





本文是我们学院课程的一部分,该课程的标题为Java开发人员的Elasticsearch教程 。
在本课程中,我们提供了一系列教程,以便您可以开发自己的基于Elasticsearch的应用程序。 我们涵盖了从安装和操作到Java API集成和报告的广泛主题。 通过我们简单易懂的教程,您将能够在最短的时间内启动并运行自己的项目。 在这里查看 !
1.简介
在本教程的最后一部分中,我们将环顾四周,学习Elasticsearch如何完美地融入Java生态系统并激发许多有趣的项目。 说明这一点的最好方法之一是看一下Elasticsearch和Hibernate框架的结合,这是Java开发人员中管理持久层的一种极受欢迎的选择。
另外,在最后,我们将浏览一整套非常流行的应用程序套件,称为Elastic Stack ,以及您可以使用它做什么。 尽管它远远超出了Java应用程序的范围,但很难高估它为现代,高度分布式的软件系统提供的价值。
2. Elasticsearch for Hibernate用户
几乎不可能找到没有听说过Hibernate框架的Java开发人员。 另一方面,很少有开发人员知道在Hibernate框架下隐藏了很多项目,其中一个是名为Hibernate Search的真正瑰宝。
Hibernate Search透明地为您的对象建立索引,并提供快速的常规,全文本和地理位置搜索。 易于使用和易于集群是核心。 – http://hibernate.org/search/
Hibernate Search最初是Hibernate和Apache Lucene之间的一个简单粘合层,用于提供一组非常有限的受支持后端来管理搜索索引。 但是,随着最近发布的Hibernate Search 5.7.0最终版本以及成熟的Elasticsearch支持(尽管仍带有experimental标签),情况正在发生变化。 实际上,这意味着,如果您的持久层是由Hibernate管理的,那么通过插入Hibernate Search,您可以使用全文搜索功能来充实您的数据模型,而所有这些功能都由Elasticsearch支持。 听起来令人兴奋,对不对?
为了了解事物的工作原理,让我们看一下从Book类开始,以装饰有Hibernate Search批注的JPA实体表示的catalog数据模型。
@Entity
@Table(name = "BOOKS")
@Indexed(index = "catalog")
public class Book {
@Id
@Field(name = "isbn", analyze = Analyze.NO)
private String id;
@Field
@Column(name = "TITLE", nullable = false)
private String title;
@IndexedEmbedded(depth = 1)
@ElementCollection
private Set categories = new HashSet<>();
@Field(analyze = Analyze.NO)
@Column(name = "PUBLISHER", nullable = false)
private String publisher;
@Field
@Column(name = "DESCRIPTION", nullable = false, length = 4096)
private String description;
@Field(name = "published_date", analyze = Analyze.NO)
@Column(name = "PUBLISHED_DATE", nullable = false)
@DateBridge(resolution = Resolution.DAY)
private LocalDate publishedDate;
@NumericField @Field(name = "rating")
@Column(name = "RATING", nullable = false)
private int rating;
@IndexedEmbedded
@ManyToMany
private Set authors = new HashSet();
} 对于经验丰富的Java开发人员来说,这是描述持久实体的一段熟悉的代码,仅在顶部添加了几个Hibernate Search注释(如@Field , @DateBridge和@IndexedEmbedded )。 不幸的是,我们不会在这里讨论它们,该主题本身值得一本完整的教程,但请随时参考官方文档以获取更多详细信息。 话虽如此,我们只继续转到Category类。
