





在这篇文章中:
- 什么是JLBH
- 我们为什么写JLBH
- JMH和JLBH之间的区别
- 快速入门指南
什么是JLBH?
JLBH是可用于测量Java程序中的延迟的工具。 它具有以下功能:
- 旨在运行比微型基准测试更大的代码。
- 适用于使用异步活动(如生产者使用者模式)的程序。
- 能够对计划中的各个点进行基准测试
- 能够将吞吐量调整为基准
- 调整协调遗漏,即,如果迭代的端到端延迟相互影响,则会相互影响
- 报告并运行自己的抖动线程
为什么我们写JLBH?
之所以写JLBH是因为我们需要一种基准测试Chronicle-FIX的方法。 我们创建它是为了对软件中的问题进行基准测试和诊断。 事实证明,它非常有用,现在可以在Chronicle开源库中使用。
Chronicle-FIX是一种超低延迟Java修复引擎。 例如,它保证了延迟,即将NewOrderSingle消息解析到对象模型中的过程不会超过6us,直到第99.9个百分点。 实际上,我们需要一直沿百分位数范围进行测量。
这是延迟/百分位数典型配置文件。
50 -> 1.5us
90 -> 2us
99 -> 2us
99.9 -> 6us
99.99 -> 12us
99.999 -> 35us
Worst -> 500usChronicle Fix通过各种吞吐量(从10k消息/秒到100k消息/秒)保证了这些延迟。 因此,我们需要一个测试工具,可以轻松地改变吞吐量。
我们还需要考虑协调遗漏。 换句话说,我们不能仅仅忽略慢速运行对后续运行的影响。 如果运行A慢且导致运行B延迟,即使运行B在自己的运行中没有任何延迟,则仍必须记录该延迟的事实。
我们需要尝试区分OS抖动,JVM抖动和由我们自己的代码引起的抖动。 因此,我们添加了一个具有抖动线程的选项,该线程除了在JVM中采样抖动外什么也不做。 这将显示OS抖动的组合,例如线程调度和常规OS中断以及全局JVM事件(例如GC暂停)。
我们需要将延迟最好地分配给单个例程甚至代码行,因此我们还创造了将自定义采样添加到程序中的可能性。 NanoSamplers的添加几乎没有增加基准测试的开销,并且使您可以观察程序在哪里引入延迟。
这是我们用来测量Chronicle-FIX的基准的示意图。
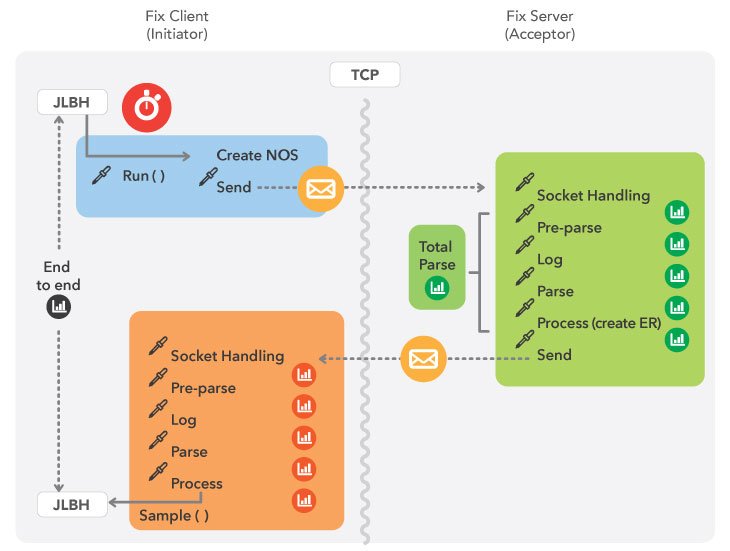
我们最终得到如下结果:
这是典型的运行:
Run time: 100.001s
Correcting for co-ordinated:true
Target throughput:50000/s = 1 message every 20us
End to End: (5,000,000) 50/90 99/99.9 99.99/99.999 - worst was 11 / 15 17 / 20 121 / 385 - 541
Acceptor:1 init2AcceptNetwork (4,998,804) 50/90 99/99.9 99.99/99.999 - worst was 9.0 / 13 15 / 17 21 / 96 - 541
Acceptor:1.1 init2AcceptorNetwork(M) (1,196) 50/90 99/99.9 99.99 - worst was 22 / 113 385 / 401 401 - 401
Acceptor:2 socket->parse (4,998,875) 50/90 99/99.9 99.99/99.999 - worst was 0.078 / 0.090 0.11 / 0.17 1.8 / 2.1 - 13
Acceptor:2.0 remaining after read (20,649,126) 50/90 99/99.9 99.99/99.999 99.9999/worst was 0.001 / 0.001 0.001 / 0.001 0.001 / 1,800 3,600 / 4,590
Acceptor:2.1 parse initial (5,000,100) 50/90 99/99.9 99.99/99.999 - worst was 0.057 / 0.061 0.074 / 0.094 1.0 / 1.9 - 4.7
Acceptor:2.5 write To Queue (5,000,100) 50/90 99/99.9 99.99/99.999 - worst was 0.39 / 0.49 0.69 / 2.1 2.5 / 3.4 - 418
Acceptor:2.9 end of inital parse (5,000,000) 50/90 99/99.9 99.99/99.999 - worst was 0.17 / 0.20 0.22 / 0.91 2.0 / 2.2 - 7.6
