





这篇文章涵盖了使用Apache flume收集客户产品搜索点击并使用hadoop和elasticsearch接收器存储信息。 数据可能包含不同的产品搜索事件,例如基于不同方面的过滤,排序信息,分页信息,以及进一步查看的产品以及某些被客户标记为喜欢的产品。 在以后的文章中,我们将进一步分析数据,以使用相同的信息进行显示和分析。
产品搜索功能
任何电子商务平台都可以为客户提供不同的产品,而搜索功能是其基础之一。 允许用户使用不同的构面/过滤器进行引导导航,或使用自由文本搜索内容,这与任何现有搜索功能无关紧要。
SearchQueryInstruction
考虑类似的情况,客户可以搜索产品,并允许我们使用以下信息来捕获产品搜索行为,
public class SearchQueryInstruction implements Serializable {
@JsonIgnore
private final String _eventIdSuffix;
private String eventId;
private String hostedMachineName;
private String pageUrl;
private Long customerId;
private String sessionId;
private String queryString;
private String sortOrder;
private Long pageNumber;
private Long totalHits;
private Long hitsShown;
private final Long createdTimeStampInMillis;
private String clickedDocId;
private Boolean favourite;
@JsonIgnore
private Map<String, Set<String>> filters;
@JsonProperty(value = "filters")
private List<FacetFilter> _filters;
public SearchQueryInstruction() {
_eventIdSuffix = UUID.randomUUID().toString();
createdTimeStampInMillis = new Date().getTime();
}
...
...
private static class FacetFilter implements Serializable {
private String code;
private String value;
public FacetFilter(String code, String value) {
this.code = code;
this.value = value;
}
...
...
}
}有关更多源信息,请访问SearchQueryInstruction 。 数据以JSON格式序列化,以便能够直接与ElasticSearch结合使用以进一步显示。
示例数据,基于用户点击的点击信息的外观。 数据先转换为json格式,然后再发送给嵌入式水槽代理。
{"eventid":"629e9b5f-ff4a-4168-8664-6c8df8214aa7-1399386809805-24","hostedmachinename":"192.168.182.1330","pageurl":"http://jaibigdata.com/5","customerid":24,"sessionid":"648a011d-570e-48ef-bccc-84129c9fa400","querystring":null,"sortorder":"desc","pagenumber":3,"totalhits":28,"hitsshown":7,"createdtimestampinmillis":1399386809805,"clickeddocid":"41","favourite":null,"eventidsuffix":"629e9b5f-ff4a-4168-8664-6c8df8214aa7","filters":[{"code":"searchfacettype_color_level_2","value":"Blue"},{"code":"searchfacettype_age_level_2","value":"12-18 years"}]}
{"eventid":"648b5cf7-7ca9-4664-915d-23b0d45facc4-1399386809782-298","hostedmachinename":"192.168.182.1333","pageurl":"http://jaibigdata.com/4","customerid":298,"sessionid":"7bf042ea-526a-4633-84cd-55e0984ea2cb","querystring":"queryString48","sortorder":"desc","pagenumber":0,"totalhits":29,"hitsshown":19,"createdtimestampinmillis":1399386809782,"clickeddocid":"9","favourite":null,"eventidsuffix":"648b5cf7-7ca9-4664-915d-23b0d45facc4","filters":[{"code":"searchfacettype_color_level_2","value":"Green"}]}
{"eventid":"74bb7cfe-5f8c-4996-9700-0c387249a134-1399386809799-440","hostedmachinename":"192.168.182.1330","pageurl":"http://jaibigdata.com/1","customerid":440,"sessionid":"940c9a0f-a9b2-4f1d-b114-511ac11bf2bb","querystring":"queryString16","sortorder":"asc","pagenumber":3,"totalhits":5,"hitsshown":32,"createdtimestampinmillis":1399386809799,"clickeddocid":null,"favourite":null,"eventidsuffix":"74bb7cfe-5f8c-4996-9700-0c387249a134","filters":[{"code":"searchfacettype_brand_level_2","value":"Apple"}]}
{"eventid":"9da05913-84b1-4a74-89ed-5b6ec6389cce-1399386809828-143","hostedmachinename":"192.168.182.1332","pageurl":"http://jaibigdata.com/1","customerid":143,"sessionid":"08a4a36f-2535-4b0e-b86a-cf180202829b","querystring":null,"sortorder":"desc","pagenumber":0,"totalhits":21,"hitsshown":34,"createdtimestampinmillis":1399386809828,"clickeddocid":"38","favourite":true,"eventidsuffix":"9da05913-84b1-4a74-89ed-5b6ec6389cce","filters":[{"code":"searchfacettype_color_level_2","value":"Blue"},{"code":"product_price_range","value":"10.0 - 20.0"}]}阿帕奇水槽
