





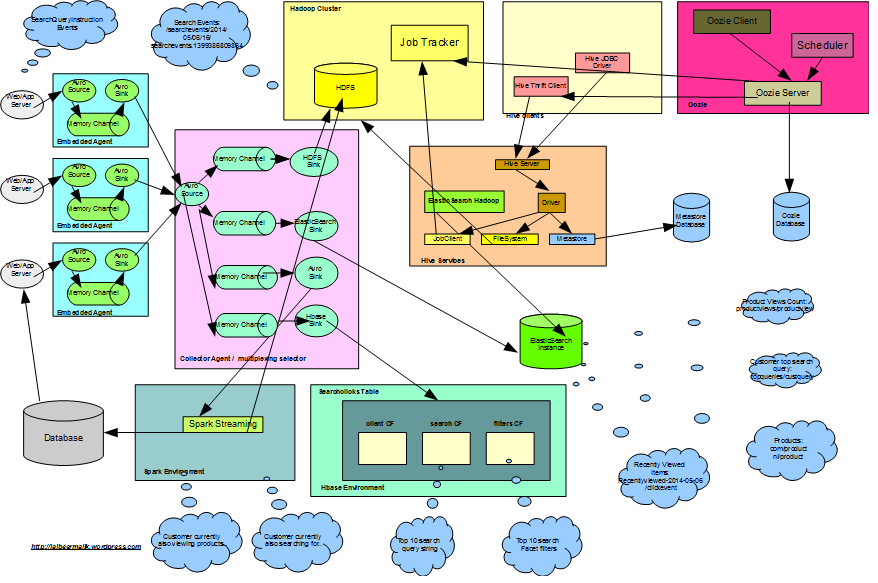
在本文中,我们将探索HBase来存储客户搜索点击事件数据,并利用其基于搜索查询字符串和构面过滤器点击来获取客户行为信息。 我们将介绍如何使用MiniHBaseCluster,HBase Schema设计,使用HBaseSink与Flume集成以存储JSON数据。
在之前的文章的基础上,
- 客户产品搜索使用大数据进行点击分析 ,
- Flume:使用Apache Flume收集客户产品搜索点击数据 ,
- Hive:使用Apache Hive查询客户最喜欢的搜索查询和产品视图计数 ,
- ElasticSearch-Hadoop:将产品视图计数和从Hadoop到ElasticSearch的客户顶部搜索查询建立索引 ,
- Oozie:为Hive分区和ElasticSearch索引安排协调器/捆绑作业 ,
- Spark:大数据的实时分析,可用于热门搜索查询和热门产品视图
我们已经探索了将搜索点击事件数据存储在Hadoop中并使用不同的技术对其进行查询。 在这里,我们将使用HBase实现相同的目的:
- HBase小型集群设置
- 使用Spring Data的HBase模板
- HBase模式设计
- 使用HBaseSink进行Flume集成
- HBaseJsonSerializer序列化json数据
- 查询过去一个小时的前10个搜索查询字符串
- 查询过去一个小时的前10个搜索方面过滤器
- 获取最近30天内客户的最近搜索查询字符串
HBase的
HBase “是Hadoop数据库,一个分布式,可扩展的大数据存储。”
HBaseMiniCluster / MiniZookeperCluster
要设置和启动小型集群,请检查HBaseServiceImpl.java
...
miniZooKeeperCluster = new MiniZooKeeperCluster();
miniZooKeeperCluster.setDefaultClientPort(10235);
miniZooKeeperCluster.startup(new File("taget/zookeper/dfscluster_" + UUID.randomUUID().toString()).getAbsoluteFile());
...
