





你好!你好吗? 今天,我们将讨论不建议使用JPA / Hibernate的情况。 在JPA领域之外,我们还有哪些选择?
我们将谈论的是:
- JPA /休眠问题
- 解决一些JPA /休眠问题的方法
- 选择此处描述的框架的标准
- Spring JDBC模板
- MyBatis
- 索莫拉
- sql2o
- 看看:jOOQ和Avaje
- 原始的JDBC方法值得吗?
- 如何选择正确的框架?
- 最后的想法
我使用本文中提到的框架在github中创建了4个CRUD,您将在每个页面的开头找到URL。
我并不是认为JPA一文不值的激进主义者,但我确实相信我们需要针对每种情况选择正确的框架。 如果您不知道我写了一本JPA书(仅葡萄牙语),并且我认为JPA是解决所有问题的灵丹妙药。
JPA /休眠问题
有时候,JPA弊大于利。 在下面,您将看到JPA /休眠问题,在下一页中,您将看到一些针对这些问题的解决方案:
- 复合密钥:我认为,这是JPA开发人员最大的麻烦。 当我们映射一个组合键时,当我们需要持久化或在数据库中找到一个对象时,这给项目增加了巨大的复杂性。 当您使用组合键时,可能会发生一些问题,其中一些问题可能是实现错误。
- 旧版数据库:当需要调用StoredProcedures或Functions时,数据库中包含许多业务规则的项目可能会成为问题。
- 工件大小:如果您使用的是Hibernate实现,那么工件大小会增加很多。 Hibernate使用大量依赖项,这将增加生成的jar / war / ear的大小。 如果开发人员需要在Internet带宽较低(或上传速度较慢)的多个远程服务器中进行部署,则工件大小可能会成为问题。 想象一个项目,在每个新版本中,有必要在全国范围内更新10个客户服务器。 上载速度慢,文件损坏和Internet丢失等问题可能会导致开发人员/运营团队浪费更多时间。
- 生成的SQL:JPA的优势之一是数据库的可移植性,但是要使用此可移植性的优势,您需要使用JPQL / HQL 语言 。 当生成的查询性能较差并且不使用为优化查询而创建的表索引时,此优点可能成为不利条件。
- 复杂查询:这些项目使用数据库资源(例如SUM,MAX,MIN,COUNT,HAVING等)进行多个具有高度复杂性的查询。如果将这些资源结合使用,JPA性能可能会下降并且不使用表索引,否则您将无法使用可以解决此问题的特定数据库资源。
- 框架复杂性:使用JPA创建CRUD非常简单,但是当我们开始使用实体关系,继承,缓存,PersistenceUnit操作,具有多个实体的PersistenceContext等时,就会出现问题。没有开发人员的开发团队具有良好的JPA经验使用JPA“ 规则 ”会浪费很多时间。
- 处理缓慢且占用大量RAM内存:在某些情况下,JPA会在报表处理中失去性能,插入大量实体或长时间打开的事务存在问题。
阅读完以上所有问题后,您可能会想:“ JPA擅长做任何事情吗?”。 JPA具有许多优点,在这里将不做详细介绍,因为这不是后期主题,JPA是一种在很多情况下都可以使用的工具。 JPA的一些优势是:数据库可移植性,节省大量开发时间,使创建查询更容易,缓存优化,庞大的社区支持等。
在下一页中,我们将为上述问题提供一些解决方案,这些解决方案可以帮助您避免庞大的持久性框架重构。 我们将看到一些修复或解决此处描述的问题的技巧。
解决一些JPA /休眠问题的方法
如果要考虑删除项目的JPA,则需要小心。
我不是那种认为应该在寻求解决方案之前删除整个框架的开发人员。 有时候,最好选择一种不那么介入的方法。
复合键
不幸的是,这个问题没有很好的解决方案。 如果可能,请避免使用业务规则不需要的带有复合键的表。 我已经看到开发人员在可以应用简单键的情况下使用复合键,而不必要地将复合键的复杂性添加到了项目中。
旧版数据库
最新的JPA版本(2.1)支持StoredProcedures and Functions,有了此新资源,将更易于与数据库进行通信。 如果无法升级JPA版本,我认为JPA不是您的最佳解决方案。
您可以使用一些供应商资源,例如Hibernate,但是您将失去数据库和实现的可移植性。
工件尺寸
解决此问题的一个简单方法是更改JPA实现。 可以使用Eclipsellink,OpenJPA或Batoo代替使用Hibernate实现。 如果项目正在使用Hibernate批注/资源,则可能会出现问题。 实现更改将需要一些代码重构。
生成的SQL和复杂查询
