





在大多数软件开发项目中,有一点需要使应用程序开始与其他应用程序或第三方组件通信。
无论是发送电子邮件通知,调用外部api,写入文件还是将数据从一个地方迁移到另一个地方,您都可以推出自己的解决方案或利用现有框架。
对于Java生态系统中的现有框架,我们可以发现Tibco BusinessWorks和Mule ESB ,另一方面是Spring Integration和Apache Camel 。
在本教程中,我将通过一个示例应用程序向您介绍Apache Camel ,该示例应用程序从Twitter的示例提要中读取推文,并使用Elastic Search实时索引这些推文。
什么是Apache Camel?

将应用程序与生态系统中的内部或外部组件集成是软件开发中最复杂的任务之一,如果操作不正确,则可能导致混乱不堪,并且长期维护很麻烦。
幸运的是,Camel是Apache托管的开放源代码集成框架,它基于企业集成模式 ,这些模式可以帮助编写更具可读性和可维护性的代码。 与Lego相似,这些模式可以用作构建可靠软件设计的基础。
Apache Camel还支持各种各样的连接器,以将您的应用程序与不同的框架和技术集成在一起。 顺便说一下,它也可以与Spring很好地配合使用。
如果您不熟悉Spring,那么您可能会发现这篇文章很有帮助: 使用Spring Boot处理Twitter feed 。
在以下各节中,我们将介绍一个示例应用程序,其中Camel与Twitter示例提要和ElasticSearch集成在一起。
什么是ElasticSearch?
类似于Apache Solr的 ElasticSearch是一个高度可扩展的开源,基于Java的全文本搜索引擎,构建在Apache Lucene之上。
在此示例应用程序中,我们将使用ElasticSearch实时索引推文,并在这些推文上提供全文本搜索功能。
其他使用的技术
除了Apache Camel和ElasticSearch,我还在此应用程序中包括其他框架: Gradle作为构建工具, Spring Boot作为Web应用程序框架,以及Twitter4j,用于从Twitter示例提要中读取推文。
入门
该项目的框架是在http://start.spring.io生成的,在该项目中,我检查了Web依赖项选项,填写了“项目元数据”部分,然后选择“ Gradle Project”作为项目类型。
生成项目后,您可以下载并将其导入您喜欢的IDE。 我现在不打算在Gradle上做更多的细节,但是这是build.gradle文件中所有依赖项的列表:
def camelVersion = '2.15.2'
dependencies {
compile("org.springframework.boot:spring-boot-starter-web")
compile("org.apache.camel:camel-core:${camelVersion}")
compile("org.apache.camel:camel-spring-boot:${camelVersion}")
compile("org.apache.camel:camel-twitter:${camelVersion}")
compile("org.apache.camel:camel-elasticsearch:${camelVersion}")
compile("org.apache.camel:camel-jackson:${camelVersion}")
compile("joda-time:joda-time:2.8.2")
testCompile("org.springframework.boot:spring-boot-starter-test")
}使用骆驼路线进行整合
骆驼实现了面向消息的体系结构,它的主要构建模块是描述消息流的路由 。
可以使用XML(旧方式)或其Java DSL(新方式)描述路由。 我们将在本文中仅讨论Java DSL,因为这是首选且更优雅的选择。
好吧,让我们看一个简单的Route:
from("file://orders").
convertBodyTo(String.class).
to("log:com.mycompany.order?level=DEBUG").
to("jms:topic:OrdersTopic");这里有几件事要注意:
- 消息在由URI表示并使用URI配置的端点之间流动
- 路由只能有一个消息生产者端点(在本例中为“ file:// orders”,它从orders文件夹中读取文件)和多个消息消费者端点:
- “ log:com.mycompany.order?level = DEBUG”,它将文件的内容记录在com.mycompany.order日志记录类别下的调试消息中,
- 在端点之间可以更改消息,即:convertBodyTo(String.class)将消息正文转换为String。
另请注意,相同的URI可以在一个路由中用于消费者端点,而在另一路由中用于生产者端点:
from("file://orders").
convertBodyTo(String.class).
to("direct:orders");
from("direct:orders).
to("log:com.mycompany.order?level=DEBUG").