Configuration config = HBaseConfiguration.create();
config.set("hbase.tmp.dir", new File("target/hbasetom").getAbsolutePath());
config.set("hbase.master.port", "44335");
config.set("hbase.master.info.port", "44345");
config.set("hbase.regionserver.port", "44435");
config.set("hbase.regionserver.info.port", "44445");
config.set("hbase.master.distributed.log.replay", "false");
config.set("hbase.cluster.distributed", "false");
config.set("hbase.master.distributed.log.splitting", "false");
config.set("hbase.zookeeper.property.clientPort", "10235");
config.set("zookeeper.znode.parent", "/hbase");
miniHBaseCluster = new MiniHBaseCluster(config, 1);
miniHBaseCluster.startMaster();
...MiniZookeeprCluster在客户端端口10235上启动,所有客户端连接都将在此端口上。 确保将hbase服务器端口配置为不与其他本地hbase服务器冲突。 在这里,我们仅在测试案例中启动一台hbase区域服务器。
使用Spring数据的HBase模板
我们将使用Spring hbase模板连接到HBase集群:
<hdp:hbase-configuration id="hbaseConfiguration" configuration-ref="hadoopConfiguration" stop-proxy="false" delete-connection="false" zk-quorum="localhost" zk-port="10235">
</hdp:hbase-configuration>
<bean id="hbaseTemplate" class="org.springframework.data.hadoop.hbase.HBaseTemplate" p:configuration-ref="hbaseConfiguration" />HBase表架构设计
我们具有以下格式的搜索点击事件JSON数据,
{"eventid":"24-1399386809805-629e9b5f-ff4a-4168-8664-6c8df8214aa7","hostedmachinename":"192.168.182.1330","pageurl":"http://blahblah:/5" ;,"customerid":24,"sessionid":"648a011d-570e-48ef-bccc-84129c9fa400","querystring":null,"sortorder":"desc","pagenumber":3,"totalhits":28,"hitsshown":7,"createdtimestampinmillis":1399386809805,"clickeddocid":"41","favourite":null,"eventidsuffix":"629e9b5f-ff4a-4168-8664-6c8df8214aa7","filters":[{"code":"searchfacettype_color_level_2","value":"Blue"},{"code":"searchfacettype_age_level_2","value":"12-18 years"}]}
处理数据的一种方法是将其直接存储在一个列族和json列下。 这样扫描json数据将变得不那么容易和灵活。 另一种选择是将其存储在一个列族下,但具有不同的列。 但是将过滤器数据存储在单列中将很难进行扫描。 下面的混合方法是将其划分为多个列族,并动态生成用于过滤器数据的列。
转换后的架构为:
{
"client:eventid" => "24-1399386809805-629e9b5f-ff4a-4168-8664-6c8df8214aa7",
"client:eventidsuffix" => "629e9b5f-ff4a-4168-8664-6c8df8214aa7",
"client:hostedmachinename" => "192.168.182.1330",
"client:pageurl" => "http://blahblah:/5",
"client:createdtimestampinmillis" => 1399386809805,
"client:cutomerid" => 24,
"client:sessionid" => "648a011d-570e-48ef-bccc-84129c9fa400",
"search:querystring" => null,
"search:sortorder" => desc,
"search:pagenumber" => 3,
"search:totalhits" => 28,
"search:hitsshown" => 7,
"search:clickeddocid" => "41",
"search:favourite" => null,
"filters:searchfacettype_color_level_2" => "Blue",
"filters:searchfacettype_age_level_2" => "12-18 years"
}将创建以下三列系列:
- client :存储事件的客户和客户数据特定信息。
- search :与查询字符串和分页信息有关的搜索信息存储在此处。
- 过滤器:为了将来支持更多构面等,并更灵活地扫描数据,将基于构面名称/代码动态创建列名称,并将列值存储为构面过滤器值。
要创建hbase表,
...
