





 这篇文章介绍了Java ByteBuffer的使用,包括它的抽象概念、与字节数组的区别、关键属性、最佳实践和常见陷阱。ByteBuffer的API复杂,正确使用它可以避免混淆和错误。文章强调了flip()方法的重要性,以及使用array()方法时的注意事项,还提到了compareTo()方法受字节签名的影响。了解这些最佳实践有助于更有效地使用ByteBuffer。
这篇文章介绍了Java ByteBuffer的使用,包括它的抽象概念、与字节数组的区别、关键属性、最佳实践和常见陷阱。ByteBuffer的API复杂,正确使用它可以避免混淆和错误。文章强调了flip()方法的重要性,以及使用array()方法时的注意事项,还提到了compareTo()方法受字节签名的影响。了解这些最佳实践有助于更有效地使用ByteBuffer。
以我的经验,当开发人员第一次遇到java.nio.ByteBuffer时,会引起混乱和细微的错误,因为如何正确使用它尚不明显。 在我对API文档感到满意之前,需要反复阅读API文档和一些经验以实现一些微妙之处。 这篇文章是关于如何正确使用它们的短暂崩溃,希望可以为其他人节省一些麻烦。
由于所有这些都是基于推断(而不是基于明确的文档),并且是基于经验,因此我不能断言这些信息必定是权威的。 我欢迎您提出反馈意见,以指出错误或其他观点。 我也欢迎提出其他陷阱/最佳做法的建议。
我确实假定读者将阅读与本文相关的API文档。 我不会穷尽所有您可以使用ByteBuffer进行的操作。
ByteBuffer抽象
可以将ByteBuffer看作提供了一些(未定义的)底层字节存储的视图 。 字节缓冲区的两种最常见的具体类型是由字节数组支持的字节缓冲区和由直接(脱离堆,本机)字节缓冲区支持的字节缓冲区。 在两种情况下,都可以使用相同的接口读取和写入缓冲区的内容。
ByteBuffer的API的某些部分特定于某些类型的字节缓冲区。 例如,字节缓冲区可以是只读的 ,将用法限制为方法的子集。 array()方法仅适用于由字节数组支持的字节缓冲区(可以使用hasArray()进行测试),并且通常仅在完全知道自己在做什么的情况下使用 。 一个常见的错误是使用array()将ByteBuffer“转换”为字节数组。 这不仅仅适用于字节数组支持的缓冲区,而且很容易成为错误的来源,因为根据缓冲区的创建方式,返回数组的开头可能与字节缓冲区的开头相对应, 也可能不对应。 结果往往是一个细微的错误,其中代码的行为根据字节缓冲区和创建它的代码的实现细节而有所不同。
ByteBuffer可以通过调用repeat()复制自身。 这实际上并不复制基础字节 ,而只是创建一个指向相同基础存储的新ByteBuffer实例。 可以使用slice()创建表示另一个ByteBuffer的子集的ByteBuffer。
与字节数组的主要区别
- ByteBuffer具有关于hashCode() / equals()的值语义,因此可以更方便地在容器中使用。
- ByteBuffer通过实例化新的ByteBuffer,提供了将字节缓冲区的子集作为值传递而不复制字节的功能。
- NIO API大量使用了ByteBuffer:s。
- ByteBuffer中的字节可能驻留在Java堆之外。
- ByteBuffer的状态超出了字节本身,这有利于进行相对的I / O操作(但有一些警告,请参见下文)。
