





介绍
Hibernate支持三种数据映射类型 : 基本 (例如String,int), Embeddable和Entity 。 通常,数据库行映射到Entity ,每个数据库列都与一个基本属性关联。 当将多个字段映射组合到一个可重用的组中时, 可嵌入的类型更为常见( Embeddable被合并到拥有的实体映射结构中)。
基本类型和可嵌入对象都可以通过@ElementCollection ,以一个实体-很多-非实体的关系关联到一个实体 。
测试时间
对于即将到来的测试用例,我们将使用以下实体模型:
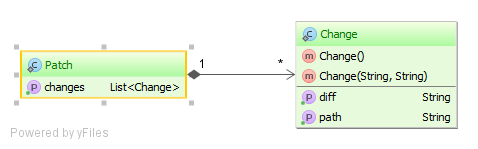
修补程序具有变更可嵌入对象的集合。
@ElementCollection
@CollectionTable(
name="patch_change",
joinColumns=@JoinColumn(name="patch_id")
)
private List<Change> changes = new ArrayList<>();Change对象建模为Embeddable类型,并且只能通过其所有者Entity进行访问。 Embeddable没有标识符 ,因此无法通过JPQL查询。 Embeddable生命周期绑定到其所有者的生命周期,因此任何实体状态转换都会自动传播到Embeddable集合。
首先,我们需要添加一些测试数据:
doInTransaction(session -> {
Patch patch = new Patch();
patch.getChanges().add(
new Change("README.txt", "0a1,5...")
);
patch.getChanges().add(
new Change("web.xml", "17c17...")
);
session.persist(patch);
});添加一个新元素
让我们看看将新的Change添加到现有Patch时会发生什么:
doInTransaction(session -> {
Patch patch = (Patch) session.get(Patch.class, 1L);
patch.getChanges().add(
new Change("web.xml", "1d17...")
);
});此测试生成以下SQL输出:
DELETE FROM patch_change
WHERE patch_id = 1
INSERT INTO patch_change (patch_id, diff, path)
VALUES (1, '0a1,5...', 'README.txt')
INSERT INTO patch_change(patch_id, diff, path)
VALUES (1, '17c17...', 'web.xml')
INSERT INTO patch_change(patch_id, diff, path)
VALUES (1, '1d17...', 'web.xml')默认情况下,任何收集操作最终都会重新创建整个数据集。 这种行为仅对于内存中的集合是可接受的,并且从数据库的角度来看是不合适的。 数据库必须删除所有现有的行,而只是重新添加它们的后缀。 我们在此表上拥有的索引越多,性能损失就越大。
删除元素
删除元素没有什么不同:
doInTransaction(session -> {
Patch patch = (Patch) session.get(Patch.class, 1L);
patch.getChanges().remove(0);
});此测试用例生成以下SQL语句:
DELETE FROM patch_change
WHERE patch_id = 1
INSERT INTO patch_change(patch_id, diff, path)
VALUES (1, '17c17...', 'web.xml')删除了所有表行,并将剩余的内存中条目刷新到数据库中。
Java Persistence Wiki Book清楚地记录了这种行为:
JPA 2.0规范没有提供在Embeddable中定义ID的方法。 但是,要删除或更新ElementCollection映射的元素,通常需要一些唯一键。 否则,在每次更新时,JPA提供程序都需要从Entity的CollectionTable中删除所有内容,然后将这些值重新插入。 因此,JPA提供程序将最有可能假定Embeddable中所有字段的组合与外键(JoinColumn(s))组合在一起是唯一的。 但是,如果Embeddable很大或很复杂,这可能效率很低,或者根本不可行。
一些JPA提供程序可能允许在可嵌入对象中指定ID,以解决此问题。 请注意,在这种情况下,Id仅对于集合(表)而言是唯一的,因为其中包括外键。 有些可能还允许将CollectionTable上的唯一选项用于此目的。 否则,如果您的Embeddable很复杂,则可以考虑将其设为实体,而改用OneToMany。
添加一个OrderColumn
为了优化ElementCollection行为,我们需要应用适用于一对多关联的相同技术。 元素的集合就像是单向的一对多关系,并且我们已经知道idbag的 性能比单向bag更好 。
因为可嵌入对象不能包含标识符,所以我们至少可以添加一个订单列,以便可以唯一地标识每一行。 让我们看看将@OrderColumn添加到元素集合时会发生什么:
@ElementCollection
@CollectionTable(
name="patch_change",
joinColumns=@JoinColumn(name="patch_id")
)
@OrderColumn(name = "index_id")
private List<Change> changes = new ArrayList<>();删除实体后,以前的测试结果没有任何改善:
DELETE FROM patch_change
WHERE patch_id = 1
INSERT INTO patch_change(patch_id, diff, path)
VALUES (1, '17c17...', 'web.xml')这是因为在阻止重新创建集合时, AbstractPersistentCollection将检查可为空的列:
@Override