TableName name = TableName.valueOf("searchclicks");
HTableDescriptor desc = new HTableDescriptor(name);
desc.addFamily(new HColumnDescriptor(HBaseJsonEventSerializer.COLUMFAMILY_CLIENT_BYTES));
desc.addFamily(new HColumnDescriptor(HBaseJsonEventSerializer.COLUMFAMILY_SEARCH_BYTES));
desc.addFamily(new HColumnDescriptor(HBaseJsonEventSerializer.COLUMFAMILY_FILTERS_BYTES));
try {
HBaseAdmin hBaseAdmin = new HBaseAdmin(miniHBaseCluster.getConf());
hBaseAdmin.createTable(desc);
hBaseAdmin.close();
} catch (IOException e) {
throw new RuntimeException(e);
}
...在创建表时已添加了相关列族,以支持新的数据结构。 通常,建议尽量减少列族的数量,并牢记如何根据使用情况来构造数据。 根据以上示例,我们将扫描场景保持为:
- 如果您想根据网站上的总访问量信息来检索客户或客户信息,请扫描客户家庭。
- 扫描搜索信息以查看最终客户正在寻找哪些免费文本搜索,而导航搜索却无法满足这些需求。 请参阅在哪个页面上单击了相关产品,您是否需要加强应用才能将产品推高。
- 扫描过滤器系列,以了解导航搜索如何为您工作。 是否为最终客户提供他们想要的产品。 查看更多点击哪些构面过滤器,您是否需要在订购中提高一点以便于客户轻松使用。
- 应避免在家庭之间进行扫描,而应使用行键设计来获得特定的客户信息。
行键设计信息
在我们的例子中,行键设计基于customerId-timestamp -randomuuid 。 由于所有列族的行键都相同,因此我们可以使用“前缀过滤器”对仅与特定客户相关的行进行过滤。
final String eventId = customerId + "-" + searchQueryInstruction.getCreatedTimeStampInMillis() + "-" + searchQueryInstruction.getEventIdSuffix();
...
byte[] rowKey = searchQueryInstruction.getEventId().getBytes(CHARSET_DEFAULT);
...
# 24-1399386809805-629e9b5f-ff4a-4168-8664-6c8df8214aa7这里的每个列族都有相同的行键,并且您可以使用前缀过滤器仅扫描特定客户的行。
水槽整合
HBaseSink用于将搜索事件数据直接存储到HBase。 检查详细信息FlumeHBaseSinkServiceImpl.java
...
channel = new MemoryChannel();
Map<String, String> channelParamters = new HashMap<>();
channelParamters.put("capacity", "100000");
channelParamters.put("transactionCapacity", "1000");
Context channelContext = new Context(channelParamters);
Configurables.configure(channel, channelContext);
channel.setName("HBaseSinkChannel-" + UUID.randomUUID());
sink = new HBaseSink();
sink.setName("HBaseSink-" + UUID.randomUUID());
Map<String, String> paramters = new HashMap<>();
paramters.put(HBaseSinkConfigurationConstants.CONFIG_TABLE, "searchclicks");
paramters.put(HBaseSinkConfigurationConstants.CONFIG_COLUMN_FAMILY, new String(HBaseJsonEventSerializer.COLUMFAMILY_CLIENT_BYTES));
paramters.put(HBaseSinkConfigurationConstants.CONFIG_BATCHSIZE, "1000");
paramters.put(HBaseSinkConfigurationConstants.CONFIG_SERIALIZER, HBaseJsonEventSerializer.class.getName());
Context sinkContext = new Context(paramters);
sink.configure(sinkContext);
sink.setChannel(channel);
sink.start();
channel.start();
...客户端列系列仅用于HBaseSink的验证。
HBaseJsonEventSerializer
创建自定义序列化器以存储JSON数据:
public class HBaseJsonEventSerializer implements HBaseEventSerializer {
public static final byte[] COLUMFAMILY_CLIENT_BYTES = "client".getBytes();
public static final byte[] COLUMFAMILY_SEARCH_BYTES = "search".getBytes();
public static final byte[] COLUMFAMILY_FILTERS_BYTES = "filters".getBytes();
...
byte[] rowKey = searchQueryInstruction.getEventId().getBytes(CHARSET_DEFAULT);
Put put = new Put(rowKey);
// Client Infor
put.add(COLUMFAMILY_CLIENT_BYTES, "eventid".getBytes(), searchQueryInstruction.getEventId().getBytes());
...