to("jms:topic:OrdersTopic");Direct端点是通用端点之一,它允许将消息从一条路由同步传递到另一条路由。
这有助于创建可读代码并在代码的多个位置重用路由。
索引推文
现在,让我们看一下代码中的一些路由。 让我们从简单的事情开始:
private String ES_TWEET_INDEXER_ENDPOINT = "direct:tweet-indexer-ES";
...
from("twitter://streaming/sample?type=EVENT&consumerKey={{twitter4j.oauth.consumerKey}}&consumerSecret={{twitter4j.oauth.consumerSecret}}∾cessToken={{twitter4j.oauth.accessToken}}∾cessTokenSecret={{twitter4j.oauth.accessTokenSecret}}")
.to(ES_TWEET_INDEXER_ENDPOINT)
;这是如此简单,对吧? 到现在为止,您可能已经知道该路由从Twitter示例提要中读取了推文,并将它们传递到“ direct:tweet-indexer-ES”端点。 请注意,consumerKey,consumerSecret等已配置并作为系统属性传递(请参见http://twitter4j.org/en/configuration.html )。
现在,让我们看一个稍微复杂的Route,该路由从“ direct:tweet-indexer-ES”端点读取,并将Tweets批量插入到Elasticsearch中(有关每个步骤的详细说明,请参见注释):
@Value("${elasticsearch.tweet.uri}")
private String elasticsearchTweetUri;
...
from(ES_TWEET_INDEXER_ENDPOINT)
// groups tweets into separate indexes on a weekly basis to make it easier clean up old tweets:
.process(new WeeklyIndexNameHeaderUpdater(ES_TWEET_INDEX_TYPE))
// converts Twitter4j Tweet object into an elasticsearch document represented by a Map:
.process(new ElasticSearchTweetConverter())
// collects tweets into weekly batches based on index name:
.aggregate(header("indexName"), new ListAggregationStrategy())
// creates new batches every 2 seconds
.completionInterval(2000)
// makes sure the last batch will be processed before the application shuts down:
.forceCompletionOnStop()
// inserts a batch of tweets to elasticsearch:
.to(elasticsearchTweetUri)
.log("Uploaded documents to ElasticSearch index ${headers.indexName}: ${body.size()}")
;关于此路线的注意事项:
- elasticsearchTweetUri是一个字段,其值由Spring从application.properties文件(elasticsearch.tweet.uri = elasticsearch:// tweet-indexer?operation = BULK_INDEX&ip = 127.0.0.1&port = 9300)中获取并注入到该字段中
- 为了在Route中实现自定义处理逻辑,我们可以创建实现Processor接口的类。 参见WeeklyIndexNameHeaderUpdater和ElasticSearchTweetConverter
- 使用自定义ListAggregationStrategy策略聚合推文,该策略将消息聚合到ArrayList中,稍后每2秒(或在应用程序停止时)传递给下一个终结点
- Camel实现了一种表达语言 ,我们正在使用该语言记录批处理的大小(“ $ {body.size()}”)和插入消息的索引的名称($ {headers.indexName})。
在Elasticsearch中搜索推文
现在我们已经在Elasticsearch中索引了推文,是时候对其进行一些搜索了。
首先,让我们看一下接收搜索查询的Route和限制搜索结果数量的maxSize参数:
public static final String TWEET_SEARCH_URI = "vm:tweetSearch";
...
