





 本文介绍了如何使用Spring Boot和Spring Data MongoDB进行数据聚合操作,重点是构建聚合查询以从MongoDB中获取汇总结果。通过设置Maven依赖、应用程序配置和自定义存储库,展示了如何实现价格范围过滤、按仓库分组、计算平均价格和总收入的聚合查询。
本文介绍了如何使用Spring Boot和Spring Data MongoDB进行数据聚合操作,重点是构建聚合查询以从MongoDB中获取汇总结果。通过设置Maven依赖、应用程序配置和自定义存储库,展示了如何实现价格范围过滤、按仓库分组、计算平均价格和总收入的聚合查询。
MongoDB聚合框架旨在对文档进行分组并将其转换为聚合结果。 聚合查询包括定义将在管道中执行的几个阶段。 如果您对有关该框架的更深入的细节感兴趣,那么
mongodb docs是一个很好的起点。
这篇文章的重点是编写一个用于查询mongodb的Web应用程序,以便从数据库中获取汇总结果。 借助Spring Boot和Spring Data,我们将以非常简单的方式进行操作。 实际上,实现该应用程序确实非常快,因为Spring Boot会处理所有必要的设置,而Spring Data将帮助我们配置存储库。
可以在我的Github存储库中找到源代码。
1申请
在遍历代码之前,让我们看一下我们要对应用程序执行的操作。
我们的领域是我们分布在多个仓库中的产品的集合:
@Document
public class Product {
@Id
private final String id;
private final String warehouse;
private final float price;
public Product(String id, String warehouse, float price) {
this.id = id;
this.warehouse = warehouse;
this.price = price;
}
public String getId() {
return id;
}
public String getWarehouse() {
return warehouse;
}
public float getPrice() {
return price;
}
}我们的目标是收集价格范围内的所有产品,并按仓库分组,并收集总收入和每个分组的平均价格。
在此示例中,我们的仓库存储以下产品:
new Product("NW1", "Norwich", 3.0f);
new Product("LN1", "London", 25.0f);
new Product("LN2", "London", 35.0f);
new Product("LV1", "Liverpool", 15.2f);
new Product("MN1", "Manchester", 45.5f);
new Product("LV2", "Liverpool", 23.9f);
new Product("LN3", "London", 55.5f);
new Product("LD1", "Leeds", 87.0f);该应用程序将查询价格在5.0到70.0之间的产品。 所需的聚合管道步骤如下:
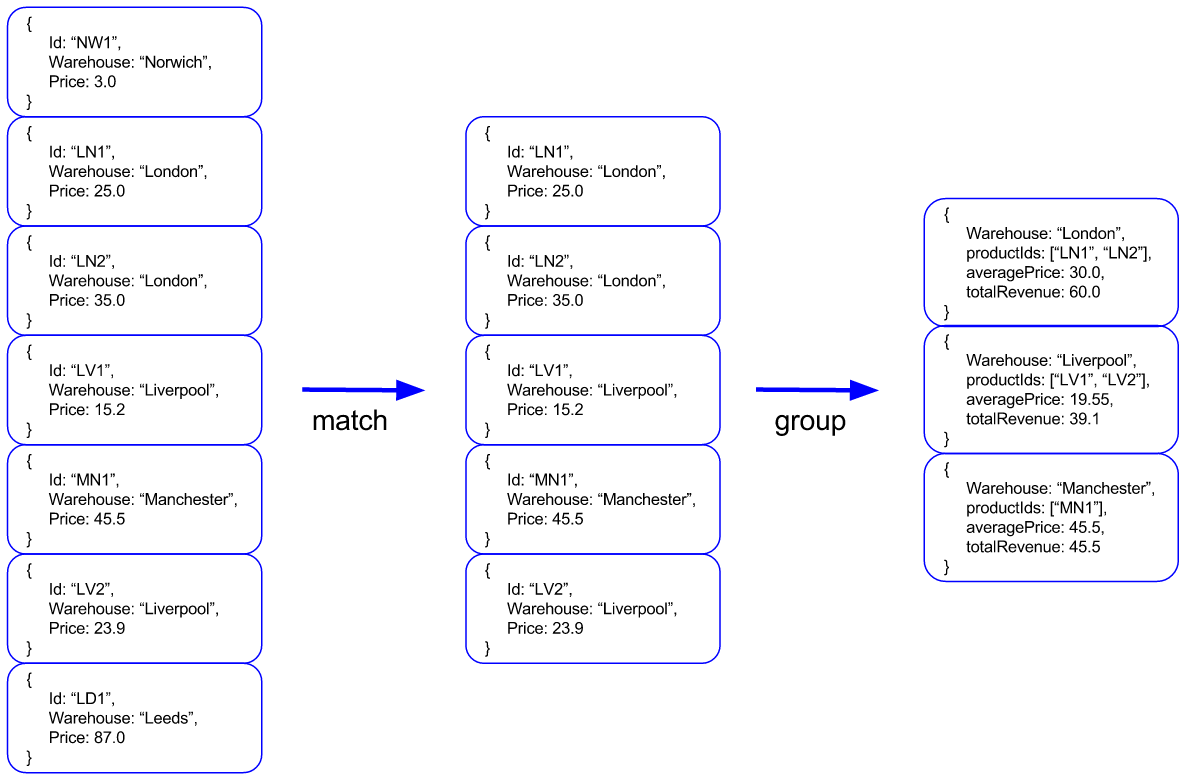
我们将最终得到按仓库分组的汇总结果。 每个组将包含每个仓库的产品清单,平均产品价格和总收入,这实际上是价格的总和。
2 Maven依赖
如您所见,我们有一个简短的pom.xml,其中包含Spring Boot依赖项:
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>1.3.3.RELEASE</version>
<relativePath/>
</parent>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-mongodb</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>通过将spring-boot-starter-parent定义为父pom,我们设置了Spring Boot的默认设置。 主要是它设置了可能使用的一堆库的版本,例如Spring或Apache Commons。 例如,我们正在使用的Spring Boot 1.3.3将4.2.5.RELEASE设置为Spring框架版本。 如前几篇文章所述,它没有将库添加到我们的应用程序中,而只是设置版本。
