





搜索引擎都是关于查找字符串的。 用户输入一个查询词,然后从反向索引中检索它。 有时,用户正在寻找的值只是索引中值的子字符串,并且用户可能也对这些匹配感兴趣。 对于德语这样的包含复合词(例如Semmelknödel)的语言,这尤其重要,其中Knödel表示饺子,而Semmel专门介绍这种词。
通配符
为了演示方法,我使用了非常简单的模式。 文档由一个文本字段和一个ID组成。 在Github上也可以进行配置和单元测试。
<fields>
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" />
<field name="text" type="text_general" indexed="true" stored="false"/>
</fields>
<uniqueKey>id</uniqueKey>
<types>
<fieldType name="string" class="solr.StrField" sortMissingLast="true" />
<fieldType name="text_general" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
</types>在进行前缀或后缀匹配时非常流行的一种方法是在查询时使用通配符。 这可以通过编程方式完成,但是您需要注意,然后正确转义任何用户输入。 假设您在索引中包含术语饺子 ,并且用户输入了术语dump 。 如果要确保查询词与索引中的文档匹配,您可以在应用程序代码中向用户查询添加通配符,以便将生成的查询转储为* 。
通常,在进行此类过多操作时,您应格外小心:如果用户实际上正在查找包含dump单词的文档,那么她可能对包含dumpling的文档不感兴趣。 您需要自己决定是只希望对用户感兴趣的匹配项(精确)还是向用户显示尽可能多的可能匹配项(调用)。 这在很大程度上取决于您的应用程序的用例。
您可以通过提高与您的学期的完全匹配来增加用户体验。 您需要创建一个更复杂的查询,但是这样,包含完全匹配项的文档将获得更高的分数:
dump^2 OR dump* 在创建这样的查询时,您还应注意用户不能添加会使查询无效的字词。 escapeQueryChars类的SolrJ方法escapeQueryChars可用于转义用户输入。
如果现在考虑后缀匹配,则查询可能会变得非常复杂,并且在客户端创建这样的查询并不适合每个人。 根据您的应用程序,另一种方法可能是更好的解决方案:您可以在索引期间创建另一个包含NGram的字段。
前缀与NGrams匹配
NGrams是索引术语的子字符串,您可以将其放在其他字段中。 这些子字符串可用于查找,因此不需要任何通配符。 使用(e)dismax处理程序,您可以在字段上自动设置用于完全匹配的提升,从而获得与上述相同的行为。
对于前缀匹配,我们可以使用为其他字段配置的EdgeNGramFilter :
...
<field name="text_prefix" type="text_prefix" indexed="true" stored="false"/>
...
<copyField source="text" dest="text_prefix"/>
...
<fieldType name="text_prefix" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.LowerCaseTokenizerFactory"/>
<filter class="solr.EdgeNGramFilterFactory" minGramSize="3" maxGramSize="15" side="front"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.LowerCaseTokenizerFactory"/>
</analyzer>
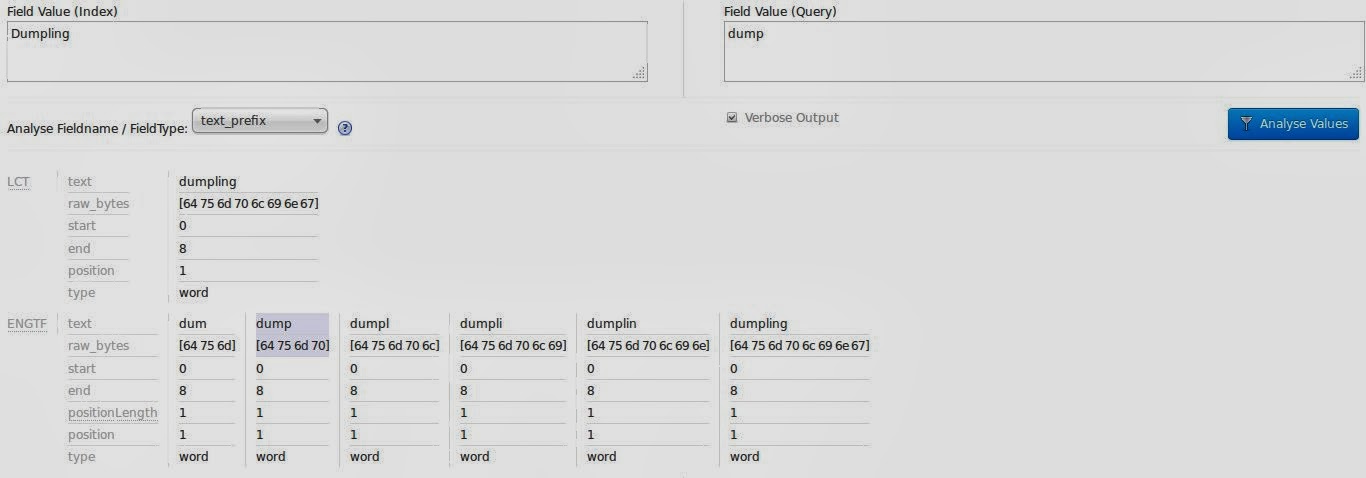
</fieldType> 在索引期间,文本字段值将复制到text_prefix字段,并使用EdgeNGramFilter进行分析。 从字符串的开头开始,将创建3到15之间任何长度的克。 当为术语饺子建立索引时,它将是:
- 哑巴
- 倾倒
- 垃圾堆
- 杜普利
- 杜普林
- 饺子
在查询期间,该词不会再次拆分,因此可以使用与子字符串完全匹配的词。 像往常一样,Solr管理员后端的分析视图可以帮助您查看实际的分析过程。
使用dismax处理程序,您现在可以按原样传递用户查询,并通过添加参数qf=text^2,text_prefix来建议它在您的字段中进行搜索。
