", ref("value").end());
def("array", of('[').trim()
.seq(ref("elements").optional())
.seq(of(']').trim()));
def("elements", ref("value").separatedBy(of(',').trim()));
def("members", ref("pair").separatedBy(of(',').trim()));
[..]
def("trueToken", of("true").flatten().trim());
def("falseToken", of("false").flatten().trim());
def("nullToken", of("null").flatten().trim());
def("stringToken", ref("stringPrimitive").flatten().trim());
def("numberToken", ref("numberPrimitive").flatten().trim());
[..]
}
}JSON的示例解析器定义文件(定义了规则的操作)的摘录。
PetitParser的解析器定义文件
package org.petitparser.grammar.json;
import org.petitparser.utils.Functions;
public class JsonParserDefinition extends JsonGrammarDefinition {
public JsonParserDefinition() {
action("elements", Functions.withoutSeparators());
action("members", Functions.withoutSeparators());
action("array", new Function<List<List<?>>, List<?>>() {
@Override
public List<?> apply(List<List<?>> input) {
return input.get(1) != null ? input.get(1) : new ArrayList<>();
}
});
[..]
}
}有一个用Java编写的版本,但也有Smalltalk,Dart,PHP和TypeScript的版本。
缺少文档,但是有示例语法可用。
解析Java的Java库:JavaParser
有一种特殊情况需要更多注释:要在Java中解析Java代码的情况。 在这种情况下,我们必须建议使用一个名为JavaParser的库。 顺便说一下,我们为JavaParser做出了巨大贡献,但这并不是我们建议这样做的唯一原因。 事实是JavaParser是一个有数十个贡献者和数千个用户的项目,因此它非常健壮。
功能快速列表:
- 它支持1到9的所有Java版本
- 它支持词法保留和精美打印:这意味着您可以解析Java代码,对其进行修改并以原始格式或精美打印将其打印回
- 它可以与JavaSymbolSolver一起使用,从而为您提供符号解析。 即,它了解哪些方法被调用,引用引用链接到哪些声明,计算表达式的类型等。
说服了吗 您是否仍想为Java编写自己的Java解析器?
摘要
用Java进行解析是一个广泛的话题,而解析器的领域与通常的程序员领域有些不同。 您会发现直接来自学术界的最佳工具,而软件通常并非如此。 已经为论文或研究项目启动了一些工具和库。 好处是工具倾向于易于免费使用。 不利的一面是,有些作者更愿意对工具的作用原理进行很好的解释,而不是对如何使用它们有很好的文档。 而且,随着原始作者完成其硕士或博士学位,一些工具最终被放弃了。
我们倾向于大量使用解析器生成器:ANTLR是我们最喜欢的解析器生成器,并且在JavaParser的工作中我们广泛使用JavaCC。 我们不是非常使用解析器组合器。 不是因为它们不好,而是因为它们有用途,实际上我们在C#中写了一篇有关它的文章 。 但是,对于我们处理的问题,它们通常导致难以维护的代码。 但是,从一开始它们可能会更容易,因此您可能需要考虑这些。 尤其是直到现在,您已经使用正则表达式和手工编写的半解析器来破解了一些可怕的东西。
我们绝对不能真正地对您说您应该使用什么软件。 对用户来说最好的可能对其他人不是最好的。 我们都知道,技术上最正确的解决方案在所有限制条件下可能都不是现实生活中的理想选择。 但是我们在工作中搜索并尝试了许多类似的工具,因此类似本文的内容可以帮助我们节省一些时间。 因此,我们想分享我们在Java最佳解析选项方面学到的知识。
翻译自: https://www.javacodegeeks.com/2017/06/parsing-java-tools-libraries-can-use.html















 1094
1094

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









