





Spring XD是一个功能强大的工具,它是一组可安装的Spring Boot服务,可以独立运行,在YARN或EC2之上运行。 Spring XD还包括一个管理UI网站和一个用于作业和流管理的命令行工具。 Spring XD是一组功能强大的服务,可与各种数据源一起使用。
为了达到理想的使用效果,它应该在Apache Spark或Hadoop集群中运行。 在第一部分中,我们将设置XD使其在具有必要数据服务的Centos / RHEL机器上运行。 这些用于运行所需的基础结构以及数据摄取。 您可以集成现有的RDBMS,MongoDB,Kafka,Apache Spark,Hadoop,REST,RabbitMQ和其他服务。
您还可以在Mac,Windows和其他Linux发行版上安装XD。 对于开发人员机器上的基本用法,只需从Spring.IO网站下载Spring XD并运行xd / xd / bin / xd-standalone,这足以运行数据提取。
1. Spring XD设置
首先,让我们在您的Linux服务器上安装Spring XD,注意其运行要求。 如果您没有所需的服务,则XD下载包含它们的版本供您运行。
参考:
- http://docs.spring.io/spring-xd/docs/current/reference/html/#_redhat_centos_installation
- https://github.com/spring-projects/spring-xd/wiki/Running-Distributed-Mode
- https://github.com/spring-projects/spring-xd/wiki/XD-Distributed-Runtime
要求:
- Apache Zookeeper 3.4.6
- 雷迪斯
- RDBMS(MySQL,Postgresql,Apache Derby等)
浓缩机:
- GemFire(强烈建议用于内存数据网格)
- GemFire XD(强烈建议用于内存数据库)
- RabbitMQ(强烈推荐)
- 阿帕奇纱线
在Centos / RHEL / Fedora上安装MySQL
需要一个关系数据库来存储您的工作信息,而可以使用内存中的RDBMS,但为了实际使用,应使用RDBMS。 如果您有可从XD群集访问的RDBMS,则可以使用它。 我更喜欢将开放源代码数据库仅用于XD,您可以为此安装MySQL或Postgresql。
sudo yum install mysql-server安装Postgresql(不要与GreenPlum安装在同一台计算机上)
sudo yum install postgresql-server安装Redis
(请参阅RabbitMQ)
ᅠwget -q -O – http://packages.pivotal.io/pub/rpm/rhel6/app-suite/app-suite-installer | sh
ᅠ ᅠ ᅠ ᅠ ᅠ ᅠsudo yum install pivotal-redis
ᅠ ᅠ ᅠ ᅠ ᅠ ᅠsudo service pivotal-redis-6379 start
ᅠ ᅠ ᅠ ᅠ ᅠ ᅠsudo chkconfig —level 35 pivotal-redis-6379 on安装RabbitMQ
即使您有另一个消息队列,也需要RabbitMQ。 单个节点就足够了,但是通信需要它。 我强烈建议您使用真正的RMQ群集,因为它适合大多数流媒体需求。
ᅠ
sudo wget -q -O – packages.pivotal.io | sh
sudo wget -q -O – http://packages.pivotal.io/pub/rpm/rhel6/app-suite/app-suite-installer | sh根据权限的不同,您可能必须将其发送到文件,将其更改为chmod 700并通过sudo ./installer.sh运行。
ᅠ
sudo yum search pivotal
pivotal-rabbitmq-server.noarch: The RabbitMQ server
sudo yum install pivotal-rabbitmq-server
sudo rabbitmq-plugins enable rabbitmq_management ᅠ ᅠ如果您正在该计算机上运行其他内容,则可能与端口冲突。
ᅠ
sudo /sbin/service rabbitmq-server start安装Spring-XD
最简单的安装方法是使用Pivotal的RHEL官方版本,因为它们已通过认证。 您不需要成为客户就可以使用它们。 还有许多其他方式来下载/安装XD,但这对于RHEL是最简单的,因为它将配置它们为服务。