定义父项后,我们只需添加三个依赖项:
- spring-boot-starter-web:主要包括Spring MVC库和嵌入式Tomcat服务器。
- spring-boot-starter-test:包括JUnit,Mockito,Hamcrest和Spring Test等测试库。
- spring-boot-starter-data-mongodb:此依赖项包括MongoDB Java驱动程序和Spring Data Mongo库。
3应用程序设置
多亏了Spring Boot,应用程序设置与依赖项设置一样简单:
@SpringBootApplication
public class AggregationApplication {
public static void main(String[] args) {
SpringApplication.run(AggregationApplication.class, args);
}
}运行main方法时,我们将启动侦听8080端口的Web应用程序。
4资料库
既然我们已经正确配置了应用程序,我们就可以实现存储库。 这也不难,因为Spring Data负责所有布线。
@Repository
public interface ProductRepository extends MongoRepository<Product, String> {
}以下测试证明我们的应用程序已正确设置。
@RunWith(SpringJUnit4ClassRunner.class)
@SpringApplicationConfiguration(classes = AggregationApplication.class)
@WebAppConfiguration
public class AggregationApplicationTests {
@Autowired
private ProductRepository productRepository;
@Before
public void setUp() {
productRepository.deleteAll();
}
@Test
public void contextLoads() {
}
@Test
public void findById() {
Product product = new Product("LN1", "London", 5.0f);
productRepository.save(product);
Product foundProduct = productRepository.findOne("LN1");
assertNotNull(foundProduct);
}
}我们没有实现save和findOne方法。 由于我们的存储库正在扩展MongoRepository,因此已经定义了它们。
5聚合查询
最后,我们设置了应用程序并解释了所有步骤。 现在我们可以专注于聚合查询。
由于我们的聚合查询不是基本查询,因此我们需要实现一个自定义存储库。 这些步骤是:
使用我们需要的方法创建自定义存储库:
public interface ProductRepositoryCustom {
List<WarehouseSummary> aggregate(float minPrice, float maxPrice);
}修改第一个存储库以扩展我们的自定义存储库:
@Repository
public interface ProductRepository extends MongoRepository<Product, String>, ProductRepositoryCustom {
}创建一个实现来编写聚合查询:
public class ProductRepositoryImpl implements ProductRepositoryCustom {
private final MongoTemplate mongoTemplate;
@Autowired
public ProductRepositoryImpl(MongoTemplate mongoTemplate) {
this.mongoTemplate = mongoTemplate;
}
@Override
public List<WarehouseSummary> aggregate(float minPrice, float maxPrice) {
...