Apache Flume用于收集和聚合数据。 此处,嵌入式Flume代理用于捕获搜索查询指令事件。 根据实际使用情况,
- 您可以使用嵌入式代理来收集数据
- 或通过rest api将数据从页面推送到专用于事件收集的后端api服务
- 或者,您可以使用应用程序日志记录功能来记录所有搜索事件,并在日志文件的末尾收集数据
考虑一个取决于应用程序的场景,多个Web /应用程序服务器将事件数据发送到收集器水槽代理。 如下图所示,搜索点击事件是从多个Web /应用服务器和一个收集器/合并器代理收集的,以从所有代理收集数据。 数据基于选择器使用多路复用策略进一步划分,以存储在Hadoop HDFS中,并且还将相关数据定向到ElasticSearch。 最近浏览过的商品。
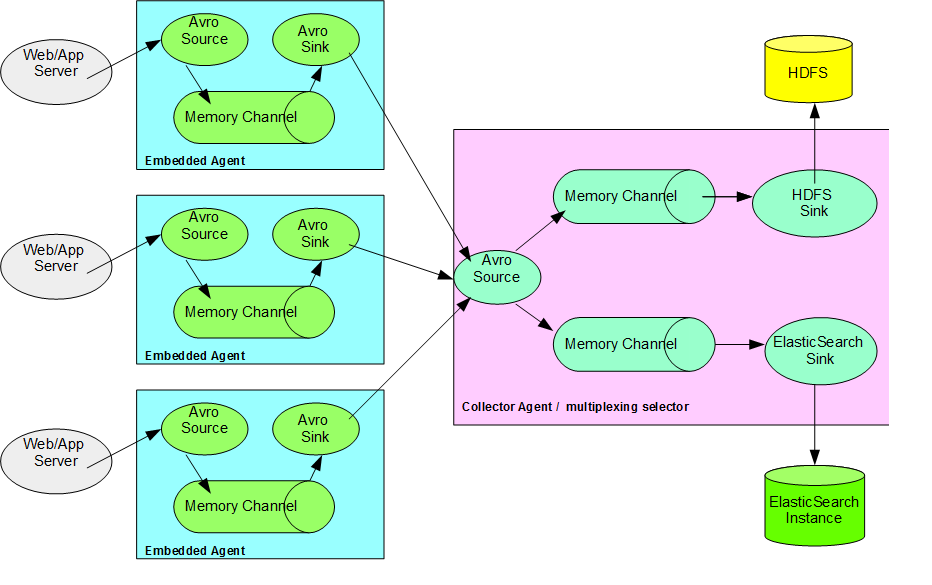
嵌入式Flume代理
嵌入式Flume Agent允许我们在应用程序本身中包含Flume代理,并允许我们收集数据并进一步发送给收集器代理。
private static EmbeddedAgent agent;
private void createAgent() {
final Map<String, String> properties = new HashMap<String, String>();
properties.put("channel.type", "memory");
properties.put("channel.capacity", "100000");
properties.put("channel.transactionCapacity", "1000");
properties.put("sinks", "sink1");
properties.put("sink1.type", "avro");
properties.put("sink1.hostname", "localhost");
properties.put("sink1.port", "44444");
properties.put("processor.type", "default");
try {
agent = new EmbeddedAgent("searchqueryagent");
agent.configure(properties);
agent.start();
} catch (final Exception ex) {
LOG.error("Error creating agent!", ex);
}
}存储搜索事件数据
Flume提供了多个接收器选项来存储数据以供将来分析。 如图所示,我们将采用将数据存储在Apache Hadoop和ElasticSearch中的方案,以实现最近查看的项目功能。
Hadoop接收器
允许将数据永久存储到HDFS,以便以后进行分析以进行分析。
根据传入的事件数据,假设我们要每小时存储一次。 “ / searchevents / 2014/05/15/16”目录将存储16小时内的所有传入事件。
private HDFSEventSink sink;
sink = new HDFSEventSink();
sink.setName("HDFSEventSink-" + UUID.randomUUID());
channel = new MemoryChannel();
Map<String, String> channelParamters = new HashMap<>();
channelParamters.put("capacity", "100000");
channelParamters.put("transactionCapacity", "1000");
Context channelContext = new Context(channelParamters);
Configurables.configure(channel, channelContext);
channel.setName("HDFSEventSinkChannel-" + UUID.randomUUID());
Map<String, String> paramters = new HashMap<>();
paramters.put("hdfs.type", "hdfs");
String hdfsBasePath = hadoopClusterService.getHDFSUri()
+ "/searchevents";
paramters.put("hdfs.path", hdfsBasePath + "/%Y/%m/%d/%H");
paramters.put("hdfs.filePrefix", "searchevents");
paramters.put("hdfs.fileType", "DataStream");
paramters.put("hdfs.rollInterval", "0");
paramters.put("hdfs.rollSize", "0");
paramters.put("hdfs.idleTimeout", "1");
paramters.put("hdfs.rollCount", "0");
paramters.put("hdfs.batchSize", "1000");
paramters.put("hdfs.useLocalTimeStamp", "true");
Context sinkContext = new Context(paramters);
sink.configure(sinkContext);
sink.setChannel(channel);
sink.start();
channel.start();检查FlumeHDFSSinkServiceImpl.java以获取有关hdfs接收器的详细启动/停止信息。
下面的示例数据存储在hadoop中,
Check:hdfs://localhost.localdomain:54321/searchevents/2014/05/06/16/searchevents.1399386809864
body is:{"eventid":"e8470a00-c869-4a90-89f2-f550522f8f52-1399386809212-72","hostedmachinename":"192.168.182.1334","pageurl":"http://jaibigdata.com/0","customerid":72,"sessionid":"7871a55c-a950-4394-bf5f-d2179a553575","querystring":null,"sortorder":"desc","pagenumber":0,"totalhits":8,"hitsshown":44,"createdtimestampinmillis":1399386809212,"clickeddocid":"23","favourite":null,"eventidsuffix":"e8470a00-c869-4a90-89f2-f550522f8f52","filters":[{"code":"searchfacettype_brand_level_2","value":"Apple"},{"code":"searchfacettype_color_level_2","value":"Blue"}]}