public boolean needsRecreate(CollectionPersister persister) {
if (persister.getElementType() instanceof ComponentType) {
ComponentType componentType =
(ComponentType) persister.getElementType();
return !componentType.hasNotNullProperty();
}
return false;
}现在,我们将添加NOT NULL约束并重新运行测试:
@Column(name = "path", nullable = false)
private String path;
@Column(name = "diff", nullable = false)
private String diff;添加一个新的有序元素
将元素添加到列表的末尾将生成以下语句:
INSERT INTO patch_change(patch_id, index_id, diff, path)
VALUES (1, 2, '1d17...', 'web.xml')index_id列用于持久存储内存中的收集顺序。 添加到集合的末尾不会影响现有元素的顺序,因此仅需要一个INSERT语句。
添加一个新的第一个元素
如果我们在列表的开头添加一个新元素:
doInTransaction(session -> {
Patch patch = (Patch) session.get(Patch.class, 1L);
patch.getChanges().add(0,
new Change("web.xml", "1d17...")
);
});生成以下SQL输出:
UPDATE patch_change
SET diff = '1d17...',
path = 'web.xml'
WHERE patch_id = 1
AND index_id = 0
UPDATE patch_change
SET diff = '0a1,5...',
path = 'README.txt'
WHERE patch_id = 1
AND index_id = 1
INSERT INTO patch_change (patch_id, index_id, diff, path)
VALUES (1, 2, '17c17...', 'web.xml')现有数据库条目已更新,以反映新的内存中数据结构。 由于新添加的元素已添加到列表的开头,因此它将触发对表的第一行的更新。 所有INSERT语句在列表的末尾发出,并且所有现有元素均根据新的列表顺序进行更新。
@OrderColumn Java持久性文档中对此行为进行了说明:
当更新关联或元素集合时,持久性提供程序维护order列的值的连续(非稀疏)排序。 第一个元素的订单列值为0。
删除有序元素
如果我们删除最后一个条目:
doInTransaction(session -> {
Patch patch = (Patch) session.get(Patch.class, 1L);
patch.getChanges().remove(patch.getChanges().size() - 1);
});仅发出一个DELETE语句:
DELETE FROM patch_change
WHERE patch_id = 1
AND index_id = 1删除第一个元素条目
如果删除第一个元素,则会执行以下语句:
DELETE FROM patch_change
WHERE patch_id = 1
AND index_id = 1
UPDATE patch_change
SET diff = '17c17...',
path = 'web.xml'
WHERE patch_id = 1
AND index_id = 0Hibernate删除所有多余的行,然后更新其余的行。
从中间删除
如果我们从列表中间删除一个元素:
doInTransaction(session -> {
Patch patch = (Patch) session.get(Patch.class, 1L);
patch.getChanges().add(new Change("web.xml", "1d17..."));
patch.getChanges().add(new Change("server.xml", "3a5..."));
});
doInTransaction(session -> {
Patch patch = (Patch) session.get(Patch.class, 1L);
patch.getChanges().remove(1);
});执行以下语句:
DELETE FROM patch_change
WHERE patch_id = 1
AND index_id = 3
UPDATE patch_change
SET diff = '1d17...',
path = 'web.xml'
WHERE patch_id = 1
AND index_id = 1
UPDATE patch_change
SET diff = '3a5...',
path = 'server.xml'
WHERE patch_id = 1
AND index_id = 2有序ElementCollection的更新如下:
- 调整数据库表的大小, DELETE语句删除位于表末尾的多余行。 如果内存中的集合大于数据库中的集合,则所有INSERT语句将在列表的末尾执行
- 添加/删除条目之前的所有元素均保持不变
- 添加/删除元素之后的其余元素将更新以匹配新的内存中收集状态
结论
与一对多 反向关联相比, ElementCollection更难优化。 如果集合经常更新,则最好用一对多关联替换元素集合。 当我们不想为表示外键端添加额外的实体时,元素集合更适合于很少更改的数据。
- 代码可在GitHub上获得 。
翻译自: https://www.javacodegeeks.com/2015/05/how-to-optimize-hibernate-ellementcollection-statements.html















 845
845

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









