





如果需要从Java处理大型数据库结果集,则可以选择JDBC,以提供所需的低级控制。 另一方面,如果您已在应用程序中使用ORM,则回退到JDBC可能意味着额外的麻烦。 在域模型中导航时,您将失去乐观锁定,缓存,自动获取等功能。 幸运的是,大多数ORM,例如Hibernate,都有一些选项可以帮助您。 尽管这些技术不是新技术,但有两种可能可供选择。
一个简化的例子; 假设我们有一个表(映射到类'DemoEntity'),具有100.000条记录。 每个记录都由一个列(映射到DemoEntity中的属性“ property”)组成,其中包含一些大约2KB的随机字母数字数据。
JVM与-Xmx250m一起运行。 假设250MB是可以分配给系统上JVM的总最大内存。 您的工作是读取表中当前的所有记录,进行一些未进一步指定的处理,最后存储结果。 我们假设批量操作产生的实体没有被修改。 首先,我们将首先尝试显而易见的方法,即执行查询以简单地检索所有数据:
new TransactionTemplate(txManager).execute(new TransactionCallback<Void>() {
@Override
public Void doInTransaction(TransactionStatus status) {
Session session = sessionFactory.getCurrentSession();
List<DemoEntity> demoEntitities = (List<DemoEntity>) session.createQuery('from DemoEntity').list();
for(DemoEntity demoEntity : demoEntitities){
//Process and write result
}
return null;
}
});几秒钟后:
Exception in thread 'main' java.lang.OutOfMemoryError: GC overhead limit exceeded 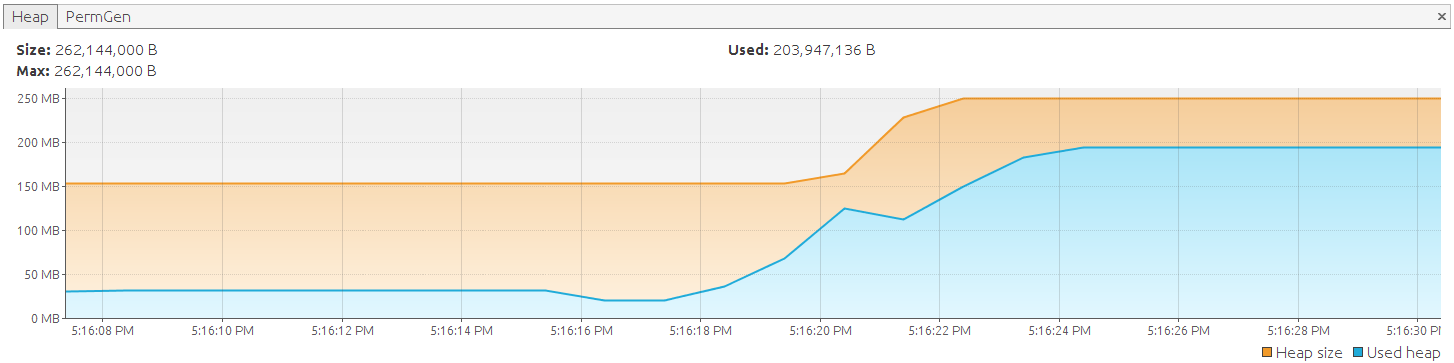
显然,这不会削减。 为了解决这个问题,我们将切换到Hibernate可滚动结果集,这可能是大多数开发人员都知道的。 上面的示例指示hibernate执行查询,将整个结果映射到实体并返回它们。 使用滚动结果集时,记录一次转换为一个实体:
new TransactionTemplate(txManager).execute(new TransactionCallback<Void>() {
@Override
public Void doInTransaction(TransactionStatus status) {
Session session = sessionFactory.getCurrentSession();
ScrollableResults scrollableResults = session.createQuery('from DemoEntity').scroll(ScrollMode.FORWARD_ONLY);
int count = 0;
while (scrollableResults.next()) {
if (++count > 0 && count % 100 == 0) {
System.out.println('Fetched ' + count + ' entities');
}
DemoEntity demoEntity = (DemoEntity) scrollableResults.get()[0];
//Process and write result
}
return null;
}
});运行之后,我们得到:
...
