





在本教程中,我想谈谈Apache Lucene 。 Lucene是一个开源项目,提供基于Java的索引和搜索技术。 使用其API,很容易实现全文搜索 。 我将处理Lucene Java版本 ,但请记住,还有一个名为Lucene.NET的.NET端口,以及一些有用的子项目。
我最近阅读了有关该项目的精彩教程 ,但没有提供实际的代码。 因此,我决定提供一些示例代码来帮助您开始使用Lucene。 我们将构建的应用程序将允许您索引自己的源代码文件并搜索特定的关键字。
首先,让我们从其中一个Apache Download Mirrors下载最新的稳定版本。 我将使用的版本是3.0.1,所以我下载了lucene-3.0.1.tar.gz捆绑包(请注意,.tar.gz版本明显小于相应的.zip版本)。 解压缩tarball并找到lucene-core-3.0.1.jar文件,稍后将使用它。 此外,请确保在浏览器中打开Lucene API JavaDoc页面(文档也包含在压缩包中以供离线使用)。 接下来,设置一个新的Eclipse项目,假设其名称为“ LuceneIntroProject”,并确保在项目的类路径中包含上述JAR。
在开始运行搜索查询之前,我们需要构建一个索引,将针对该索引执行查询。 这将在名为IndexWriter的类的帮助下完成,该类是创建和维护索引的类。 IndexWriter接收Document作为输入,其中document是索引和搜索的单位。 每个Document实际上是一组Field ,每个字段都有一个名称和一个文本值。 要创建IndexWriter,需要使用分析器 。 此类是抽象的,我们将使用的具体实现是SimpleAnalyzer 。
已经说够了,让我们创建一个名为“ SimpleFileIndexer”的类,并确保包含一个主要方法。 这是此类的源代码:
package com.javacodegeeks.lucene;
import java.io.File;
import java.io.FileReader;
import java.io.IOException;
import org.apache.lucene.analysis.SimpleAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.store.FSDirectory;
public class SimpleFileIndexer {
public static void main(String[] args) throws Exception {
File indexDir = new File("C:/index/");
File dataDir = new File("C:/programs/eclipse/workspace/");
String suffix = "java";
SimpleFileIndexer indexer = new SimpleFileIndexer();
int numIndex = indexer.index(indexDir, dataDir, suffix);
System.out.println("Total files indexed " + numIndex);
}
private int index(File indexDir, File dataDir, String suffix) throws Exception {
IndexWriter indexWriter = new IndexWriter(
FSDirectory.open(indexDir),
new SimpleAnalyzer(),
true,
IndexWriter.MaxFieldLength.LIMITED);
indexWriter.setUseCompoundFile(false);
indexDirectory(indexWriter, dataDir, suffix);
int numIndexed = indexWriter.maxDoc();
indexWriter.optimize();
indexWriter.close();
return numIndexed;
}
private void indexDirectory(IndexWriter indexWriter, File dataDir,
String suffix) throws IOException {
File[] files = dataDir.listFiles();
for (int i = 0; i < files.length; i++) {
File f = files[i];
if (f.isDirectory()) {
indexDirectory(indexWriter, f, suffix);
}
else {
indexFileWithIndexWriter(indexWriter, f, suffix);
}
}
}
private void indexFileWithIndexWriter(IndexWriter indexWriter, File f,
String suffix) throws IOException {
if (f.isHidden() || f.isDirectory() || !f.canRead() || !f.exists()) {
return;
}
if (suffix!=null && !f.getName().endsWith(suffix)) {
return;
}
System.out.println("Indexing file " + f.getCanonicalPath());
Document doc = new Document();
doc.add(new Field("contents", new FileReader(f)));
doc.add(new Field("filename", f.getCanonicalPath(),
Field.Store.YES, Field.Index.ANALYZED));
indexWriter.addDocument(doc);
}