后缀匹配
对于具有复合词的语言,通常也需要进行后缀匹配。 如果用户查询术语Knödel (水饺),则包含术语Semmelknödel的文档也应匹配。
使用Solr版本高达4.3,这没有问题。 您可以使用EdgeNGramFilterFactory从字符串的后面开始创建克。
...
<field name="text_suffix" type="text_suffix" indexed="true" stored="false"/>
...
<copyField source="text" dest="text_suffix"/>
...
<fieldType name="text_suffix" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.EdgeNGramFilterFactory" minGramSize="3" maxGramSize="15" side="back"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.KeywordTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
...这将创建索引术语的后缀,其中也包含术语knödel,因此我们的查询有效。
但是,使用较新版本的Solr时,在建立索引期间会遇到问题:
java.lang.IllegalArgumentException: Side.BACK is not supported anymore as of Lucene 4.4, use ReverseStringFilter up-front and afterward
at org.apache.lucene.analysis.ngram.EdgeNGramTokenFilter.(EdgeNGramTokenFilter.java:114)
at org.apache.lucene.analysis.ngram.EdgeNGramTokenFilter.(EdgeNGramTokenFilter.java:149)
at org.apache.lucene.analysis.ngram.EdgeNGramFilterFactory.create(EdgeNGramFilterFactory.java:52)
at org.apache.lucene.analysis.ngram.EdgeNGramFilterFactory.create(EdgeNGramFilterFactory.java:34)您不能再将EdgeNGramFilterFactory用于后缀ngram。 但是幸运的是,堆栈跟踪还建议我们如何解决该问题。 我们必须将其与ReverseStringFilter结合使用:
<fieldType name="text_suffix" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.LowerCaseTokenizerFactory"/>
<filter class="solr.ReverseStringFilterFactory"/>
<filter class="solr.EdgeNGramFilterFactory" minGramSize="3" maxGramSize="15" side="front"/>
<filter class="solr.ReverseStringFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.LowerCaseTokenizerFactory"/>
</analyzer>
</fieldType>现在将产生与以前相同的结果。
结论
是否要通过添加通配符来处理查询,或者是否应该使用NGram方法,在很大程度上取决于您的用例,也取决于您的口味。 我个人大部分时间都在使用NGrams,因为磁盘空间通常与我正在从事的项目无关。 在Lucene 4中,通配符搜索变得更快了,所以我怀疑那里是否还有真正的好处。 不过,我倾向于在索引期间进行尽可能多的处理。
翻译自: https://www.javacodegeeks.com/2014/05/prefix-and-suffix-matches-in-solr.html















 5902
5902

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









