





Java监视的当前状态最大的问题是什么?
生产中的错误很像喝醉的短信。 您只有在事情已经发生之后才意识到出了点问题。 发短信日志通常比应用程序错误日志更有趣,但是……两者都同样难以修复。
在本文中,我们将执行一个12步的监视漏洞修复程序。 由Takipi用户的经验支持的思想实验,解决了您可能会遇到的一些最常见问题–以及您可以如何处理。
来吧。
步骤#1:承认我们有问题
实际上,这只是更高级别的应用程序可靠性问题。 为了能够快速了解应用程序何时出现问题,并能够快速访问所需的所有信息以进行修复。
当我们更进一步时,可靠性问题由监视和日志记录的当前状态下的许多其他症状组成。 这些是大多数人试图掩埋或完全避免的棘手问题。 但是在这篇文章中,我们将它们放在了焦点。
底线:不可避免地要对生产中出现的新错误进行故障排除和处理。
步骤2:关闭监控信息过载
一个好的做法是收集有关应用程序的所有信息,但这仅在度量标准有意义时才有用。 如果日志记录和度量标准遥测的可操作性只是事后的想法,则会产生更多的噪声。 即使它们产生漂亮的仪表板。
其中很大一部分是将异常和记录的错误滥用为应用程序控制流的一部分,从而以“正常”异常的悖论堵塞了日志。 您可以在我们这里发布的最新电子书中了解有关此内容的更多信息。
随着监视和数据保留成本的降低,问题开始转移到收集可行的数据并使之有意义。
底线:尽管逐渐变得更容易记录和报告所有内容,但错误根源发现仍然大部分是手动的,大海捞针越来越大,很难找到针头。
步骤#3:避免繁琐的日志分析
假设我们有一些错误,一个特定的事务有时会失败。 现在,我们必须在日志文件中找到有关它的所有相关信息。 是时候翻阅日志的方式了,或者使用诸如Splunk,ELK或其他日志 管理工具之类的可以使搜索更快的工具来处理不同的查询。
为了使此过程更容易,使用Takipi的开发人员可以将每个记录的错误,警告和异常的上下文扩展到导致它的源,状态和变量状态。 每条日志行都有一个链接附加到该链接,从而可以在Takipi中进行事件分析:
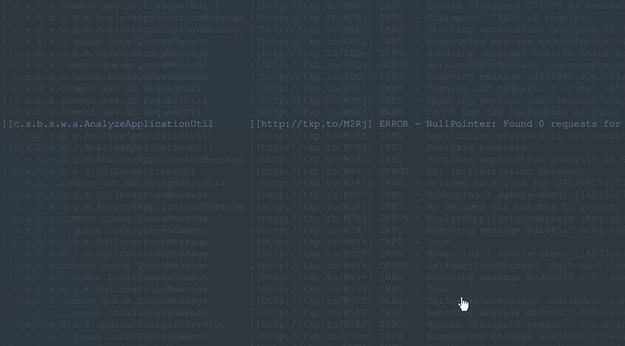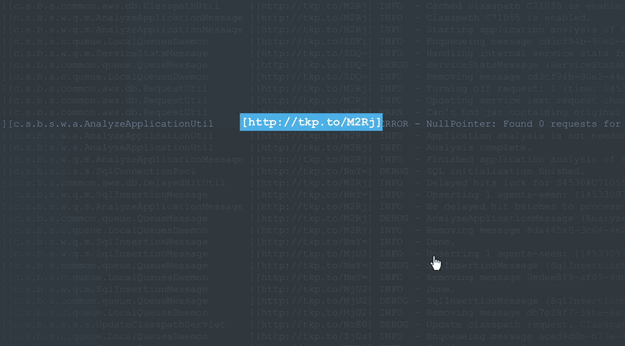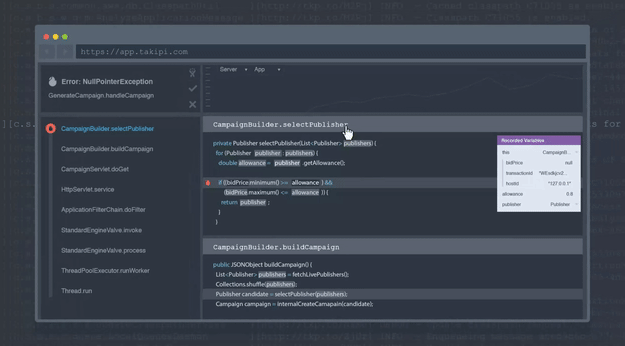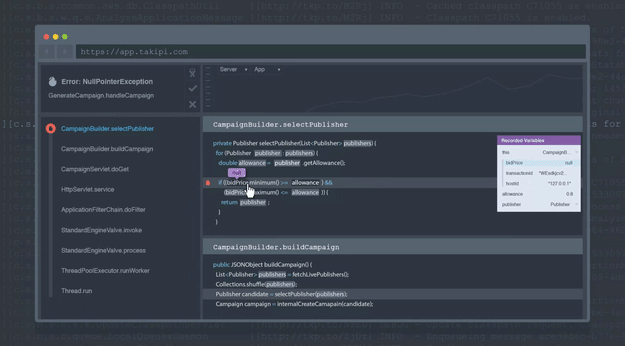
底线:手动筛选日志是一个繁琐的过程,可以避免。
步骤4:认识到生产日志级别不够详细
原木水平是一把双刃剑。 您登录生产的级别越多,您拥有的上下文就越多。 但是,额外的日志记录会产生开销,最好在生产中避免。 有时,您需要的其他数据将出现在“ DEBUG”或“ INFO”消息中,但是生产应用程序通常仅写入“ WARN”级消息或更高级别。
我们在Takipi中解决此问题的方法是使用最近发布的新功能,该功能使您能够查看线程中导致错误的最后250条日志语句。 即使它们没有在生产中写入日志文件。
等一下 无日志记录,无额外开销。 由于日志语句是直接在内存中捕获的,而不依赖于日志文件,因此我们能够在生产中进行详尽的描述,而不会影响日志大小或增加开销。 您可以在这里阅读有关它的更多信息,或者自己尝试 。
底线:从今天开始,您不仅限于WARN或更高级别的生产日志记录。
步骤#5:下一个说“无法复制”的人买了一轮饮料
推迟错误修复的最常见借口是“无法复制”。 缺少导致它的状态的错误。 不好的事情发生了,通常您首先会从实际用户那里听到它,并且无法重新创建它或在日志/收集的指标中找到证据。
从根本上讲,“无法复制”的隐藏含义是正确的。 如果您习惯于第一次听到用户的错误消息,则内部跟踪错误的方式可能有问题。 通过适当的监视,可以在实际用户报告错误之前识别并解决错误。
底线:停止复制“无法复制”。