Fetched 49800 entities
Fetched 49900 entities
Fetched 50000 entities
Exception in thread 'main' java.lang.OutOfMemoryError: GC overhead limit exceeded 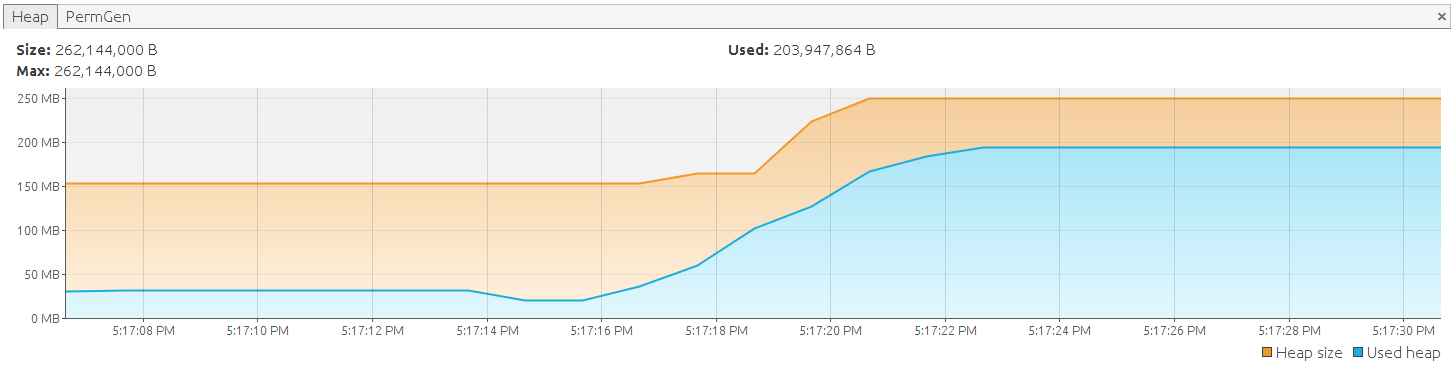
尽管我们使用的是可滚动的结果集,但每个返回的对象都是一个附加对象,并成为持久性上下文(也称为会话)的一部分。 结果实际上与我们使用“ session.createQuery('from DemoEntity')。list() '的第一个示例相同。 但是,采用这种方法,我们无法控制。 一切都在幕后发生,如果休眠完成了工作,您将获得包含所有数据的列表。 另一方面,使用可滚动的结果集使我们迷上了检索过程,并允许我们在需要时释放内存。 如我们所见,它不会自动释放内存,您必须指示Hibernate实际执行此操作。 存在以下选项:
- 处理对象后将其从持久性上下文中逐出
- 偶尔清除整个会话
我们将选择第一个。 在上面的示例的第13行( // Process和write result )下,我们将添加:
session.evict(demoEntity);重要:
- 如果您要对实体(或与它有关联的实体进行级联逐出的实体)进行任何修改,请确保在逐出或清除之前刷新会话,否则由于Hibernate的回写而导致的查询将不会发送到数据库
- 逐出或清除不会将实体从二级缓存中删除。 如果启用了二级缓存并正在使用它,并且还希望将其删除,请使用所需的sessionFactory.getCache()。evictXxx()方法
- 从您退出实体的那一刻起,该实体将不再附加(不再与会话关联)。 在该阶段对实体所做的任何修改将不再自动反映到数据库中。 如果您使用的是延迟加载,则访问驱逐之前未加载的任何属性都会产生著名的org.hibernate.LazyInitializationException。 因此,基本上,在逐出或清除之前,请确保已完成对该实体的处理(或至少已初始化以进一步满足需要)
再次运行该应用程序后,我们看到它现在已成功执行:
...
