





 系统响应时间出现随机尖峰,发现与每小时一次的Full GC有关。问题源于RMI设置,通过调整`sun.rmi.dgc.server.gcInterval`参数解决了这一问题。旧版JDK中的RMI可能每分钟触发一次Full GC,影响性能。
系统响应时间出现随机尖峰,发现与每小时一次的Full GC有关。问题源于RMI设置,通过调整`sun.rmi.dgc.server.gcInterval`参数解决了这一问题。旧版JDK中的RMI可能每分钟触发一次Full GC,影响性能。
在我职业生涯中进行的所有故障排除练习中,我感到随着时间的推移,我所追寻的错误在不断发展,变得越来越卑鄙和丑陋。 也许仅仅是我的年龄开始了。这个特别的Heisenbug –看起来像这篇帖子一样,再次让我清醒了很多,而不是我想要的。
与其他特别令人讨厌的错误一样,我现在遇到的那个错误的症状是“有时系统运行缓慢”。 太好了,我已经感觉到脊椎发麻。 当我发现系统在生产中设置了简单的监视解决方案来监视系统时,情况就好了一些。 从本质上讲,它只是Pingdom的功能 ,每秒测量一次响应时间,但是延迟图立即引起了我的注意。
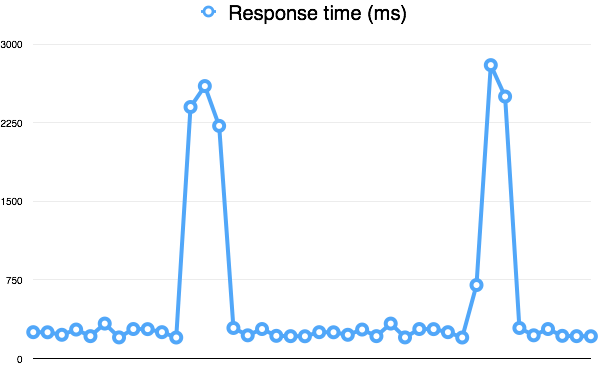
在图中绘制的响应时间似乎是随机的尖峰–每次在蓝月亮中,响应开始花费的时间将近10倍。 不久之后,一切又恢复了正常。
最初的犯罪嫌疑人–看不见定期的cron工作或昂贵的报告流程。 存储监视也没有暴露任何特别丑陋的查询击中数据库。 但是在打电话之前,我在应用程序配置中添加了更多日志记录选项,重新启动了整个程序,并迷惑了自己的行为。
第二天早上,我还有其他事情要看,GC日志等。 十分钟之内,我发现自己盯着下面的东西:
11.408: [Full GC [PSYoungGen: 192K->0K(48640K)] [ParOldGen: 16324K->14750K(114688K)] 16516K->14750K(163328K) [PSPermGen: 31995K->31637K(64000K)], 0.1543430 secs] [Times: user=0.58 sys=0.00, real=0.16 secs]
...
3613.362: [Full GC [PSYoungGen: 256K->0K(47104K)] [ParOldGen: 15142K->13497K(114688K)] 15398K->13497K(161792K) [PSPermGen: 32429K->32369K(72192K)], 0.1129070 secs] [Times: user=0.51 sys=0.00, real=0.11 secs]
...
7215.278: [Full GC [PSYoungGen: 224K->0K(44544K)] [ParOldGen: 13665K->13439K(114688K)] 13889K->13439K(159232K) [PSPermGen: 32426K->32423K(70144K)], 0.0881450 secs] [Times: user=0.44 sys=0.00, real=0.09 secs]
...现在,我可以将看似随机的性能下降与每次经过大约3600秒时运行的Full GC关联起来。 将VisualVM附加到JVM令我感到困惑–没有证据表明高内存使用率会导致整个垃圾收集器运行。 与开发人员核对后,我确定他们没有通过cron作业运行显式GC。 所以我站在那儿,对GC的常规性感到困惑。
工程师对问题感到困惑时会怎么做? 他谷歌 。 就在那里,凝视着我的脸。 与担心每小时进行一次完整GC的人员进行的逐页讨论,没有任何明显的原因。
罪魁祸首-RMI。 显然,当您的应用程序通过RMI公开其服务或通过RMI使用任何服务时,您必然会有一个额外的垃圾回收周期。 正如RMI文档所述 :
“当需要确保不导出不可达的远程对象并及时收集垃圾时,此属性的值表示Java RMI运行时将允许在本地堆的垃圾回收之间的最大间隔(以毫秒为单位)。 默认值为3600000毫秒(一小时)。”
暂时的解决方案是将sun.rmi.dgc.server.gcInterval长度从默认的3,600秒增加。 我想知道,当RMI过去每分钟强制一次完整的GC时,在JDK 6中引入更改之前,情况如何。 考虑到当时所有的EJB狂潮,我猜没有一个应用程序在性能方面有机会。 如果您有远古时代的回忆,也许您可以向我们说明这些应用程序如何能够度过这种疯狂。
翻译自: https://www.javacodegeeks.com/2013/12/rmi-enforcing-full-gc-to-run-hourly.html

















 357
357

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