body is:{"eventid":"2a4c1e1b-d2c9-4fe2-b38d-9b7d32feb4e0-1399386809743-61","hostedmachinename":"192.168.182.1330","pageurl":"http://jaibigdata.com/0","customerid":61,"sessionid":"78286f6d-cc1e-489c-85ce-a7de8419d628","querystring":"queryString59","sortorder":"asc","pagenumber":3,"totalhits":32,"hitsshown":9,"createdtimestampinmillis":1399386809743,"clickeddocid":null,"favourite":null,"eventidsuffix":"2a4c1e1b-d2c9-4fe2-b38d-9b7d32feb4e0","filters":[{"code":"searchfacettype_age_level_2","value":"0-12 years"}]}ElasticSearch接收器
出于查看目的,向最终用户显示最近查看的项目。 ElasticSearch Sink允许自动创建每日最近查看的项目。 该功能可用于显示客户最近查看的项目。
假设您已经有ES实例在localhost / 9310上运行。
private ElasticSearchSink sink;
sink = new ElasticSearchSink();
sink.setName("ElasticSearchSink-" + UUID.randomUUID());
channel = new MemoryChannel();
Map<String, String> channelParamters = new HashMap<>();
channelParamters.put("capacity", "100000");
channelParamters.put("transactionCapacity", "1000");
Context channelContext = new Context(channelParamters);
Configurables.configure(channel, channelContext);
channel.setName("ElasticSearchSinkChannel-" + UUID.randomUUID());
Map<String, String> paramters = new HashMap<>();
paramters.put(ElasticSearchSinkConstants.HOSTNAMES, "127.0.0.1:9310");
String indexNamePrefix = "recentlyviewed";
paramters.put(ElasticSearchSinkConstants.INDEX_NAME, indexNamePrefix);
paramters.put(ElasticSearchSinkConstants.INDEX_TYPE, "clickevent");
paramters.put(ElasticSearchSinkConstants.CLUSTER_NAME,
"jai-testclusterName");
paramters.put(ElasticSearchSinkConstants.BATCH_SIZE, "10");
paramters.put(ElasticSearchSinkConstants.SERIALIZER,
ElasticSearchJsonBodyEventSerializer.class.getName());
Context sinkContext = new Context(paramters);
sink.configure(sinkContext);
sink.setChannel(channel);
sink.start();
channel.start();检查FlumeESSinkServiceImpl.java以获得启动/停止ElasticSearch接收器的详细信息。
elasticsearch中的样本数据存储为
{timestamp=1399386809743, body={pageurl=http://jaibigdata.com/0, querystring=queryString59, pagenumber=3, hitsshown=9, hostedmachinename=192.168.182.1330, createdtimestampinmillis=1399386809743, sessionid=78286f6d-cc1e-489c-85ce-a7de8419d628, eventid=2a4c1e1b-d2c9-4fe2-b38d-9b7d32feb4e0-1399386809743-61, totalhits=32, clickeddocid=null, customerid=61, sortorder=asc, favourite=null, eventidsuffix=2a4c1e1b-d2c9-4fe2-b38d-9b7d32feb4e0, filters=[{value=0-12 years, code=searchfacettype_age_level_2}]}, eventId=2a4c1e1b-d2c9-4fe2-b38d-9b7d32feb4e0}
{timestamp=1399386809757, body={pageurl=http://jaibigdata.com/1, querystring=null, pagenumber=1, hitsshown=34, hostedmachinename=192.168.182.1330, createdtimestampinmillis=1399386809757, sessionid=e6a3fd51-fe07-4e21-8574-ce5ab8bfbd68, eventid=fe5279b7-0bce-4e2b-ad15-8b94107aa792-1399386809757-134, totalhits=9, clickeddocid=22, customerid=134, sortorder=desc, favourite=null, eventidsuffix=fe5279b7-0bce-4e2b-ad15-8b94107aa792, filters=[{value=Blue, code=searchfacettype_color_level_2}]}, State=VIEWED, eventId=fe5279b7-0bce-4e2b-ad15-8b94107aa792}
