





什么是CockroachDB?
CockroachDB是一个我一直关注很长一段时间的项目。 这是一个开放源代码的Apache 2许可数据库( Github链接 ), 极大地从Google Spanner白皮书中汲取了灵感 。 它的核心是可水平扩展的键值存储。 但是,对我们而言真正有趣的是:1)它通过使用Postgres有线协议支持SQL; 2)具有完整的ACID语义和分布式事务。 如果您对他们如何实现这一目标感兴趣,请确保阅读CockroachLabs博客上的技术文章(我承认,有时这并不适合胆小的人;-)。 请注意,它仍然是分布式系统,因此遵循CAP定理,更具体地说,它是CP系统。

正如您将在其常见问题解答中所读到的那样,这还处于初期阶段,因为许多事情尚未进行优化。 但是,既然他们最近增加了对join的基本支持 ,我想我应该使用Flowable引擎来尝试一下。 在本文中,我将展示在CockroachDB上运行Flowable v6流程引擎有多么容易。
(旁注:我喜欢这个名字!对于不了解它的人:蟑螂是地球上能够幸存于核爆炸等生物中的少数生物之一。相当有弹性的小动物……您也希望将其用于数据收集��)
设定
CockroachDb网站上的入门文档非常清楚,但为清楚起见,这是我遵循的步骤:
- 下载最新的CockroachDB tarball(或您的系统需要的任何文件)
- 解压并启动第一个节点:
- ./cockroachdb开始
- 启动第二个节点:
- ./cockroach start –store = node2 –port = 26258 –http-port = 8081 –join = localhost:26257
- 启动第三个节点:
- ./cockroach start –store = node3 –port = 26259 –http-port = 8082 –join = localhost:26257