Acceptor:2.95 on mid (5,000,000) 50/90 99/99.9 99.99/99.999 - worst was 0.086 / 0.10 0.11 / 0.13 1.4 / 2.0 - 84
Acceptor:3 parse NOS (5,000,000) 50/90 99/99.9 99.99/99.999 - worst was 0.33 / 0.38 0.41 / 2.0 2.2 / 2.6 - 5.5
Acceptor:3.5 total parse (5,000,000) 50/90 99/99.9 99.99/99.999 - worst was 1.1 / 1.2 1.8 / 3.0 3.5 / 5.8 - 418
Acceptor:3.6 time on server (4,998,804) 50/90 99/99.9 99.99/99.999 - worst was 1.1 / 1.2 1.8 / 3.1 3.8 / 6.0 - 418
Acceptor:4 NOS processed (5,000,000) 50/90 99/99.9 99.99/99.999 - worst was 0.21 / 0.23 0.34 / 1.9 2.1 / 2.8 - 121
Jitter (5,000,000) 50/90 99/99.9 99.99/99.999 - worst was 0.035 / 0.035 0.035 / 0.037 0.75 / 1.1 - 3.3
OS Jitter (108,141) 50/90 99/99.9 99.99 - worst was 1.2 / 1.4 2.5 / 4.5 209 - 217在基准测试结束时汇总了所有样本的所有样本,这里有几个:
-------------------------------- SUMMARY (Acceptor:2.95 on mid)----------------------
Percentile run1 run2 run3 run4 run5 % Variation var(log)
50: 0.09 0.09 0.09 0.09 0.09 0.00 3.32
90: 0.10 0.10 0.10 0.10 0.10 0.00 3.58
99: 0.11 0.11 0.11 0.11 0.11 2.45 3.69
99.9: 0.13 0.13 0.62 0.78 0.13 76.71 6.01
99.99: 1.50 1.38 1.82 1.89 1.70 19.88 9.30
worst: 1.95 2.02 2.11 2.24 2.24 6.90 9.90
-------------------------------------------------------------------------------------
-------------------------------- SUMMARY (Acceptor:3 parse NOS)----------------------
Percentile run1 run2 run3 run4 run5 % Variation var(log)
50: 0.33 0.33 0.34 0.36 0.36 6.11 5.75
90: 0.38 0.38 0.46 0.46 0.46 12.42 6.24
99: 0.41 0.41 0.50 0.53 0.50 16.39 6.47
99.9: 2.11 2.02 2.11 2.11 2.11 3.08 9.76
99.99: 2.37 2.24 2.37 2.37 2.37 3.67 10.05
worst: 2.88 2.62 3.14 3.14 2.88 11.51 10.67
-------------------------------------------------------------------------------------使用JLBH,我们既可以根据规范中的标准对我们的应用程序进行基准测试,也可以诊断一些延迟峰值。
通过改变基准测试的吞吐量和运行时间,尤其是通过向代码模式中的各个点添加采样开始出现,这导致了延迟源。 一个特殊的例子是DateTimeFormatter出现了一个TLB缓存未命中的问题,但这将是另一篇文章的主题。
JMH和JLBH之间的区别
我希望阅读本文的大多数人都熟悉JMH (Java MicroBenchmarking Harness),这是用于微基准测试的出色工具,如果您还没有使用过它,那么它是每个Java开发人员都应该在自己的储物柜中拥有的有价值的工具。 特别是那些与测量延迟有关的人。
正如您将从JLBH设计中看到的那样,其中许多设计都是受JMH启发的。
因此,如果JMH如此出色,为什么我们必须创建另一个基准测试工具?