- ByteBuffer提供了用于读取和写入各种原始类型(如整数和long)的方法(并且可以按不同的字节顺序进行操作)。
ByteBuffer的关键属性
ByteBuffer的以下三个属性至关重要(我在每个属性上引用了API文档):
- 缓冲区的容量是它包含的元素数量。 缓冲区的容量永远不会为负,也不会改变。
- 缓冲区的限制是不应读取或写入的第一个元素的索引。 缓冲区的限制永远不会为负,也永远不会大于缓冲区的容量。
- 缓冲区的位置是下一个要读取或写入的元素的索引。 缓冲区的位置永远不会为负,也不会大于其限制。
这是一个示例ByteBuffer的可视化示例,在示例中,ByteBuffer由字节数组支持,并且ByteBuffer的值是单词“ test”(单击以放大):
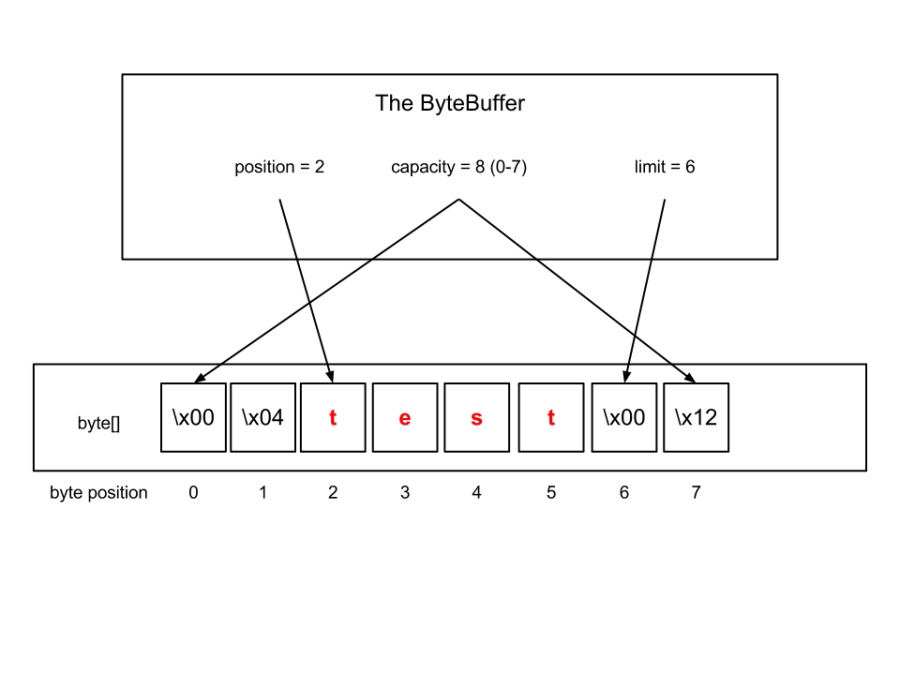
该ByteBuffer等于(在equals()的意义上) 等于其在[ position , limit )之间内容相同的任何其他ByteBuffer。
假设上面显示的字节缓冲区是bb ,我们这样做:
final ByteBuffer other = bb.duplicate();
other.position(bb.position() + 4);现在,我们将有两个ByteBuffer实例都引用相同的基础字节数组,但是它们的内容将有所不同( 其他将为空):
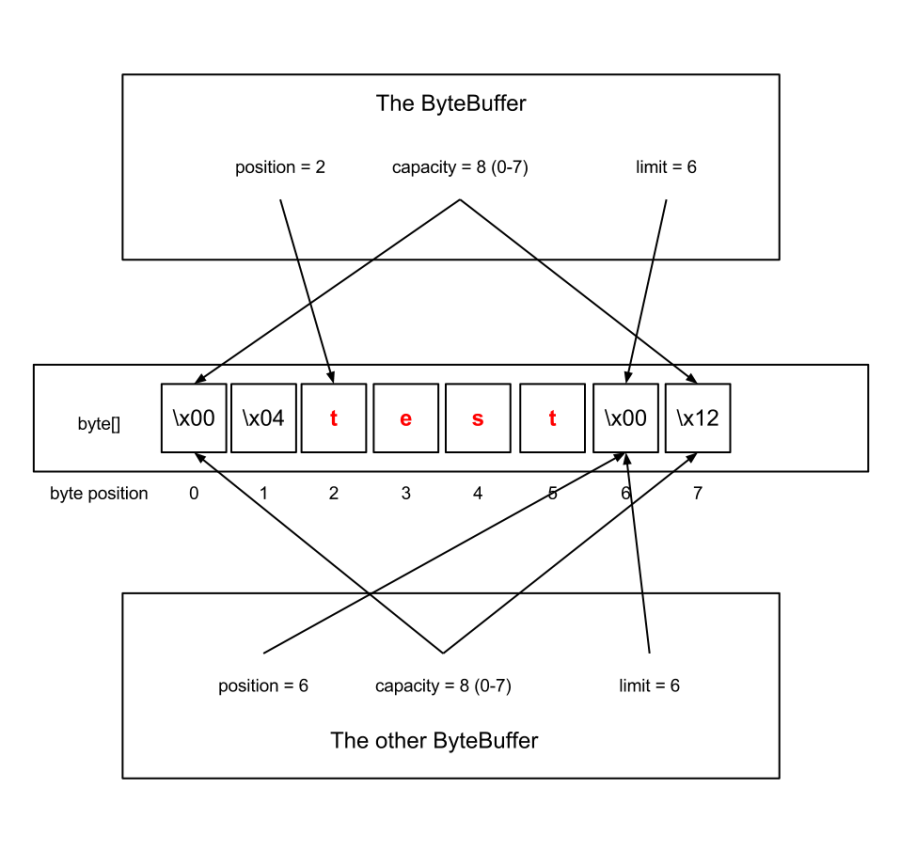
字节缓冲区的缓冲区/流对偶
有两种访问字节缓冲区内容的方法- 绝对访问和相对访问。 例如,假设我有一个ByteBuffer,我知道它包含两个整数。 为了使用绝对定位提取整数,可以这样做:
int first = bb.getInt(0)
int second = bb.getInt(4)或者,可以使用相对定位提取它们:
int first = bb.getInt();
int second = bb.getInt();第二种选择通常很方便,但是以对缓冲区产生副作用 (即更改它)为代价。 不是内容本身,而是ByteBuffers视图可以查看该内容。
这样,如果将ByteBuffer用作流,则其行为类似于流。
最佳做法和陷阱
flip()缓冲区
如果要通过重复写入来构建ByteBuffer,然后想将其赠送,则必须记住将它翻转() 。 例如,这是一种将字节数组复制到ByteBuffer的方法,并假设使用默认编码(请注意,此处使用的ByteBuffer.wrap()创建一个包装指定字节数组的ByteBuffer,而不是复制其中的内容放入新的ByteBuffer中):
public static ByteBuffer fromByteArray(byte[] bytes) {
final ByteBuffer ret = ByteBuffer.wrap(new byte[bytes.length]);
ret.put(bytes);
ret.flip();
return ret;
}如果我们不翻转它,则返回的ByteBuffer 将为空,因为该位置等于limit 。
不要消耗缓冲区
除非特别打算这样做,否则在读取字节缓冲区时请注意不要“消耗”它。 例如,考虑采用默认编码方式,将ByteBuffer转换为String的此方法:
public static String toString(ByteBuffer bb) {