from(TWEET_SEARCH_URI)
.setHeader("CamelFileName", simple("tweet-${body}-${header.maxSize}-${date:now:yyyyMMddHHmmss}.txt"))
// calls the search() method of the esTweetService which returns an iterator
// to process search result - better than keeping the whole resultset in memory:
.split(method(esTweetService, "search"))
// converts Elasticsearch doucment to Map object:
.process(new ElasticSearchSearchHitConverter())
// serializes the Map object to JSON:
.marshal(new JacksonDataFormat())
// appends new line at the end of every tweet
.setBody(simple("${body}\n"))
// write search results as json into a file under /tmp folder:
.to("file:/tmp?fileExist=Append")
.end()
.log("Wrote search results to /tmp/${headers.CamelFileName}")
;当消息传递到“ vm:tweetSearch”端点(该端点使用内存队列异步处理消息)时,将触发此路由。
SearchController类实现了REST api,允许用户通过使用Camel的ProducerTemplate类将消息发送到“ vm:tweetSearch”端点来运行tweet搜索:
@Autowired
private ProducerTemplate producerTemplate;
@RequestMapping(value = "/tweet/search", method = { RequestMethod.GET, RequestMethod.POST },
produces = MediaType.TEXT_PLAIN_VALUE)
@ResponseBody
public String tweetSearch(@RequestParam("q") String query,
@RequestParam(value = "max") int maxSize) {
LOG.info("Tweet search request received with query: {} and max: {}", query, maxSize);
Map<String, Object> headers = new HashMap<String, Object>();
// "content" is the field in the Elasticsearch index that we'll be querying:
headers.put("queryField", "content");
headers.put("maxSize", maxSize);
producerTemplate.asyncRequestBodyAndHeaders(CamelRouter.TWEET_SEARCH_URI, query, headers);
return "Request is queued";
}这将触发Elasticsearch的执行,但是结果不会在响应中返回,而是写入/ tmp文件夹中的文件(如前所述)。
此路由使用ElasticSearchService类在ElasticSearch中搜索推文。 当执行此Route时,Camel调用search()方法并传递搜索查询和maxSize作为输入参数:
public SearchHitIterator search(@Body String query, @Header(value = "queryField") String queryField, @Header(value = "maxSize") int maxSize) {