步骤#6:打破日志语句重新部署周期
一种常见的臭名昭著且不幸的“无法复制”的解决方法是在生产中添加其他日志记录语句,并希望该错误再次发生。
在生产中。
搞乱真实用户。
那就是生产调试悖论。 发生错误时,您没有足够的数据来解决它(但您确实有很多杂音),添加了日志记录语句,进行了构建,测试(首先错过了该错误的同一测试),部署到生产环境,希望为使它再次发生,希望新数据足够或…重复。
底线:成功的监视策略的最终目标是防止此周期的发生。
步骤#7:APM +跟踪器+指标+日志=可见性受限
让我们提高一个等级。 我们已经介绍了日志和仪表板报告指标,现在是时候添加错误跟踪工具 和 APM了。
事实是,即使监视堆栈包括所有4类的解决方案,您进入应用程序错误的可见性也受到限制。 您将看到事务的堆栈跟踪,或者最多看到特定的预定义硬编码变量。 传统的监视堆栈在出现错误时无法查看应用程序的完整状态。
底线:在当今的通用监视堆栈中,有一个关键的缺失组件。 生产调试具有可变级别的可见性。
步骤#8:为分布式错误监控做准备
监视不会在单个服务器级别上停止,尤其是在微服务体系结构中,在一台服务器上形成的错误可能在其他地方引起麻烦。
尽管微服务提倡“关注点分离”原则,但它们还在服务器级别上引入了许多新问题。 在上一篇文章中,我们讨论了这些问题,并提供了可能的解决方案策略。
底线:任何监视解决方案都应考虑分布式错误,并能够对来自多个源的数据进行故障排除。
步骤#9:找到解决方法,以解决较长的故障排除周期
无论是警告问题还是仅是优先事项,对于大多数应用程序,在引入第一个错误之后,故障排除周期都需要数天,数周甚至数月的时间。 报告该错误的人可能无法访问或更糟,由于数据保留策略,相关数据可能长期未保存/滚动。
在这种情况下,即使在错误时刻冻结应用程序状态快照的能力(即使它来自多个服务/源)也至关重要,否则,重要数据可能会丢失。
底线:应避免较长的故障排除周期。
步骤#10:确认开发人员与运营者的困境
跟上发布周期的问题,我们所有人都在同一条船上,但是,开发人员希望更快地发布功能,而运营则希望保持生产环境的稳定。
短的功能周期和长的故障排除周期根本不会在一起。 两者之间应该保持平衡。 监视是一项团队运动,并且工具必须知道如何相互交谈。 例如,在Takipi,您可以获得有关Slack,Pagerduty或Hipchat的警报,并直接打开JIRA凭单,其中包含所有可用的错误分析数据。
底线:协作工作流加快了问题解决的速度。
步骤#11:有希望
现代开发人员工具正在采取重大措施来改善当前的监视状态。 无论是在日志,应用程序性能管理领域还是在进行中的新类别。
底线:密切注意工具生态系统的发展以及其他公司的最佳实践。
步骤#12:宣传
监视是软件开发不可分割的一部分,让我们继续进行讨论吧!
我们希望您对当前监视状态的一些主要问题感到满意/概述。 监控还有其他问题让您彻夜难眠吗?
请随时在下面的评论部分中分享它们。
翻译自: https://www.javacodegeeks.com/2016/08/12-step-program-realizing-java-monitoring-flawed.html















 7558
7558

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