我想从高层次上来说答案就是名字。 J M H直接针对微型基准测试,而JLBH则在大型程序中寻找延迟。
不仅如此。 在阅读了最后一节之后,您会发现出于某些问题,您可能出于多种原因而选择JLBH而不是JMH。
顺便说一句,尽管您始终可以使用JLBH而不是JMH,但是如果您有一个真正的微型基准,并且希望尽可能干净地,准确地进行测量,我总是建议您使用JMH而不是JLBH。 JMH是一个非常复杂的工具,它确实做得很好,例如,JMH每次运行都会派生JVM,而JLBH目前还不支持。
在JMH上使用JLBH时:
- 如果要查看您的代码在上下文中运行。 JMH的本质是对代码进行非常小的采样,例如,在FIX引擎的情况下,仅进行解析,然后将其隔离计时。 在我们的测试中,在上下文环境中(即作为修复引擎的一部分)进行完全相同的修复解析所花费的时间是在上下文环境中(即在微基准测试中)进行时所花费的时间的两倍。 在我的“延迟”示例项目DateSerialise中,我有一个很好的例子,其中演示了序列化Date对象在TCP调用中运行时所花费的时间可能是原来的两倍。 其原因全与CPU缓存有关,我们将在以后的博客中再次讨论。
- 如果要考虑协调遗漏。 在JMH中,根据设计,所有迭代都是相互独立的,因此,如果代码的一个迭代缓慢,则不会对下一个迭代产生影响。 在我的Latency示例SimpleSpike中,我们可以看到一个很好的例子,在该例子中,我们看到了协调遗漏的巨大影响。 考虑到协调的遗漏时,几乎总是应该对现实世界中的示例进行衡量。
例如,假设您正在等待火车,但由于前面的火车晚了,因此在车站延迟了一个小时。 让我们想象一下,您晚点一个小时上火车,而火车通常需要半个小时才能到达目的地。 如果您没有考虑到协调遗漏,即使您在出发前在车站等了一个小时,您的旅程也花费了正确的时间,因此您不会认为自己遭受了任何延误! - 如果要在测试中改变吞吐量 。 JLBH允许您将吞吐量设置为基准测试的参数。 事实是,没有定义的吞吐量,延迟几乎没有意义,因此,能够在延迟配置文件上查看更改吞吐量的结果非常重要。 JMH不允许您设置吞吐量。 (实际上,这与JMH没有考虑到协调的遗漏是相辅相成的。)
- 您希望能够对代码中的各个点进行采样。 端到端延迟是一个很好的起点,但那又如何呢? 您需要能够记录代码中许多点的延迟配置文件。 使用JLBH,您可以在程序中花费很少的开销将探针添加到代码中的任何位置。 JMH的设计使您只能从方法开始(@Benchmark)到结束进行测量。
- 您要测量OS和JVM的全局延迟。 JLBH运行一个单独的抖动线程。 这与您的程序并行运行,除了通过重复调用System.nanoTime()来采样延迟外,什么也没有做。 尽管这本身并不能告诉您太多信息,但这可以表明基准测试期间JVM的运行情况。 另外,您可以添加一个不执行任何操作的探针(稍后将对此进行说明),您可以在其中运行运行基准测试的代码的线程中采样延迟。 JMH没有这种功能。
如前所述,如果您不想使用这些功能中的一项或多项,而不是JMH而不是JLBH。
快速入门指南
可以在Chronicle-Core库中找到JLBH的代码,该库可以在GitHub上的此处找到。
要从Maven-Central下载,请将其包含在pom.xml中(检查最新版本):
<dependency>
<groupId>net.openhft</groupId>
<artifactId>chronicle-core</artifactId>
<version>1.4.7</version>
</dependency>要编写基准,您必须实现JLBHTask接口:
它只有两种方法需要实现:
- init(JLBH jlbh)传递了对JLBH的引用,您需要在基准测试完成后回调(jlbh.sampleNanos())。
- 运行(long startTime)在每次迭代上运行的代码。 在确定基准测试已花费了多长时间后,您需要保留开始时间,并回调jlbh.sampleNanos()。 JLBH计算sampleNanos()的调用次数,它必须与run()的调用次数完全匹配。 对于您可以创建的其他探针,情况并非如此。
- 第三种可选方法complete()可能对某些基准的清理有用。
所有这些最好在一个简单的示例中看到:
在这种情况下,我们测量将项目放到ArrayBlockingQueue上并再次取下需要多长时间。
我们添加探针以查看对put()和poll()的调用花费了多长时间。
我鼓励您运行此操作,以改变吞吐量和ArrayBlockingQueue的大小,并查看其区别。
如果将accountForCoordinatedOmission设置为true或false,您也可以看到它的区别。
