





Hadoop是一种用Java编写的框架,用于在大型商品硬件集群上运行应用程序,并具有类似于Google File System和MapReduce的功能 。 HDFS是高度容错的分布式文件系统,与Hadoop一样,旨在部署在低成本硬件上。 它提供对应用程序数据的高吞吐量访问,并且适用于具有大数据集的应用程序。
Hadoop主要由处理大量数据的公司使用。 他们可能需要处理数据 , 执行分析或生成报告 。 当前,所有领先的组织,包括Facebook,Yahoo,Amazon,IBM,Joost,PowerSet,New York Times,Veoh等,都在使用Hadoop。 有关更多信息,请查看PoweredBy Hadoop页面 。

为什么选择Hadoop:
MapReduce是Google的秘密武器:一种将复杂的问题分解并散布到许多计算机上的方法。 Hadoop是MapReduce及其自己的文件系统HDFS(Hadoop分布式文件系统)的开源实现。
Hadoop在某种程度上击败了超级计算机:
Hadoop集群在209秒内对1 TB的数据进行了排序,在年度通用(daytona)TB的基准测试中打破了之前297秒的记录。 排序基准由Jim Gray于1998年创建,它指定了输入数据(100亿条100字节记录),这些数据必须完全排序并写入磁盘。 这是Java或开放源代码程序的首次获奖。 有关更多信息, 请单击此处 。
欧洲最大的广告定位平台使用Hadoop:
欧洲最大的广告公司每天可获得超过100GB的数据,现在使用RDBMS等经典解决方案需要5天的时间进行分析并生成报告。 因此他们落后1个弱点。 经过大量研究,他们开始使用hadoop。 现在有趣的事实是“ Tey能够在1小时内处理数据并生成报告”,这就是Hadoop的魅力所在。 有关更多信息, 请单击此处 。
Hadoop的主要发行版:
1. Apache Hadoop:
Apache Hadoop项目开发了用于可靠,可扩展的分布式计算的开源软件。
Apache Hadoop提供:
- Hadoop Common :支持其他Hadoop子项目的通用实用程序。
- HDFS :一种分布式文件系统,可提供对应用程序数据的高吞吐量访问。
- MapReduce :一个用于在计算集群上对大型数据集进行分布式处理的软件框架。
- Avro :数据序列化系统。
- Chukwa :用于管理大型分布式系统的数据收集系统。
- HBase :可扩展的分布式数据库,支持大型表的结构化数据存储。
- Hive :一种数据仓库基础结构,可提供数据汇总和即席查询。
- Mahout :可扩展的机器学习和数据挖掘库。
- Pig :用于并行计算的高级数据流语言和执行框架。
- ZooKeeper :针对分布式应用程序的高性能协调服务。
2. Cloudera Hadoop:
Cloudera的Apache Hadoop发行版(CDH)为基于Hadoop的数据管理平台设定了新标准。 它是当今可用的最全面的平台,可显着加速组织中Apache Hadoop的部署。 CDH基于Apache Hadoop的最新稳定版本。 它包括一些从将来发行版反向移植的有用补丁,以及我们为客户开发的改进
Cloudera Hadoop提供:
- HDFS –自愈式分布式文件系统
- MapReduce –强大的并行数据处理框架
- Hadoop Common –一组支持Hadoop子项目的实用程序
- HBase – Hadoop数据库,用于随机读写访问
- Hive –大型数据集上类似SQL的查询和表
- Pig –数据流语言和编译器
- Oozie –相互依赖的Hadoop作业的工作流程
- Sqoop –将数据库和数据仓库与Hadoop集成
- Flume –高度可靠,可配置的流数据收集
- Zookeeper –分布式应用程序的协调服务
- Hue –用于可视Hadoop应用程序的用户界面框架和SDK
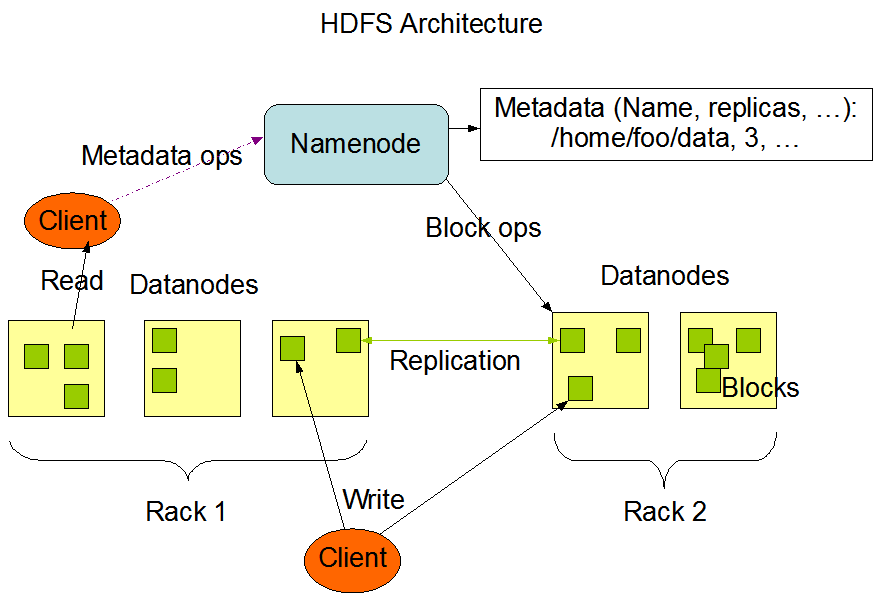
Hadoop可以三种方式安装
要以独立模式部署Hadoop,我们只需要设置JAVA_HOME的路径即可。 在这种模式下,不需要启动守护程序,也不需要名称节点格式,因为数据保存在本地磁盘中。
在这种模式下,所有守护程序(nameNode,dataNode,secondaryNameNode,jobTracker,taskTracker)都在一台机器上运行。
在此模式下,守护程序(nameNode,jobTracker,secondaryNameNode(可选))在主服务器(NameNode)上运行,守护程序(dataNode和taskTracker)在从属服务器(DataNode)上运行。 请继续关注有关三种Hadoop模式/配置的文章。
相关文章 :
- MapReduce:简单介绍
- Cajo,用Java完成分布式计算的最简单方法
- Hibernate映射集合性能问题
- Java Code Geeks Andygene Web原型
- Servlet 3.0异步处理可将服务器吞吐量提高十倍
参考:通过高性能计算博客上的 JCG合作伙伴 了解什么是Hadoop 。
翻译自: https://www.javacodegeeks.com/2011/05/hadoop-soft-introduction.html















 926
926

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