final byte[] bytes = new byte[bb.remaining()];
bb.duplicate().get(bytes);
return new String(bytes);
}不幸的是,没有提供进行字节数组的绝对定位读取的方法(但确实存在用于基元的绝对定位读取)。
注意在读取字节时使用了plicate() 。 如果我们不这样做,该函数将对输入ByteBuffer产生副作用 。 这样做的代价是仅为了一次调用get()的目的就额外分配了一个新的ByteBuffer。 您可以在get()之前记录ByteBuffer的位置,然后再将其还原,但这存在线程安全性问题(请参阅下一节)。
值得注意的是,这仅在您尝试将ByteBuffer:s视为值时适用。 如果您正在编写旨在对ByteBuffer产生副作用的代码,将它们更像流一样对待,那么您当然打算这样做,并且本节不适用。
不要改变缓冲区
在不是特定于特定用例的通用代码的情况下,(在我看来)对于执行(抽象)只读操作(例如读取字节缓冲区)的方法来说是一种好习惯。 ,不更改其输入。 这是比“不要消耗ByteByffer”更强的要求。 以上一节中的示例为例,但尝试避免额外分配ByteBuffer:
public static String toString(ByteBuffer bb) {
final byte[] bytes = new byte[bb.remaining()];
bb.mark(); // NOT RECOMMENDED, don't do this
bb.get(bytes);
bb.reset(); // NOT RECOMMENDED, don't do this
return new String(bytes);
}在这种情况下,我们在调用get()之前记录ByteBuffer的状态,然后再进行恢复(请参阅API文档中的mark()和reset() )。 这种方法有两个问题。 第一个问题是上面的函数没有组成 。 一个ByteBuffer仅具有一个“标记”,并且您的(非常通用,不具有上下文意识) toString()方法不能安全地假定调用者并未出于自身目的尝试使用mark()和reset() 。 例如,假设以下调用者正在反序列化一个长度为前缀的字符串:
bb.mark();
int length = bb.getInt();
... sanity check length
final String str = ByteBufferUtils.toString(bb);
... do something
bb.reset(); // OOPS - reset() will now point 4 bytes off, because toString() modified the mark(顺便说一句,这是一个非常人为且奇怪的示例,因为我发现很难提出一个使用mark() / reset()的实际代码示例,该代码通常在处理流中的缓冲区时使用,像派系一样,也感觉需要在所述缓冲区的其余部分上调用toString() 。我很想听听人们在这里提出了什么解决方案。例如,可以想象一个清晰的代码库中的策略在类似于toString()的面向值的上下文中允许mark() / reset() –但是即使您这样做了(它可能会无意中违反了它的味道),您仍然会遭受后面提到的突变问题。)