Fetched 99800 entities
Fetched 99900 entities
Fetched 100000 entities 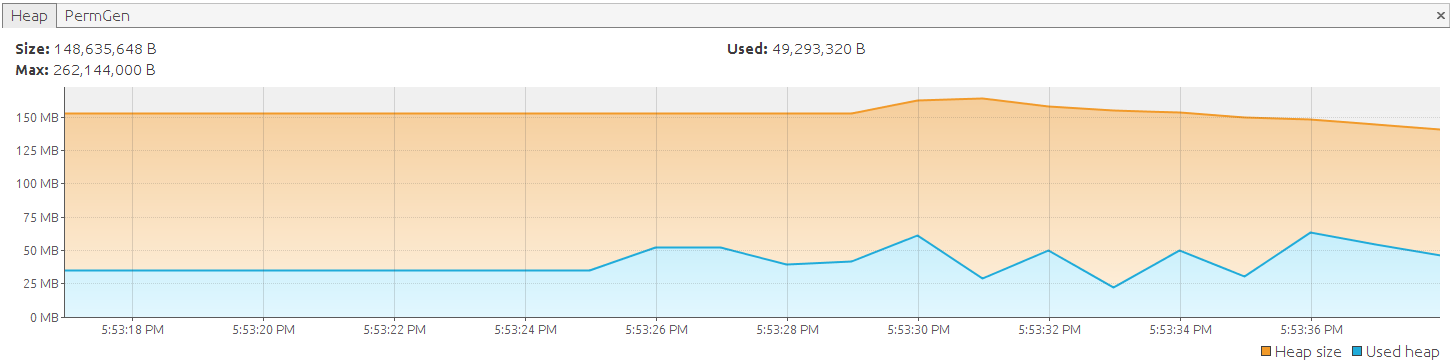
顺便说一句; 您还可以将查询设置为只读,以允许休眠状态执行一些其他优化:
ScrollableResults scrollableResults = session.createQuery('from DemoEntity').setReadOnly(true).scroll(ScrollMode.FORWARD_ONLY);这样做只会在内存使用方面产生很小的差异,在此特定的测试设置中,它使我们能够在给定的内存量下额外读取约300个实体。 就我个人而言,我不会仅将此功能仅用于内存优化,而仅当它适合您的整体不变性策略时才使用。 使用休眠模式,您可以使用不同的选项将实体设置为只读:在实体本身上,整个会话为只读,依此类推。 分别对查询设置只读为false可能是最不推荐的方法。 (例如,之前在会话中加载的实体将保持不受影响,可能可修改。即使查询返回的根对象是只读的,惰性关联也将可修改地加载)。
好的,我们能够处理我们的100.000条记录,生活很美好。 但是事实证明,Hibernate对于批量操作还有另一个选择:无状态会话。 您可以从无状态会话中获取可滚动结果集,方法与从普通会话中获取方法相同。 无状态会话直接位于JDBC之上。 Hibernate将在几乎“所有功能禁用”模式下运行。 这意味着没有持久上下文,没有第二级缓存,没有脏检测,没有延迟加载,基本上什么也没有。 从javadoc:
/**
* A command-oriented API for performing bulk operations against a database.
* A stateless session does not implement a first-level cache nor interact with any
* second-level cache, nor does it implement transactional write-behind or automatic
* dirty checking, nor do operations cascade to associated instances. Collections are
* ignored by a stateless session. Operations performed via a stateless session bypass
* Hibernate's event model and interceptors. Stateless sessions are vulnerable to data
* aliasing effects, due to the lack of a first-level cache. For certain kinds of
* transactions, a stateless session may perform slightly faster than a stateful session.