@Embeddable
public class Category {
@Field(analyze = Analyze.NO)
@Column(name = "NAME", nullable = false)
private String name;
} 之后是Author类。
@Entity
@Indexed(index = "catalog")
@Table(name = "AUTHORS")
public class Author {
@Id
private String id;
@Field(name = "first_name", analyze = Analyze.NO)
@Column(name = "FIRST_NAME", nullable = false)
private String firstName;
@Field(name = "last_name", analyze = Analyze.NO)
@Column(name = "LAST_NAME", nullable = false)
private String lastName;
} 得益于Spring Framework ,尤其是Spring Boot的魔术, Hibernate和Hibernate Search的配置指向Elasticsearch作为搜索后端,就像向application.yml文件添加几行一样容易。
spring:
jpa:
properties:
hibernate:
search:
default:
indexmanager: elasticsearch
elasticsearch:
host: http://localhost:9200 坦白地说,您可能需要大量调整此配置以适合您的应用程序的需求,幸运的是, 官方文档很好地涵盖了这一部分。 每次创建,修改或删除Book或Author类的实例时, Hibernate Search都会使Elasticsearch索引保持同步,这是完全透明的。
搜索效果如何? 好吧, Hibernate Search确实基于Apache Lucene查询提供了自己的查询DSL抽象层(同时留下了使用某些本机Elasticsearch功能的途径 ),例如:
@Autowired private EntityManager entityManager;
final FullTextEntityManager fullTextEntityManager = Search
.getFullTextEntityManager(entityManager);
final QueryBuilder qb = fullTextEntityManager
.getSearchFactory()
.buildQueryBuilder()
.forEntity(Book.class)
.get();
final FullTextQuery query = fullTextEntityManager
.createFullTextQuery(
qb.bool()
.must(
qb.keyword()
.onField("categories.name")
.matching("analytics")
.createQuery()
)
.must(
qb.keyword()
.onField("authors.last_name")
.matching("Tong")
.createQuery()
).createQuery(), Book.class);
final List books = query.getResultList();
... 与Elasticsearch自己的Query DSL肯定有很多相似之处,因此您应该已经熟悉此代码段。 但是,在您太兴奋之前,与Hibernate Search和Elasticsearch集成相关的一些限制。 首先,当前Hibernate Search支持的Elasticsearch的最新版本是2.4.4 。 不错,但是与当前的5.x版本分支相去甚远,希望很快就能解决。 其次,确实,通过Hibernate Search API(尤其是Query DSL)公开的Elasticsearch功能的子集非常有限,但坦白地说,对于许多应用程序来说已经足够了。