if (searchQueryInstruction.getFacetFilters() != null) {
for (SearchQueryInstruction.FacetFilter filter : searchQueryInstruction.getFacetFilters()) {
put.add(COLUMFAMILY_FILTERS_BYTES, filter.getCode().getBytes(),filter.getValue().getBytes());
}
}
...检查更多详细信息, HBaseJsonEventSerializer.java
事件主体从Json转换为Java bean,并进一步处理数据以在相关的列系列中进行序列化。
查询原始单元格数据
要查询原始单元格数据:
...
Scan scan = new Scan();
scan.addFamily(HBaseJsonEventSerializer.COLUMFAMILY_CLIENT_BYTES);
scan.addFamily(HBaseJsonEventSerializer.COLUMFAMILY_SEARCH_BYTES);
scan.addFamily(HBaseJsonEventSerializer.COLUMFAMILY_FILTERS_BYTES);
List<String> rows = hbaseTemplate.find("searchclicks", scan,
new RowMapper<String>() {
@Override
public String mapRow(Result result, int rowNum) throws Exception {
return Arrays.toString(result.rawCells());
}
});
for (String row : rows) {
LOG.debug("searchclicks table content, Table returned row: {}", row);
}检查HBaseServiceImpl.java以获得详细信息。
数据以以下格式存储在hbase中:
searchclicks table content, Table returned row: [84-1404832902498-7965306a-d256-4ddb-b7a8-fd19cdb99923/client:createdtimestampinmillis/1404832918166/Put/vlen=13/mvcc=0, 84-1404832902498-7965306a-d256-4ddb-b7a8-fd19cdb99923/client:customerid/1404832918166/Put/vlen=2/mvcc=0, 84-1404832902498-7965306a-d256-4ddb-b7a8-fd19cdb99923/client:eventid/1404832918166/Put/vlen=53/mvcc=0, 84-1404832902498-7965306a-d256-4ddb-b7a8-fd19cdb99923/client:hostedmachinename/1404832918166/Put/vlen=16/mvcc=0, 84-1404832902498-7965306a-d256-4ddb-b7a8-fd19cdb99923/client:pageurl/1404832918166/Put/vlen=19/mvcc=0, 84-1404832902498-7965306a-d256-4ddb-b7a8-fd19cdb99923/client:sessionid/1404832918166/Put/vlen=36/mvcc=0, 84-1404832902498-7965306a-d256-4ddb-b7a8-fd19cdb99923/filters:searchfacettype_product_type_level_2/1404832918166/Put/vlen=7/mvcc=0, 84-1404832902498-7965306a-d256-4ddb-b7a8-fd19cdb99923/search:hitsshown/1404832918166/Put/vlen=2/mvcc=0, 84-1404832902498-7965306a-d256-4ddb-b7a8-fd19cdb99923/search:pagenumber/1404832918166/Put/vlen=1/mvcc=0, 84-1404832902498-7965306a-d256-4ddb-b7a8-fd19cdb99923/search:querystring/1404832918166/Put/vlen=13/mvcc=0, 84-1404832902498-7965306a-d256-4ddb-b7a8-fd19cdb99923/search:sortorder/1404832918166/Put/vlen=3/mvcc=0, 84-1404832902498-7965306a-d256-4ddb-b7a8-fd19cdb99923/search:totalhits/1404832918166/Put/vlen=2/mvcc=0]查询过去一个小时的前10个搜索查询字符串
要仅查询搜索字符串,我们只需要搜索列族。 要在时间范围内进行扫描,我们可以使用client列系列创建的timestampinmillis列,但这将是扩展扫描。
...