{timestamp=1399386809765, body={pageurl=http://jaibigdata.com/0, querystring=null, pagenumber=4, hitsshown=2, hostedmachinename=192.168.182.1331, createdtimestampinmillis=1399386809765, sessionid=29864de8-5708-40ab-a78b-4fae55698b01, eventid=886e9a28-4c8c-4e8c-a866-e86f685ecc54-1399386809765-317, totalhits=2, clickeddocid=null, customerid=317, sortorder=asc, favourite=null, eventidsuffix=886e9a28-4c8c-4e8c-a866-e86f685ecc54, filters=[{value=0-12 years, code=searchfacettype_age_level_2}, {value=0.0 - 10.0, code=product_price_range}]}, eventId=886e9a28-4c8c-4e8c-a866-e86f685ecc54}ElasticSearchJsonBodyEventSerializer
控制如何在ElasticSearch中建立数据索引。 根据您的策略更新事件Seaalalizer,以查看应如何为数据建立索引。
public class ElasticSearchJsonBodyEventSerializer implements ElasticSearchEventSerializer {
@Override
public BytesStream getContentBuilder(final Event event) throws IOException {
final XContentBuilder builder = jsonBuilder().startObject();
appendBody(builder, event);
appendHeaders(builder, event);
return builder;
}
...
...
}检查ElasticSearchJsonBodyEventSerializer.java以配置序列化器以索引数据。
让我们以Java为例创建Flume源,以在测试用例中处理上述SearchQueryInstruction并存储数据。
带通道选择器的Avro Source
为了进行测试,让我们创建Avro源,以基于水槽多路复用功能将数据重定向到相关的接收器。
//Avro source to start at below port and process incoming data.
private AvroSource avroSource;
final Map<String, String> properties = new HashMap<String, String>();
properties.put("type", "avro");
properties.put("bind", "localhost");
properties.put("port", "44444");
avroSource = new AvroSource();
avroSource.setName("AvroSource-" + UUID.randomUUID());
Context sourceContext = new Context(properties);
avroSource.configure(sourceContext);
ChannelSelector selector = new MultiplexingChannelSelector();
//Channels from above services
Channel ESChannel = flumeESSinkService.getChannel();
Channel HDFSChannel = flumeHDFSSinkService.getChannel();
List<Channel> channels = new ArrayList<>();
channels.add(ESChannel);
channels.add(HDFSChannel);
selector.setChannels(channels);
final Map<String, String> selectorProperties = new HashMap<String, String>();
selectorProperties.put("type", "multiplexing");
selectorProperties.put("header", "State");
selectorProperties.put("mapping.VIEWED", HDFSChannel.getName() + " "
+ ESChannel.getName());
selectorProperties.put("mapping.FAVOURITE", HDFSChannel.getName() + " "
+ ESChannel.getName());
selectorProperties.put("default", HDFSChannel.getName());
Context selectorContext = new Context(selectorProperties);
selector.configure(selectorContext);
ChannelProcessor cp = new ChannelProcessor(selector);
avroSource.setChannelProcessor(cp);
avroSource.start();检查FlumeAgentServiceImpl.java,将数据直接存储到上面配置的接收器,甚至将所有数据记录到日志文件中。
独立Flume / Hadoop / ElasticSearch环境
该应用程序可用于生成SearchQueryInstruction数据,并且您可以使用自己的独立环境进一步处理数据。 如果您已经在运行Flume / Hadoop / ElasticSearch环境,请使用以下设置进一步处理数据。
如果您已经在运行Flume实例,也可以使用以下配置(flume.conf),
# Name the components on this agent
searcheventscollectoragent.sources = eventsavrosource
searcheventscollectoragent.sinks = hdfssink essink
searcheventscollectoragent.channels = hdfschannel eschannel
# Bind the source and sink to the channel
searcheventscollectoragent.sources.eventsavrosource.channels = hdfschannel eschannel
searcheventscollectoragent.sinks.hdfssink.channel = hdfschannel
searcheventscollectoragent.sinks.essink.channel = eschannel
#Avro source. This is where data will send data to.