}
}现在,我们将实现postgo开头所述的mongodb管道阶段。
我们的第一个操作是match操作。 我们将过滤掉超出我们价格范围的所有产品文档:
private MatchOperation getMatchOperation(float minPrice, float maxPrice) {
Criteria priceCriteria = where("price").gt(minPrice).andOperator(where("price").lt(maxPrice));
return match(priceCriteria);
}流水线的下一个阶段是组操作。 除了按仓库对文档进行分组之外,在此阶段,我们还进行以下计算:
- last:返回组中最后一个文档的仓库。
- addToSet:收集所有分组文档的所有唯一产品ID,从而形成一个数组。
- 平均:计算组中所有价格的平均值。
- sum:汇总组中的所有价格。
private GroupOperation getGroupOperation() {
return group("warehouse")
.last("warehouse").as("warehouse")
.addToSet("id").as("productIds")
.avg("price").as("averagePrice")
.sum("price").as("totalRevenue");
}管道的最后阶段是项目运营。 在这里,我们指定聚合的结果字段:
private ProjectionOperation getProjectOperation() {
return project("productIds", "averagePrice", "totalRevenue")
.and("warehouse").previousOperation();
}查询的构建如下:
public List<WarehouseSummary> aggregate(float minPrice, float maxPrice) {
MatchOperation matchOperation = getMatchOperation(minPrice, maxPrice);
GroupOperation groupOperation = getGroupOperation();
ProjectionOperation projectionOperation = getProjectOperation();
return mongoTemplate.aggregate(Aggregation.newAggregation(
matchOperation,
groupOperation,
projectionOperation
), Product.class, WarehouseSummary.class).getMappedResults();
}在聚合方法中,我们指示输入类,这是我们的产品文档。 下一个参数是输出类,它是一个DTO,用于存储结果聚合:
public class WarehouseSummary {
private String warehouse;
private List<String> productIds;
private float averagePrice;
private float totalRevenue;我们应该通过测试来证明该结果符合我们的预期:
@Test
public void aggregateProducts() {
saveProducts();
List<WarehouseSummary> warehouseSummaries = productRepository.aggregate(5.0f, 70.0f);
assertEquals(3, warehouseSummaries.size());
WarehouseSummary liverpoolProducts = getLiverpoolProducts(warehouseSummaries);
assertEquals(39.1, liverpoolProducts.getTotalRevenue(), 0.01);
assertEquals(19.55, liverpoolProducts.getAveragePrice(), 0.01);
}
private void saveProducts() {
productRepository.save(new Product("NW1", "Norwich", 3.0f));
productRepository.save(new Product("LN1", "London", 25.0f));
productRepository.save(new Product("LN2", "London", 35.0f));
productRepository.save(new Product("LV1", "Liverpool", 15.2f));
productRepository.save(new Product("MN1", "Manchester", 45.5f));
productRepository.save(new Product("LV2", "Liverpool", 23.9f));
productRepository.save(new Product("LN3", "London", 55.5f));
productRepository.save(new Product("LD1", "Leeds", 87.0f));
}
private WarehouseSummary getLiverpoolProducts(List<WarehouseSummary> warehouseSummaries) {
return warehouseSummaries.stream().filter(product -> "Liverpool".equals(product.getWarehouse())).findAny().get();
}六,结论
Spring Data与MongoDB聚合框架具有良好的集成。 添加Spring Boot来配置应用程序,让我们集中精力构建查询。 对于构建过程,Aggregation类具有几种静态方法,可帮助我们实现不同的管道阶段。
我正在Google Plus和Twitter上发布我的新帖子。 如果您要更新新内容,请关注我。
翻译自: https://www.javacodegeeks.com/2016/04/data-aggregation-spring-data-mongodb-spring-boot.html















 5319
5319

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