无论如何,为什么我们要首先提到休眠搜索 ? 很简单,如果您的应用程序是基于Hibernate持久性构建的,则使用Hibernate Search可能是利用数据搜索的全文本搜索功能的最快,最便宜的方法,从而可以利用Elasticsearch的幕后知识。
3.弹性堆栈:全部使用
如果您已经遇到过神秘的ELK缩写,并且对它的含义感到好奇,那么本节将帮助您找到答案。 ELK本质上是一捆产品,由(E)lasticsearch , (L)ogstash和(K)ibana组成 ,因此简称为ELK 。 最近,随着Beats的加入, ELK成为了这个很棒的家族的新成员,现在经常被称为Elastic Stack 。
毫无疑问, Elasticsearch是ELK的心脏和灵魂,所以让我们谈谈其他产品是什么以及它们为何有用。
Kibana 允许您可视化 Elasticsearch 数据并浏览 Elastic Stack ,因此您可以执行任何操作,从了解为什么在凌晨2:00进行分页到了解降雨可能对季度数字产生的影响。 – https://www.elastic.co/products/kibana
基本上, Kibana只是一个Web应用程序,它能够根据您在Elasticsearch中建立索引的数据创建功能强大的图表和仪表板。
Logstash 是一个开放源代码的服务器端数据处理管道,可同时从多个源中提取数据,进行转换,然后将其发送到您喜欢的“存储”中,例如 Elasticsearch – https://www.elastic.co/products / logstash
因此, Logstash是一个了不起的工具,能够提取,按摩数据并将数据提供给Elasticsearch (以及众多其他来源),以后可以使用Kibana对其进行可视化。 Beats非常接近Logstash,但功能还不那么强大。

弹性堆叠图示
Elastic Stack非常有用并在竞争中处于领先地位的领域之一是收集和分析大量的应用程序日志。 听起来似乎不太令人信服,为什么您需要一个如此复杂的系统来对日志文件进行尾部/ grep处理? 但是从规模上讲,当您处理数百甚至数千个应用程序(例如微服务 )时,好处变得非常明显:您突然有了一个集中的位置,所有应用程序的日志都将被流式传输到该位置,并可以进行搜索,分析,相关和可视化。
在不进行进一步讨论的情况下,让我们演示如何配置典型的Spring Boot应用程序以将其日志发送到Logstash , Logstash将按原样将其转发到Elasticsearch ,而无需应用转换。 首先,我们需要将Logstash安装为Docker容器或仅在本地计算机上运行 , 官方文档非常好地介绍了安装步骤。
我们唯一需要告诉Logstash的地方是通过logstash.conf配置文件从何处获取日志(使用input plugins )以及将经过logstash.conf日志发送至何处(使用output plugins )。
input {
tcp {
port => 7760
}
}
output {
elasticsearch {
hosts => [ "localhost:9200" ]
}
}Logstash支持的输入和输出插件的数量惊人。 为了使示例非常简单,我们将通过TCP套接字输入插件传递日志,并使用Elasticsearch输出插件直接转发给Elasticsearch 。
看起来不错,但是如何将日志从Java应用程序发送到Logstash ? 有很多方法可以做到这一点,最简单的方法可能就是利用日志记录框架的功能。 如今,大多数Java应用程序都依赖于出色的Logback框架,并且社区已经实现了专用的Logback编码器 ,可与Logstash一起使用。
您只需要在您的项目中包括一个额外的依赖项,就像我们在这里所做的那样,例如使用Apache Maven :
<dependency>
<groupId>net.logstash.logback</groupId>
<artifactId>logstash-logback-encoder</artifactId>
<version>4.9</version>
</dependency> 然后将Logstash附加程序添加到您的logback.xml配置文件中。 需要注意的是,有几个可用的附加程序,我们感兴趣的是LogstashTcpSocketAppender ,它通过TCP套接字与Logstash对话。 请注意, destination标记下的端口应与您的Logstash输入插件配置匹配,在本例中为7760 。
<appender name="logstash" class="net.logstash.logback.appender.LogstashTcpSocketAppender">