*
* @author Gavin King
*/它唯一要做的就是将记录转换为对象。 这可能是一个有吸引力的选择,因为它可以帮助您摆脱手动驱逐/冲洗的麻烦:
new TransactionTemplate(txManager).execute(new TransactionCallback<Void>() {
@Override
public Void doInTransaction(TransactionStatus status) {
sessionFactory.getCurrentSession().doWork(new Work() {
@Override
public void execute(Connection connection) throws SQLException {
StatelessSession statelessSession = sessionFactory.openStatelessSession(connection);
try {
ScrollableResults scrollableResults = statelessSession.createQuery('from DemoEntity').scroll(ScrollMode.FORWARD_ONLY);
int count = 0;
while (scrollableResults.next()) {
if (++count > 0 && count % 100 == 0) {
System.out.println('Fetched ' + count + ' entities');
}
DemoEntity demoEntity = (DemoEntity) scrollableResults.get()[0];
//Process and write result
}
} finally {
statelessSession.close();
}
}
});
return null;
}
}); 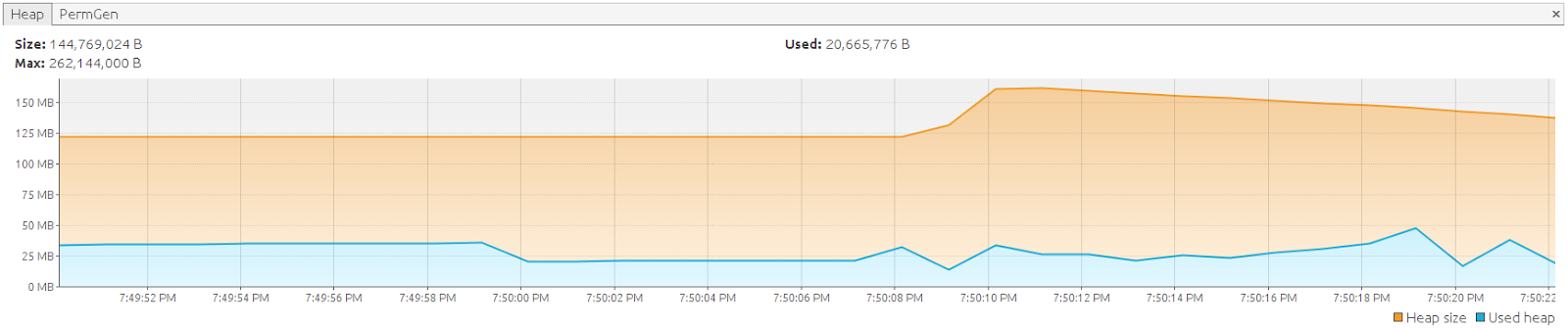
除了无状态会话具有最佳的内存使用情况外,使用它还会带来一些副作用。 您可能已经注意到,我们正在打开一个无状态会话并显式关闭它:既没有sessionFactory.getCurrentStatelessSession()也没有(在撰写本文时)任何用于管理无状态会话的Spring集成。打开无状态会话会分配一个新的Java。默认情况下sql.Connection(如果使用openStatelessSession() )执行其工作,因此间接产生第二个事务。 您可以通过使用Hibernate work API来减轻这些副作用,如提供当前Connection并将其传递给openStatelessSession(Connection connection)的示例中所示。 最后关闭会话对物理连接没有影响,因为它是由Spring基础结构捕获的:打开无状态会话时,仅关闭逻辑连接句柄,并创建新的逻辑连接句柄。
还要注意,您必须自己关闭无状态会话,并且上面的示例仅适用于只读操作。 从您打算使用无状态会话进行修改的那一刻起,还有一些警告。 如前所述,休眠模式在“所有功能都已禁用”模式下运行,因此直接导致实体以分离状态返回。 对于您修改的每个实体,您都必须显式调用: statelessSession.update(entity) 。 首先,我尝试使用此方法来修改实体:
new TransactionTemplate(txManager).execute(new TransactionCallback<Void>() {
@Override
public Void doInTransaction(TransactionStatus status) {
sessionFactory.getCurrentSession().doWork(new Work() {
@Override
public void execute(Connection connection) throws SQLException {
StatelessSession statelessSession = sessionFactory.openStatelessSession(connection);
try {
DemoEntity demoEntity = (DemoEntity) statelessSession.createQuery('from DemoEntity where id = 1').uniqueResult();
demoEntity.setProperty('test');
statelessSession.update(demoEntity);
} finally {
statelessSession.close();
}
}
});
return null;
}
});这个想法是我们用现有的数据库Connection打开一个无状态会话。 正如StatelessSession javadoc指示不会发生任何回写一样,我确信无状态会话执行的每个语句都将直接发送到数据库。 最终,当提交事务(由TransactionTemplate开始)时,结果将在数据库中可见。 但是,hibernate使用无状态会话来执行BATCH语句。 我不是100%知道批处理和回写之间有什么区别,但是结果是相同的,因此与javadoc的字典相反,因为语句在以后排入队列并刷新。 因此,如果您没有做任何特别的事情,批处理的语句将不会被刷新,这就是我的情况:'statelessSession.update(demoEntity);' 被分批处理,从不冲洗。 强制刷新的一种方法是使用休眠事务API:
StatelessSession statelessSession = sessionFactory.openStatelessSession();
statelessSession.beginTransaction();
...