package org.latency.prodcon;
import net.openhft.chronicle.core.jlbh.JLBH;
import net.openhft.chronicle.core.jlbh.JLBHOptions;
import net.openhft.chronicle.core.jlbh.JLBHTask;
import net.openhft.chronicle.core.util.NanoSampler;
import java.util.concurrent.*;
/**
* Simple test to demonstrate how to use JLBH
*/
public class ProducerConsumerJLBHTask implements JLBHTask {
private final BlockingQueue<Long> queue = new ArrayBlockingQueue(2);
private NanoSampler putSampler;
private NanoSampler pollSampler;
private volatile boolean completed;
public static void main(String[] args){
//Create the JLBH options you require for the benchmark
JLBHOptions lth = new JLBHOptions()
.warmUpIterations(40_000)
.iterations(100_000)
.throughput(40_000)
.runs(3)
.recordOSJitter(true)
.accountForCoordinatedOmmission(true)
.jlbhTask(new ProducerConsumerJLBHTask());
new JLBH(lth).start();
}
@Override
public void run(long startTimeNS) {
try {
long putSamplerStart = System.nanoTime();
queue.put(startTimeNS);
putSampler.sampleNanos(System.nanoTime() - putSamplerStart);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
@Override
public void init(JLBH lth) {
putSampler = lth.addProbe("put operation");
pollSampler = lth.addProbe("poll operation");
ExecutorService executorService = Executors.newSingleThreadExecutor();
executorService.submit(()->{
while(!completed) {
long pollSamplerStart = System.nanoTime();
Long iterationStart = queue.poll(1, TimeUnit.SECONDS);
pollSampler.sampleNanos(System.nanoTime() - pollSamplerStart);
//call back JLBH to signify that the iteration has ended
lth.sample(System.nanoTime() - iterationStart);
}
return null;
});
executorService.shutdown();
}
@Override
public void complete(){
completed = true;
}
}看一下JLBHOptions中包含的所有可用来设置JLBH基准的选项 。
在下一篇文章中,我们将查看JLBH基准的更多示例。
如果您对JLBH有任何反馈,请让我知道–如果您想贡献自己的力量来编录Chronicle-Core并发出拉取请求!
翻译自: https://www.javacodegeeks.com/2016/04/jlbh-introducing-java-latency-benchmarking-harness.html















 726
726

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