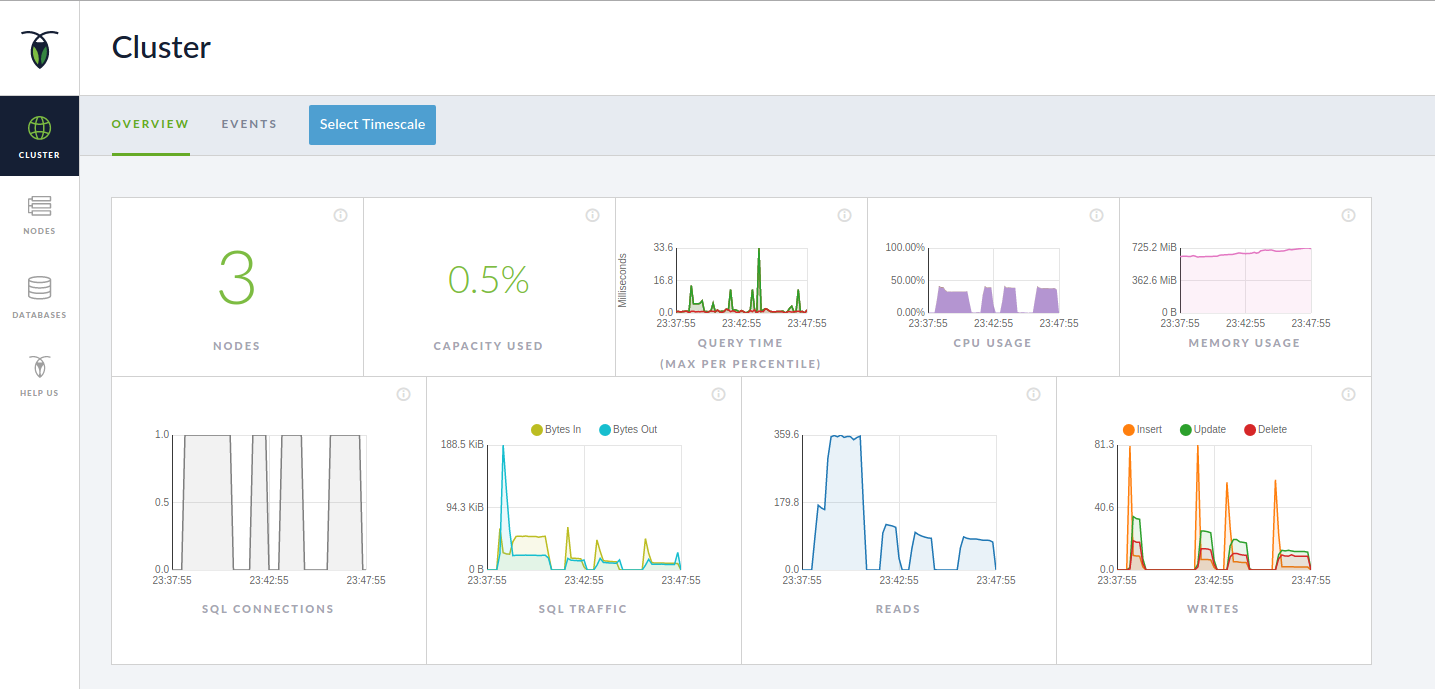
欢呼,您现在有一个运行着三个节点的集群,它们将很高兴地在彼此之间复制数据。 有一个不错的管理应用程序,可在8080上运行,并概述了群集:
下一步:我们需要Flowable引擎的数据库。 通过CockroachDB SQL shell创建数据库并向默认用户(maxroach)授予权限:
./cockroachdb sql
> CREATE DATABASE flowable;
> GRANT ALL ON DATABASE flowable TO maxroach;遗憾的是,CockroachDB尚未实现JDBC元数据功能,我们在Flowable引擎中使用了该功能来自动创建数据库模式。 另外,在某些情况下我无法完全使外键正常工作,因此我复制/粘贴了Flowable SQL脚本并删除了这些脚本。 该文件已上传到Github上 。
同样,这意味着当前您需要“手动”创建数据库模式。 如果您使用的是bash终端,则可以从github下载上面的脚本,并按如下所示将其提供给CockroachDB SQL Shell。 或者,您可以将其粘贴到SQL Shell中。
sql=$(wget https://raw.githubusercontent.com/jbarrez/flowable-cockroachdb-demo/master/engine-schema.sql -q -O -)
./cockroach sql –database=flowable –user=maxroach -e “$sql”在CockroachDB上可流动
现在数据库已准备就绪。 是时候使用此数据库作为数据存储来启动Flowable引擎。 所有源代码都可以在Github上获得: https : //github.com/jbarrez/flowable-cockroachdb-demo