} 让我们来谈谈这个课程。 我们提供了索引的位置,即索引数据将保存在磁盘上的位置(“ c:/ index /”)。 然后,我们提供数据目录,即将递归扫描输入文件的目录。 为此,我选择了整个Eclipse工作区(“ C:/ programs / eclipse / workspace /”)。 由于我们只希望为Java源代码文件建立索引,因此我还添加了一个后缀字段。 您显然可以根据您的搜索需求调整这些值。 “索引”方法考虑了先前的参数,并使用IndexWriter的新实例来执行目录索引。 “ indexDirectory”方法使用一种简单的递归算法来扫描所有目录以查找带有.java后缀的文件。 对于每个符合条件的文件,将在“ indexFileWithIndexWriter”中创建一个新文档,并填充相应的字段。 如果您通过Eclipse将类作为Java应用程序运行,则输入目录将被索引,输出目录将如下图所示: 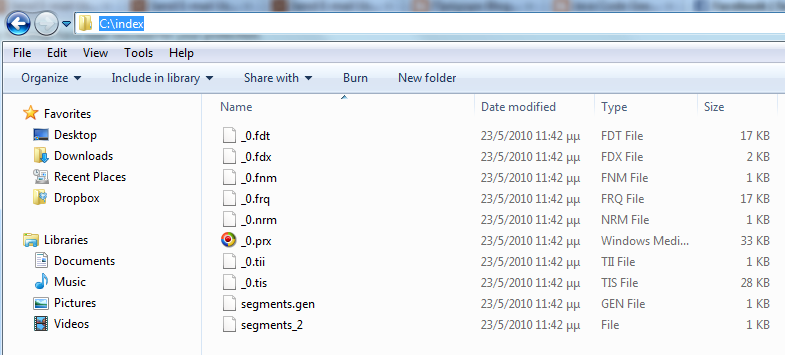 好的,我们完成了索引工作,让我们继续进行方程式的搜索部分。 为此,需要一个IndexSearcher类,它是实现主要搜索方法的类。 对于每次搜索,都需要一个新的Query对象(SQL可以使用SQL吗?),可以从QueryParser实例中获得该对象。 请注意,必须使用与创建索引相同的分析器类型来创建QueryParser,在我们的示例中,使用SimpleAnalyzer。 根据JavaDocs, Version也用作构造函数参数,并且是一个“被某些类用来在Lucene的各个发行版之间匹配版本兼容性”的类。 诸如此类的存在使我感到困惑,但是无论如何,让我们为应用程序使用适当的版本( Lucene_30 )。 由IndexSearcher执行搜索时,将返回TopDocs对象作为执行结果。 此类仅表示搜索结果,并允许我们检索ScoreDoc对象。 使用ScoreDocs,我们找到符合搜索条件的文档,然后从这些文档中检索所需的信息。 让我们看看所有这些都在起作用。 创建一个名为“ SimpleSearcher”的类,并确保包含一个主要方法。 此类的源代码如下:
好的,我们完成了索引工作,让我们继续进行方程式的搜索部分。 为此,需要一个IndexSearcher类,它是实现主要搜索方法的类。 对于每次搜索,都需要一个新的Query对象(SQL可以使用SQL吗?),可以从QueryParser实例中获得该对象。 请注意,必须使用与创建索引相同的分析器类型来创建QueryParser,在我们的示例中,使用SimpleAnalyzer。 根据JavaDocs, Version也用作构造函数参数,并且是一个“被某些类用来在Lucene的各个发行版之间匹配版本兼容性”的类。 诸如此类的存在使我感到困惑,但是无论如何,让我们为应用程序使用适当的版本( Lucene_30 )。 由IndexSearcher执行搜索时,将返回TopDocs对象作为执行结果。 此类仅表示搜索结果,并允许我们检索ScoreDoc对象。 使用ScoreDocs,我们找到符合搜索条件的文档,然后从这些文档中检索所需的信息。 让我们看看所有这些都在起作用。 创建一个名为“ SimpleSearcher”的类,并确保包含一个主要方法。 此类的源代码如下:
package com.javacodegeeks.lucene;
import java.io.File;
import org.apache.lucene.analysis.SimpleAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.queryParser.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
public class SimpleSearcher {
public static void main(String[] args) throws Exception {
File indexDir = new File("c:/index/");
String query = "lucene";
int hits = 100;
SimpleSearcher searcher = new SimpleSearcher();
searcher.searchIndex(indexDir, query, hits);
}
private void searchIndex(File indexDir, String queryStr, int maxHits)
throws Exception {
Directory directory = FSDirectory.open(indexDir);
IndexSearcher searcher = new IndexSearcher(directory);
QueryParser parser = new QueryParser(Version.LUCENE_30,
"contents", new SimpleAnalyzer());
Query query = parser.parse(queryStr);
TopDocs topDocs = searcher.search(query, maxHits);
ScoreDoc[] hits = topDocs.scoreDocs;
for (int i = 0; i < hits.length; i++) {
int docId = hits[i].doc;
Document d = searcher.doc(docId);
System.out.println(d.get("filename"));
}
System.out.println("Found " + hits.length);
}
}我们提供索引目录,搜索查询字符串和最大匹配数,然后调用“ searchIndex”方法。 在该方法中,我们创建一个IndexSearcher,一个QueryParser和一个Query对象。 请注意,QueryParser使用我们用于使用IndexWriter创建文档的字段的名称(“内容”),并且再次使用相同类型的分析器(SimpleAnalyzer)。 我们执行搜索,并为找到匹配项的每个Document提取包含文件名(“ filename”)的字段的值,然后进行打印。 就是这样,让我们执行实际的搜索。 作为Java应用程序运行它,您将看到包含您提供的查询字符串的文件的名称。
可以从此处下载本教程的Eclipse项目,包括依赖库。
更新:您还可以使用Apache Lucene Spell-Checker查看我们后续的文章“您的意思是”功能 。
请享用!
翻译自: https://www.javacodegeeks.com/2010/05/introduction-to-apache-lucene-for-full.html















 557
557

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