sudo wget -q -O – http://packages.pivotal.io/pub/rpm/rhel6/app-suite/app-suite-installer sh
sudo yum install spring-xd建议
还建议在同一容器内部署XD节点和DataNode并使用数据分区。 这将加速数据处理和提取。
设置工作数据库
更改数据源,选择以下一项以进行最简单的设置。 作业数据库是存储Spring XD作业信息和元数据的地方。 这是必要的。 这将是非常少量的数据。
/opt/pivotal/spring-xd/xd/config
ᅠ#spring:
# ᅠdatasource:
# ᅠ ᅠurl: jdbc:mysql://mysqlserver:3306/xdjobs
# ᅠ ᅠusername: xdjobsschema
# ᅠ ᅠpassword: xdsecurepassword
# ᅠ ᅠdriverClassName: com.mysql.jdbc.Driver
# ᅠ ᅠvalidationQuery: select 1
#Config for use with Postgres - uncomment and edit with relevant values for your environment
#spring:
# ᅠdatasource:
# ᅠ ᅠurl: jdbc:postgresql://postgresqlserver:5432/xdjobs
# ᅠ ᅠusername: xdjobsschema
# ᅠ ᅠpassword: xdsecurepassword
# ᅠ ᅠdriverClassName: org.postgresql.Driver
# ᅠ ᅠvalidationQuery: select 1测试Spring-XD单节点是否正常工作:
cd /opt/pivotal/springxd/xd/bin
./xd-singlenode —hadoopDistro phd20如果您使用的是与Pivotal HD 2.0不同的Hadoop发行版,则可以在此处指定该标记或将其保留为关闭状态。
测试Spring-XD Shell是否有效
cd /opt/pivotal/springxd/shell/bin
ᅠ ᅠ ./xd-shell—hadoopDistro phd20该外壳程序具有帮助和快捷方式,只需开始键入,Tab即可为您解析名称和参数。
设置Spring XD的环境变量
export XD_HOME=/opt/pivotal/spring-xd/xd对于默认访问,我使用:
/opt/pivotal/spring-xd/shell/bin/xd-shell —hadoopDistro phd20用于测试分布式Spring XD(DIRT)的容器和管理服务器
sudo service spring-xd-admin start
sudo service spring-xd-container start用于测试Spring XD
- http://blog.pivotal.io/pivotal/products/spring-xd-for-real-time-analytics
- https://github.com/spring-projects/spring-xd-samples
一些Spring XD Shell命令进行测试
had config fs —namenode hdfs://pivhdsne:8020
admin config server http://localhost:9393
runtime containers
runtime modules
hadoop fs ls /xd/
stream create ticktock —definition “time | log”
stream deploy ticktock
stream list 
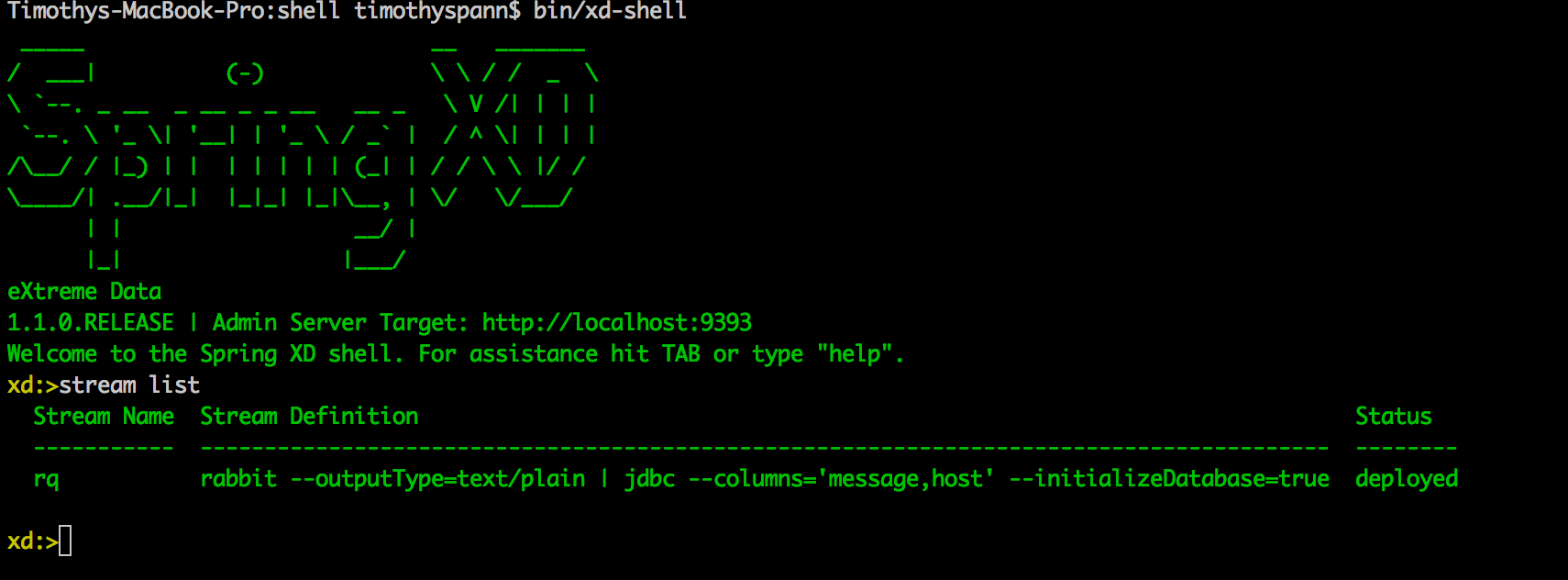
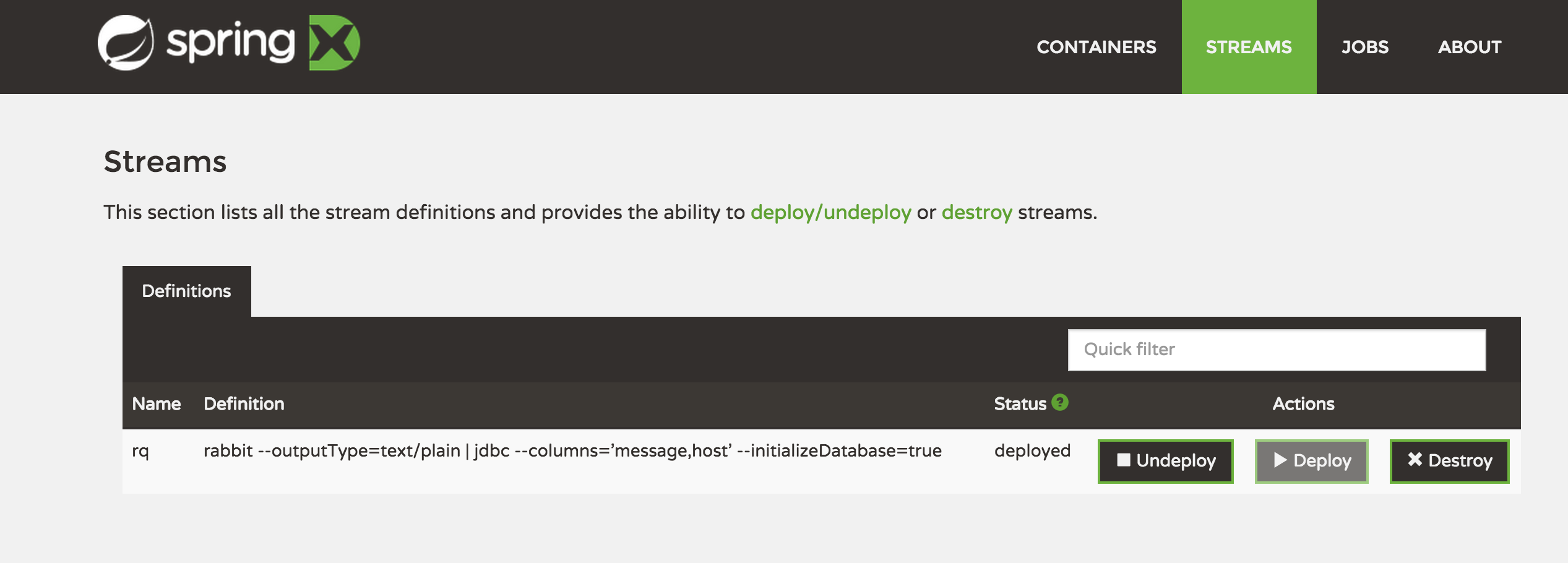
检查网页界面
2. Spring XD Job and Stream with SQL
注意:为了节省空间,完整的字段列表被缩写,您必须列出所有正在使用的字段。
首先,我们创建一个简单的filejdbc Spring Job,它将原始代字号分隔的文件加载到HAWQ中 。 这些字段都以TEXT字段形式出现,出于某些目的,这可能是可以的,但对于我们的需求而言不是。 我们还使用自定义接收器(请参阅XML,无编码)创建XD流,该流运行SQL命令从该表插入并转换为其他HAWQ类型(例如数字和时间)。