statelessSession.getTransaction().commit();
...在这种情况下,您可能不希望仅因为使用无状态会话而开始以编程方式控制交易。 此外,由于没有传递我们的Connection,因此我们再次在第二个事务场景中运行无状态会话工作,因此将获得新的数据库连接。 我们无法通过外部连接的原因是,如果我们提交内部事务(“无状态会话事务”),并且它将使用与外部事务相同的连接(由TransactionTemplate开始),则会破坏外部事务事务的原子性,因为将外部事务发送到数据库的语句与内部事务一起提交。 因此,不通过连接意味着打开一个新的连接,从而创建第二笔交易。 更好的选择是触发Hibernate刷新无状态会话。 但是,statelessSession没有“ flush”方法来手动触发刷新。 解决方案是稍微依赖Hibernate内部API。 该解决方案使手动事务处理和第二个事务处理变得过时:所有语句成为我们(唯一的)外部事务的一部分:
StatelessSession statelessSession = sessionFactory.openStatelessSession(connection);
try {
DemoEntity demoEntity = (DemoEntity) statelessSession.createQuery('from DemoEntity where id = 1').uniqueResult();
demoEntity.setProperty('test');
statelessSession.update(demoEntity);
((TransactionContext) statelessSession).managedFlush();
} finally {
statelessSession.close();
}幸运的是,最近在Spring jira上发布了一个更好的解决方案: https : //jira.springsource.org/browse/SPR-2495这还不是Spring的一部分,但是工厂bean的实现非常简单: StatelessSessionFactoryBean。使用此Java时,您可以简单地注入StatelessSession:
@Autowired
private StatelessSession statelessSession;它将注入一个无状态的会话代理,这等效于正常的“当前”会话的工作方式(稍有不同的是,您注入一个SessionFactory并且每次都需要获取currentSession)。 调用代理时,它将查找绑定到正在运行的事务的无状态会话。 如果已经不存在,它将创建一个与普通会话相同的连接(就像我们在示例中所做的那样),并为无状态会话注册自定义事务同步。 提交事务后,由于同步,将刷新无状态会话,并最终将其关闭。 使用此方法,您可以直接注入无状态会话,并将其用作当前会话(或与注入JPA PeristentContext相同的方式)。 这使您不必处理无状态会话的打开和关闭,而不必处理一种或多种方法以使其变得畅通无阻。 该实现是针对JPA的,但是JPA部分仅限于在getPhysicalConnection()中获得物理连接。 您可以轻松地省略EntityManagerFactory并直接从Hibernate会话获取物理连接。
非常谨慎的结论:最好的方法显然取决于您的情况。 如果您使用普通会话,则在读取或保留实体时必须自行解决。 如果您有一个混合事务,那么除了必须手动执行操作之外,还可能影响会话的进一步使用。 你们都在同一笔交易中执行“批量”和“正常”操作。 如果继续进行正常操作,您将在会话中分离实体,这可能会导致意外结果(因为脏检测将不再起作用,依此类推)。 另一方面,您仍将具有主要的休眠好处(只要不驱逐该实体),例如延迟加载,缓存,脏检测等。 在编写本文时使用无状态会话需要额外注意管理它(打开,关闭和刷新),这也容易出错。 假设您可以继续使用建议的工厂bean,那么您将拥有一个非常裸露的会话,该会话与正常会话是分开的,但仍参与同一事务。 使用此工具,您无需执行内存管理即可拥有执行批量操作的强大工具。 缺点是您没有其他可用的休眠功能。
参考:在Koen Serneels – Technology博客博客上,从我们的JCG合作伙伴 Koen Serneels 与Hibernate进行批量获取 。
翻译自: https://www.javacodegeeks.com/2013/03/bulk-fetching-with-hibernate.html















 923
923

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