<destination>localhost:7760</destination>
<encoder class="net.logstash.logback.encoder.LogstashEncoder" />
</appender>总的来说,这就是我们要做的! 日志将从我们的应用程序传送到Elasticsearch ,我们可以使用Kibana仪表板对其进行浏览 。 在本地计算机上下载并运行Kibana时,默认情况下,Web UI可从http:// localhost:5601获得 :

快速Kibana仪表板
简单,简单,强大… Elasticsearch方式。 唯一要记住的是,您最好使用相同版本的Elasticsearch , Logstash和Kibana 。 正如我们在本教程中一直使用Elasticsearch 5.2.0一样, Logstash和Kibana也应该是5.2.0版本。
如果您已经使用或打算使用Elasticsearch , Elastic Stack只会为您提供发现和受益的有趣机会的整个领域。 而且,它会随着每个发行版中添加的新功能而不断得到改进和增强。
4.使用插件增强Elasticsearch
Elasticsearch很棒,但是通常命令行工具甚至Java API都不是与集群通信的最佳方法。 幸运的是, Elasticsearch从早期就以插件的形式内置了可扩展性。
- elasticsearch-head : Elasticsearch集群的Web前端
- elasticsearch-HQ :监视,管理和查询Elasticsearch的 Web界面
- search-guard : Elasticsearch的安全性
elasticsearch-head本质上是Elasticsearch的完整Web界面。 您不仅可以很好地直观地显示索引和分片,还可以浏览文档,使用搜索查询并轻松浏览结果。
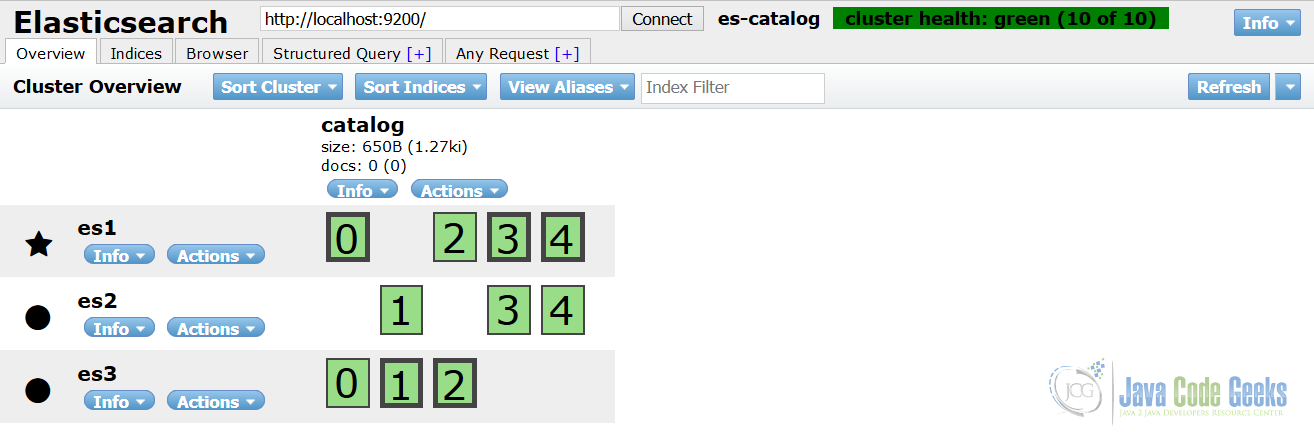
显示目录索引和集群状态的elasticsearch-head示例
运行结构化查询或任意查询的功能非常有帮助,特别是如果查询返回很多结果并且您需要一种便捷的方式来浏览所有结果的能力。
另一个非常有趣的是elasticsearch-HQ ,它基本上将重点放在公开有关Elasticsearch集群和节点的操作信息上。 不幸的是,在撰写本文时, elasticsearch-HQ不支持Elasticsearch的 5.x版本分支,但是实现它的工作已经开始。
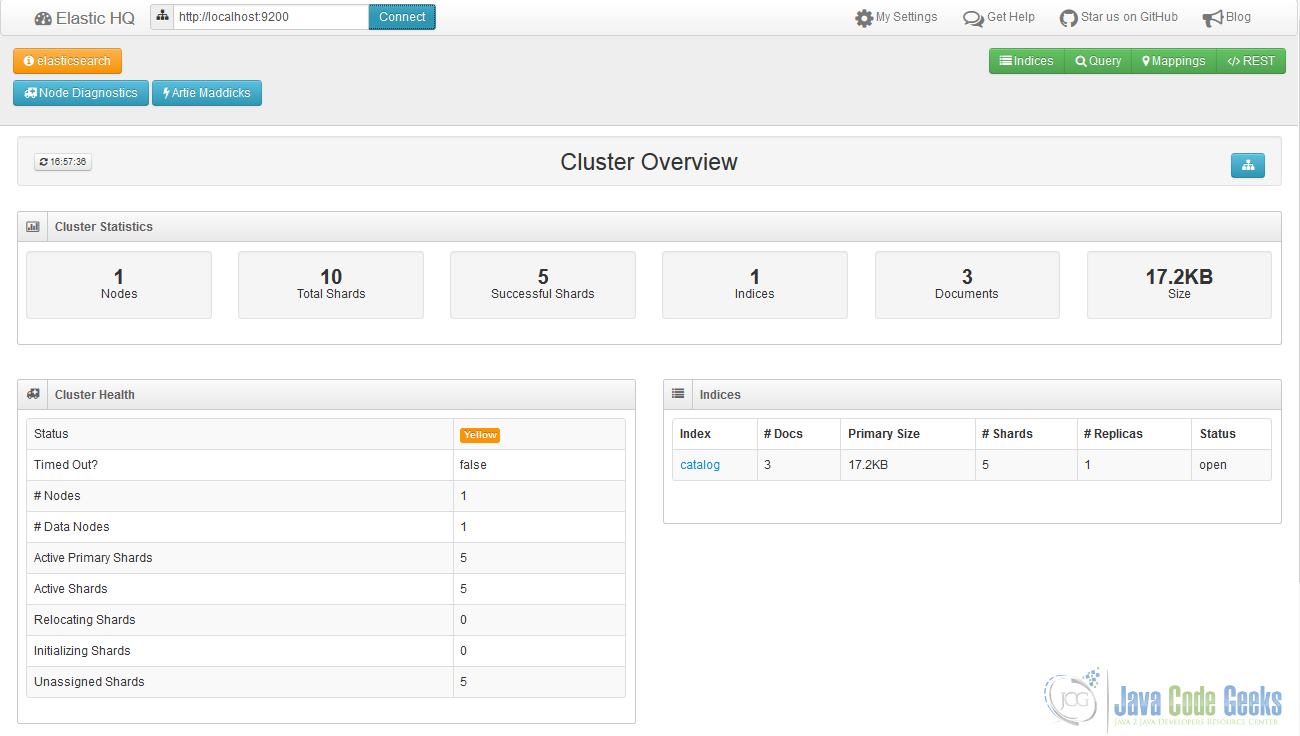
显示目录索引和集群状态的Elasticsearch-HQ示例
在我们讨论最后一个插件Search-guard之前 ,最好先讨论一下Elasticsearch中的安全状态。 实际上,我们最好说一下, Elasticsearch在安全性或类似方面没有任何提供(尽管该功能以及许多其他功能可以作为Elasticsearch的商业发行使用)。 搜索卫士是社区支持的最古老的插件,它为Elasticsearch增加了很多安全功能。 如果您真的想在生产环境中运行Elasticsearch ,请务必看一看。幸运的是,它支持所有最新的Elasticsearch版本。
5。结论
在这一部分中,“面向Java开发人员的Elasticsearch”系列已接近逻辑尾声。 在本教程中,我们了解了Elasticsearch ,其功能以及如何使用命令行工具及其丰富的RESTful API进行通信 。 我们还讨论了目前可用的各种Java API,并简要讨论了何时使用一种或另一种。 最后,我们涵盖了一个蓬勃发展的项目(和产品)生态系统,它围绕着Elasticsearch出现并在很大程度上依赖于它的功能。
希望您在此过程中学到了一些东西,如果您在尝试或不尝试Elasticsearch之前犹豫不决,则现在应该清除所有疑问。 这是一个伟大的产品,具有巨大的潜力,可以解决各种难题,并为您的想法带来成功。
有了这个,祝您旅途顺利! 此处提供了本文的完整源代码。
翻译自: https://www.javacodegeeks.com/2017/04/elasticsearch-java-developers-elasticsearch-ecosystem.html















 404
404

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