searcheventscollectoragent.sources.eventsavrosource.type = avro
searcheventscollectoragent.sources.eventsavrosource.bind = 0.0.0.0
searcheventscollectoragent.sources.eventsavrosource.port = 44444
searcheventscollectoragent.sources.eventsavrosource.selector.type = multiplexing
searcheventscollectoragent.sources.eventsavrosource.selector.header = State
searcheventscollectoragent.sources.eventsavrosource.selector.mapping.VIEWED = hdfschannel eschannel
searcheventscollectoragent.sources.eventsavrosource.selector.mapping.default = hdfschannel
# Use a channel which buffers events in memory. This will keep all incoming stuff in memory. You may change this to file etc. in case of too much data coming and memory an issue.
searcheventscollectoragent.channels.hdfschannel.type = memory
searcheventscollectoragent.channels.hdfschannel.capacity = 100000
searcheventscollectoragent.channels.hdfschannel.transactionCapacity = 1000
searcheventscollectoragent.channels.eschannel.type = memory
searcheventscollectoragent.channels.eschannel.capacity = 100000
searcheventscollectoragent.channels.eschannel.transactionCapacity = 1000
#HDFS sink. Store events directly to hadoop file system.
searcheventscollectoragent.sinks.hdfssink.type = hdfs
searcheventscollectoragent.sinks.hdfssink.hdfs.path = hdfs://localhost.localdomain:54321/searchevents/%Y/%m/%d/%H
searcheventscollectoragent.sinks.hdfssink.hdfs.filePrefix = searchevents
searcheventscollectoragent.sinks.hdfssink.hdfs.fileType = DataStream
searcheventscollectoragent.sinks.hdfssink.hdfs.rollInterval = 0
searcheventscollectoragent.sinks.hdfssink.hdfs.rollSize = 134217728
searcheventscollectoragent.sinks.hdfssink.hdfs.idleTimeout = 60
searcheventscollectoragent.sinks.hdfssink.hdfs.rollCount = 0
searcheventscollectoragent.sinks.hdfssink.hdfs.batchSize = 10
searcheventscollectoragent.sinks.hdfssink.hdfs.useLocalTimeStamp = true
#Elastic search
searcheventscollectoragent.sinks.essink.type = elasticsearch
searcheventscollectoragent.sinks.essink.hostNames = 127.0.0.1:9310
searcheventscollectoragent.sinks.essink.indexName = recentlyviewed
searcheventscollectoragent.sinks.essink.indexType = clickevent
searcheventscollectoragent.sinks.essink.clusterName = jai-testclusterName
searcheventscollectoragent.sinks.essink.batchSize = 10
searcheventscollectoragent.sinks.essink.ttl = 5
searcheventscollectoragent.sinks.essink.serializer = org.jai.flume.sinks.elasticsearch.serializer.ElasticSearchJsonBodyEventSerializer要测试应用程序搜索查询指令在现有hadoop实例上的行为,请分别设置hadoop和elasticsearch实例。 该应用程序使用Cloudera hadoop distribution 5.0进行测试。
在后面的文章中,我们将介绍进一步分析生成的数据,
- 使用Hive可以查询数据,以查询最热门的客户和产品浏览的次数。
- 使用ElasticSearch Hadoop为客户热门查询和产品视图数据编制索引
- 使用Pig来计算唯一客户总数
- 使用Oozie计划针对配置单元分区进行协调的作业,并将作业捆绑以将数据索引到ElasticSearch。















 1338
1338











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