我们通过命令行REST POST触发辅助流,但是我们可以使用定时触发或许多其他方式(自动,脚本或手动)来启动辅助流。 您也可以只创建一个自定义XD作业,该作业完成类型的转换和一些操作,或者通过Groovy脚本转换完成。 XD中有很多选项。
jobload.xd
job create loadjob --definition "filejdbc --resources=file:/tmp/xd/input/files/*.* --names=time,userid,dataname,dataname2,
dateTimeField, lastName, firstName, city, state, address1, address2 --tableName=raw_data_tbl --initializeDatabase=true
--driverClassName=org.postgresql.Driver --delimiter=~ --dateFormat=yyyy-MM-dd-hh.mm.ss --numberFormat=%d
--username=gpadmin --url=jdbc:postgresql:gpadmin" --deploy
stream create --name streamload --definition "http | hawq-store" --deploy
job launch jobload
clear
job list
stream list- 作业将包含所有文本列的文件加载到Raw HAWQ表中。
- 流是由网页命中或命令行调用触发的
(需要hawq-store)。 这确实会插入到实际表中并截断临时表。
triggerrun.sh(用于测试的BASH Shell脚本)
curl -s -H "Content-Type: application/json" -X POST -d "{id:5}" http://localhost:9000将spring-integration-jdbc jar添加到/ opt / pivotal / spring-xd / xd / lib
hawq-store.xml(Spring集成/ XD配置)
/opt/pivotal/spring-xd/xd/modules/sink/hawq-store.xml
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:int="http://www.springframework.org/schema/integration"
xmlns:int-jdbc="http://www.springframework.org/schema/integration/jdbc"
xmlns:jdbc="http://www.springframework.org/schema/jdbc"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/integration
http://www.springframework.org/schema/integration/spring-integration.xsd
http://www.springframework.org/schema/integration/jdbc
http://www.springframework.org/schema/integration/jdbc/spring-integration-jdbc.xsd">
<int:channel id="input" />
<int-jdbc:store-outbound-channel-adapter
channel="input" query="insert into real_data_tbl(time, userid, firstname, ...) select cast(time as datetime),
cast(userid as numeric), firstname, ... from dfpp_networkfillclicks" data-source="dataSource" />
<bean id="dataSource" class="org.springframework.jdbc.datasource.DriverManagerDataSource">
<property name="driverClassName" value="org.postgresql.Driver"/>