boolean scroll = maxSize > batchSize;
LOG.info("Executing {} on index type: '{}' with query: '{}' and max: {}", scroll ? "scan & scroll" : "search", indexType, query, maxSize);
QueryBuilder qb = termQuery(queryField, query);
long startTime = System.currentTimeMillis();
SearchResponse response = scroll ? prepareSearchForScroll(maxSize, qb) : prepareSearchForRegular(maxSize, qb);
return new SearchHitIterator(client, response, scroll, maxSize, KEEP_ALIVE_MILLIS, startTime);
}请注意,根据maxSize和batchSize,代码将执行常规搜索以返回单页结果,或者执行滚动请求以使我们能够检索大量结果。 在滚动的情况下, SearchHitIterator将随后对Elasticsearch进行调用,以分批检索结果。
安装ElasticSearch
- 从https://www.elastic.co/downloads/elasticsearch下载Elasticsearch。
- 将其安装到本地文件夹($ ES_HOME)
- 编辑$ ES_HOME / config / elasticsearch.yml并添加以下行:
cluster.name:tweet-indexer - 安装BigDesk插件以监视Elasticsearch:$ ES_HOME / bin / plugin -install lukas-vlcek / bigdesk
- 运行Elasticsearch:$ ES_HOME / bin / elasticsearch.sh或$ ES_HOME / bin / elasticsearch.bat
这些步骤将允许您以最少的配置运行独立的Elasticsearch实例,但请记住,它们并非供生产使用。
运行
这是应用程序的入口点,可以从命令行运行。
package com.kaviddiss.twittercamel;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}要运行该应用程序,请从您最喜欢的IDE运行Application.main()方法,或者从命令行执行以下代码:
$GRADLE_HOME/bin/gradlew build && java -jar build/libs/twitter-camel-ingester-0.0.1-SNAPSHOT.jar一旦应用程序启动,它将自动开始索引推文。 转到http:// localhost:9200 / _plugin / bigdesk /#cluster可视化索引:
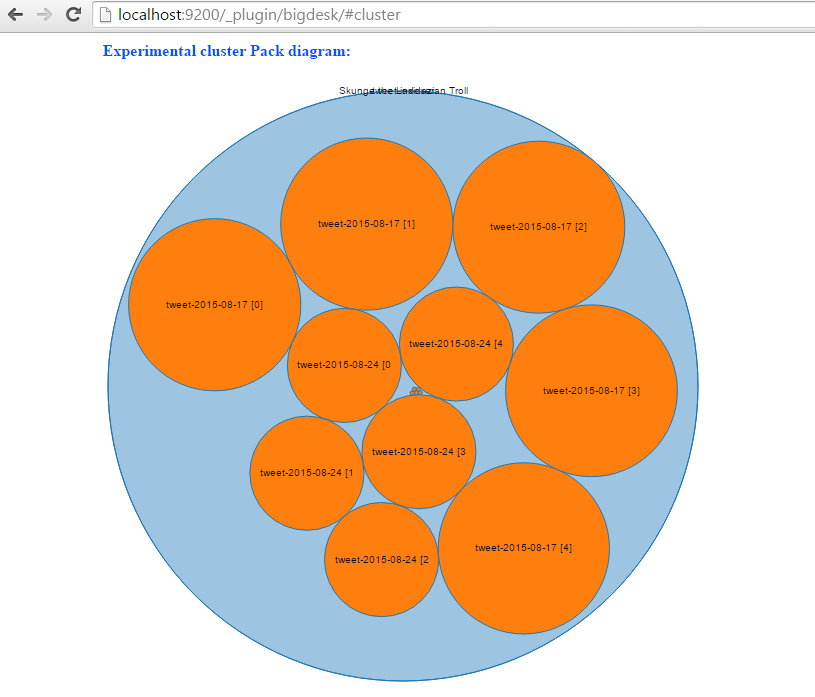
要搜索推文,请在浏览器中输入与此类似的URL: http:// localhost:8080 / tweet / search?q = toronto&max = 100 。

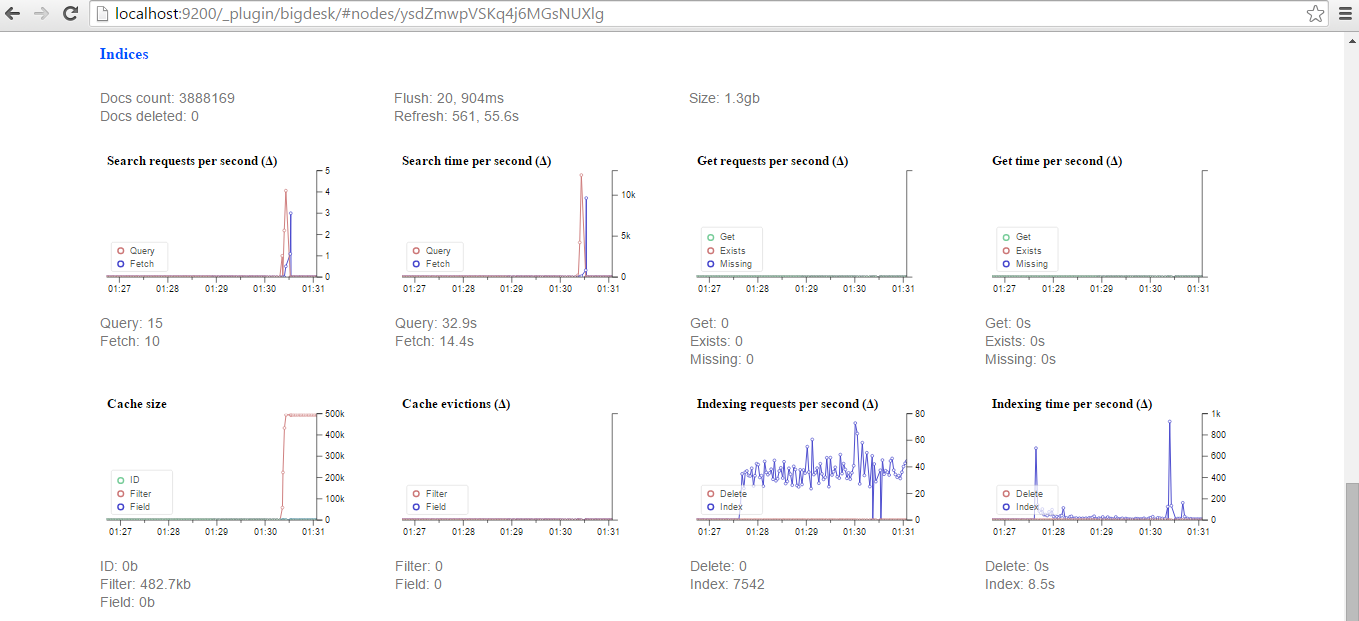
使用BigDesk插件,我们可以监视Elasticsearch如何索引推文:
结论
在Apache Camel的简介中,我们介绍了如何使用此集成框架与Twitter提要feed和Elasticsearch之类的外部组件进行通信,以实时索引和搜索推文。
- 示例应用程序的源代码可从https://github.com/davidkiss/twitter-camel-ingester获得 。
翻译自: https://www.javacodegeeks.com/2015/09/learn-apache-camel-indexing-tweets-in-real-time.html















 1026
1026

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