由于CockroachDB使用Postgres有线协议,我们只需要将Postgres JDBC驱动程序添加到pom.xml中 :
<dependency>
<groupId>org.flowable</groupId>
<artifactId>flowable-engine</artifactId>
<version>6.0.0.RC1-SNAPSHOT</version>
</dependency>
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<version>9.4.1211.jre7</version>
</dependency>我在这里使用当前的v6 master分支,尚未发布。 通过克隆flowable-engine项目并在根目录中执行“ mvn clean install -DskipTests”,您可以轻松地自己构建它。 用于引擎的配置文件非常简单,看起来就像连接到常规Postgres关系数据库一样。 请注意,我有点“欺骗” databaseSchemaUpdate设置以避免自动模式检查。
<property name="jdbcUrl" value="jdbc:postgresql://127.0.0.1:26257/flowable?sslmode=disable" />
<property name="jdbcDriver" value="org.postgresql.Driver" />
<property name="jdbcUsername" value="maxroach" />
<property name="jdbcPassword" value="" />
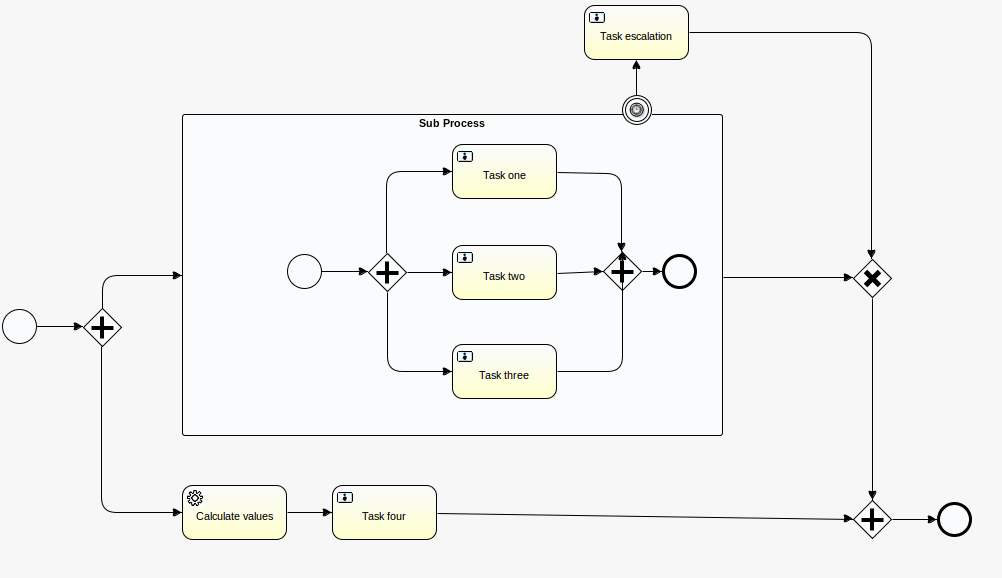
<property name="databaseSchemaUpdate" value="cockroachDb" />我们将使用的流程定义是一个简单的演示流程,它行使一些任务,例如用户任务,服务任务,子流程,计时器等:
以下代码段显示了如何以几种不同方式使用Flowable API。 如果您遵循CockroachDB管理员UI,则会看到流量增加了一段时间。 这里发生的是:
- 第3-9行:从上方使用配置文件启动Flowable流程引擎,并获取所有服务
- 第11行:部署流程定义
- 第15-19行:启动100个流程实例
- 第24-33行:完成系统中的所有任务
- 第35行:进行历史查询
因此,正如您所看到的,简单地触摸各种API并对其进行验证就可以了,这在CockroachDB上是没有用的。
public static void main(String[] args) {
ProcessEngine processEngine = ProcessEngineConfiguration
.createProcessEngineConfigurationFromResource("flowable.cfg.xml").buildProcessEngine();
RepositoryService repositoryService = processEngine.getRepositoryService();
RuntimeService runtimeService = processEngine.getRuntimeService();
TaskService taskService = processEngine.getTaskService();
HistoryService historyService = processEngine.getHistoryService();
repositoryService.createDeployment().addClasspathResource("demo-process.bpmn").deploy();
System.out.println("Process definitions deployed = " + repositoryService.createProcessDefinitionQuery().count());
Random random = new Random();
for (int i=0; i<100; i++) {
Map<String, Object> vars = new HashMap<>();
vars.put("var", random.nextInt(100));
runtimeService.startProcessInstanceByKey("myProcess", vars);
}
System.out.println("Process instances running = " + runtimeService.createProcessInstanceQuery().count());
LinkedList<Task> tasks = new LinkedList<>(taskService.createTaskQuery().list());
while (!tasks.isEmpty()) {
Task task = taskService.createTaskQuery().taskId(tasks.pop().getId()).singleResult();
if (task != null) {
taskService.complete(task.getId());
}
if (tasks.isEmpty()) {
tasks.addAll(taskService.createTaskQuery().list());
}
}
System.out.println("Finished all tasks. Finished process instances = "
+ historyService.createHistoricProcessInstanceQuery().finished().count());
processEngine.close();
}输出完全符合您的期望(并且与在关系数据库上运行的输出完全相同)。
Process definitions deployed = 1
Process instances running = 100
Completed 10 tasks
Completed 20 tasks
…
Completed 400 tasks
Finished all tasks. Finished process instances = 100结论
在CockroachDB上运行Flowable流程引擎几乎是微不足道的,特别是通过出色的SQL层和CockroachDB开发人员添加的关系支持。 还有一段路要走(正如您将在他们的博客上阅读的那样),但是现在肯定已经是一项很酷的技术了! 谁又不喜欢不牺牲ACID交易的水平可扩展性呢? 它非常适合流程引擎的用例。
我将继续密切关注CockroachDB项目,因为与Flowable的结合显示出很大的潜力。 而且,正如您所知,一旦他们开始关注性能,我也非常期待能够运行一些基准测试:-)。
翻译自: https://www.javacodegeeks.com/2016/11/running-flowable-cockroachdb.html















 185
185

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