让我们看一下避免这种问题的toString()的替代版本:
public static String toString(ByteBuffer bb) {
final byte[] bytes = new byte[bb.remaining()];
bb.get(bytes);
bb.position(bb.position() - bytes.length); // NOT RECOMMENDED, don't do this
return new String(bytes);
}在这种情况下,我们不修改标记,因此我们进行撰写。 但是,我们仍然致力于改变输入的“罪行”。 在多线程情况下,这是一个问题。 除非抽象隐含了该内容(例如,使用流或以类似流的方式使用ByteBuffer时),否则您不希望阅读暗示其变化的内容。 如果要传递的ByteBuffer视为一个值,将其放入容器中,共享它们,等等–除非保证两个线程永远不会同时使用同一个ByteBuffer,否则对它们进行突变将引入细微的错误。 通常,此类错误的结果是奇怪的值损坏或意外的BufferOverFlowException:s。
不受此影响的版本出现在上面的“不要使用缓冲区”部分,该部分使用duplicate()构造一个临时的ByteBuffer实例,可以在其上安全调用get() 。
compareTo()受字节签名的约束
Java中的字节是有符号的 ,这与通常期望的相反。 但是,容易错过的是,这也会影响ByteBuffer.compareTo() 。 该方法的Java API文档显示为:
“通过按字典顺序比较剩余字节的序列来比较两个字节缓冲区,而不考虑每个序列在其相应缓冲区中的开始位置。”
快速阅读可能会使人相信结果通常是您期望的,但是当然,鉴于Java中字节的定义,情况并非如此。 结果是,包含最高位设置的值的字节缓冲区的顺序将与您期望的有所不同。
Google出色的Guava库具有UnsignedBytes帮助器 ,可减轻您的痛苦。
array()通常是使用错误的方法
通常,不要随便使用array() 。 为了正确使用它,您要么必须知道字节缓冲区是数组支持的事实 ,要么必须使用 hasArray() 对其进行测试,并且在两种情况下都有两个单独的代码路径。 此外,在使用它时, 必须使用arrayOffset()以确定ByteBuffer的第零个位置与字节数组相对应。
在典型的应用程序代码中,除非您真的知道自己在做什么并且特别需要它,否则您将不会使用array() 。 也就是说,在某些情况下它很有用。 例如,假设您实现的是UnsignedBytes.compare()的ByteBuffer版本(同样来自Guava )–您可能希望优化其中一个或两个参数都支持数组的情况,以避免不必要的复制和频繁调用。缓冲区。 对于这种通用且可能大量使用的方法,这种优化是有意义的。
参考: Java ByteBuffer –我们的JCG合作伙伴 Peter Schuller在(mod:world:scode)博客上的速成班 。
翻译自: https://www.javacodegeeks.com/2012/12/the-java-bytebuffer-a-crash-course.html















 560
560

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