<property name="url" value="jdbc:postgresql:gpadmin"/>
<property name="username" value="gpadmin"/>
<property name="password" value=""/>
</bean>
</beans>createtable.sql
CREATE TABLEᅠraw_data_tbl
(
time text,
userid text ,
...
somefieldᅠtext
)
WITH (APPENDONLY=true)
DISTRIBUTED BY (time);3. Shell的Spring XD脚本
我的常规安装脚本(我将其保存在setup.xd中,并通过ᅠ script –file setup.xd加载它)
had config fs --namenode hdfs://localhost:8020
admin config server http://localhost:9393
hadoop fs ls /
stream list通过Spring-XD将文件加载到GemFireXD的脚本
stream create --name fileload --definition "file --dir=/tmp/xd/input/load --outputType=text/plain | ᅠjdbc --tableName=APP.filetest --columns=id,name" --deploy4. GemFire XD的Spring XD配置
将GemFire XD JDBC驱动程序复制到Spring-XD(可能也需要tools.jar)
cp /usr/lib/gphd/Pivotal_GemFireXD_10/lib/gemfirexd-client.jar /opt/pivotal/spring-xd/xd/lib/修改接收器的JDBC属性以指向您的Gemfire XD,如果您使用的是Pivotal HD VM并安装带有Yum的Spring-XD(sudo yum update spring-xd),则此位置:
/opt/pivotal/spring-xd/xd/config/modules/sink/jdbc/jdbc.properties
url = jdbc:gemfirexd://localhost:1527
username = gfxd
password = gfxd
driverClassName = com.pivotal.gemfirexd.jdbc.ClientDriver对于Peer Client Driver,您需要GemFireXD Lib(.so二进制文件)中的更多文件,链接可能是一个好主意。
5. GemFire XD设置
gfxd
connect client 'localhost:1527';
create table filetest (id int, name varchar(100)) REPLICATE PERSISTENT;
select id, kind, netservers from sys.members;ᅠ
select * from filetest;Spring XD命令
stream list显示你的流
参考:
- Spring XD文档
- Spring XD Wiki
- 在Centos上安装Spring XD
- GemFire XD文档
- Spring XD文件 提取 到JDBC中
- 带有Hadoop的Spring XD
6.通过Spring XD将数据从RabbitMQ导入RDBMS
从名为“ rq”的Rabbit队列读取的简单流,并将其发送到“消息和主机”列的SQL数据库,从而创建名为“ rq”的新表。
stream create --name rq --definition "rabbit --outputType=text/plain | jdbc --columns='message,host' --initializeDatabase=true" --deploy7.通过Spring XD将数据从REST API导入HDFS
stream create --name hdfssave --definition "http | hdfs" –deploy翻译自: https://www.javacodegeeks.com/2015/03/spring-xd-for-data-ingestion.html















 693
693











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