Scan scan = new Scan();
scan.addColumn(HBaseJsonEventSerializer.COLUMFAMILY_CLIENT_BYTES, Bytes.toBytes("createdtimestampinmillis"));
scan.addColumn(HBaseJsonEventSerializer.COLUMFAMILY_SEARCH_BYTES, Bytes.toBytes("querystring"));
List<String> rows = hbaseTemplate.find("searchclicks", scan,
new RowMapper<String>() {
@Override
public String mapRow(Result result, int rowNum) throws Exception {
String createdtimestampinmillis = new String(result.getValue(HBaseJsonEventSerializer.COLUMFAMILY_CLIENT_BYTES, Bytes.toBytes("createdtimestampinmillis")));
byte[] value = result.getValue(HBaseJsonEventSerializer.COLUMFAMILY_SEARCH_BYTES, Bytes.toBytes("querystring"));
String querystring = null;
if (value != null) {
querystring = new String(value);
}
if (new DateTime(Long.valueOf(createdtimestampinmillis)).plusHours(1).compareTo(new DateTime()) == 1 && querystring != null) {
return querystring;
}
return null;
}
});
...
//sort the keys, based on counts collection of the query strings.
List<String> sortedKeys = Ordering.natural().onResultOf(Functions.forMap(counts)).immutableSortedCopy(counts.keySet());
...查询过去一个小时的前10个搜索方面过滤器
基于动态列创建,您可以扫描数据以返回点击次数最高的构面过滤器。
动态列将基于您的方面代码,这些代码可以是以下任意一种:
#searchfacettype_age_level_1
#searchfacettype_color_level_2
#searchfacettype_brand_level_2
#searchfacettype_age_level_2
for (String facetField : SearchFacetName.categoryFacetFields) {
scan.addColumn(HBaseJsonEventSerializer.COLUMFAMILY_FILTERS_BYTES, Bytes.toBytes(facetField));
}检索到:
...
hbaseTemplate.find("searchclicks", scan, new RowMapper<String>() {
@Override
public String mapRow(Result result, int rowNum) throws Exception {
for (String facetField : SearchFacetName.categoryFacetFields) {
byte[] value = result.getValue(HBaseJsonEventSerializer.COLUMFAMILY_FILTERS_BYTES, Bytes.toBytes(facetField));
if (value != null) {
String facetValue = new String(value);
List<String> list = columnData.get(facetField);
if (list == null) {
list = new ArrayList<>();
list.add(facetValue);
columnData.put(facetField, list);
} else {
list.add(facetValue);
}
}
}
return null;
}
});
...您将获得所有构面的完整列表,可以进一步处理数据以计算顶面并对其进行排序。 有关完整的详细信息,请检查HBaseServiceImpl.findTopTenSearchFiltersForLastAnHour
获取客户的最近搜索查询字符串
如果需要检查客户当前正在寻找什么,我们可以在“客户”和“搜索”之间的两个列族之间创建扫描。 或者,另一种方式是设计行键,以便为您提供相关信息。 在我们的例子中,行键设计基于CustomerId_timestamp _randomuuid。 由于所有列族的行键都相同,因此我们可以使用“前缀过滤器”对仅与特定客户相关的行进行过滤。
final String eventId = customerId + "-" + searchQueryInstruction.getCreatedTimeStampInMillis() + "-" + searchQueryInstruction.getEventIdSuffix();
...
byte[] rowKey = searchQueryInstruction.getEventId().getBytes(CHARSET_DEFAULT);
...
# 84-1404832902498-7965306a-d256-4ddb-b7a8-fd19cdb99923要扫描特定客户的数据,
...
Scan scan = new Scan();
scan.addColumn(HBaseJsonEventSerializer.COLUMFAMILY_SEARCH_BYTES, Bytes.toBytes("customerid"));
Filter filter = new PrefixFilter(Bytes.toBytes(customerId + "-"));
scan.setFilter(filter);
...有关详细信息,请检查HBaseServiceImpl.getAllSearchQueryStringsByCustomerInLastOneMonth
希望这可以帮助您入门HBase模式设计和处理数据。















 1840
1840











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