解决这些问题的方法是使用名为NativeQuery的资源。 使用此资源,您可以拥有简化的查询或优化的SQL,但是您将牺牲数据库的可移植性。
您可以将查询放入文件中,例如SEARCH_STUDENTS_ORACLE或SEARCH_STUDENTS_MYSQL,在生产环境中,将访问正确的文件。 这种方法的问题在于,必须为每个数据库编写相同的查询。 如果需要编辑SEARCH_STUDENTS查询,则需要编辑oracle和mysql文件。
如果您的项目只有一个数据库供应商,则NativeQuery资源不会有问题。
这种混合方法(同一项目中的JPQL和NativeQuery)的优点是可以利用其他JPA优点。
处理速度慢,内存容量大
可以通过优化查询(使用NativeQuery),查询分页和小事务来解决此问题。
避免将EJB与PersistenceContext Extended一起使用,这种上下文将消耗更多的内存和服务器处理能力。
也有可能从数据库中获取一个实体作为“ 只读 ”实体,例如:将仅在报表中使用的实体。 要恢复处于“ 只读 ”状态的实体无需打开交易,请查看以下代码:
String query = "select uai from Student uai";
EntityManager entityManager = entityManagerFactory.createEntityManager();
TypedQuery<Student> typedQuery = entityManager.createQuery(query, Student.class);
List<Student> resultList = typedQuery.getResultList();请注意,在上面的代码中没有打开的事务,所有返回的实体都将被分离(不受JPA监视)。 如果使用EJB,则将事务标记为NOT_SUPPORTED,或者可以使用@Transactional(readOnly = true)。
复杂
我想说,解决这个问题只有一种解决方案:学习。 有必要阅读书籍,博客,杂志或JPA材料的任何其他可靠来源。 在JPA中,更多的研究等于更少的疑问。
我不是一个开发人员,它相信JPA是解决每个问题的唯一且最佳的解决方案,但是有时候JPA并不是使用工具的最佳方法。
在决定更改持久性框架时,您必须小心,通常会影响很多类,并且需要大量的重构。 此重构可能会导致一些错误。 需要与项目经理讨论这种重构,并列出所有正面和负面影响。
在接下来的四页中,我们将看到可以在我们的项目中使用的4个持久性框架,但是在看到这些框架之前,我将展示如何选择每个框架。
选择此处描述的框架的标准
也许您会想到:“为什么框架X不在这里?”。 下面,我将列出用于选择此处显示的框架的标准:
- 可以在多个研究来源中找到:我们可以在论坛中找到谈论框架的人们,但是要在多个论坛中找到相同的框架却很难。 选择了引用最多的框架。
- 由不同来源引用 :在论坛中找到的某些框架仅由其提交者指示。 一些论坛不允许使用“自我商品”,但是某些框架所有者仍在这样做。
- 最后更新时间 : 2013年1月5日 :我搜索了过去一年中已更新的框架。
- 快速的Hello World :有些框架在15分钟至20分钟的时间内无法完成Hello World,并且存在一些错误。 在这篇文章中找到的教程中,我在每个框架上工作了7分钟:从下载开始算起,直到第一个数据库插入。
这里将显示的框架具有良好的方法并且易于使用。 为了制作一个真实的CRUD方案,我们有一个如下的持久性模型:
- 名称与列名称不同的属性:socialSecurityNumber-> social_security_number
- 日期属性
- 一个ENUM属性
在课堂上有了这个特性,我们将看到一些问题以及框架如何解决它。
Spring JDBC模板
我们可以找到用于访问数据库数据的最著名的框架之一是Spring JDBC模板。 该项目的代码可以在这里找到: https : //github.com/uaihebert/SpringJdbcTemplateCrud
Sprint JDBC模板使用本机查询,如下所示:
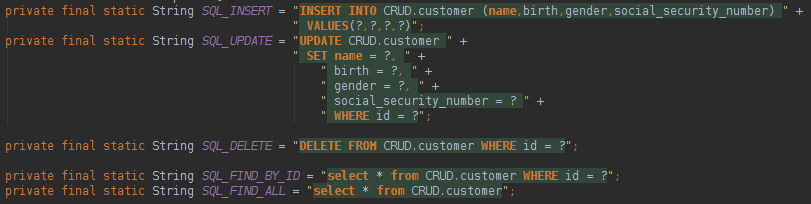
如上图所示,查询具有数据库语法(我将使用MySQL)。 当我们使用本机SQL查询时,可以轻松地使用所有数据库资源。
我们需要一个对象JDBC模板的实例(用于执行查询),并且要创建JDBC模板对象,我们需要设置一个数据源:
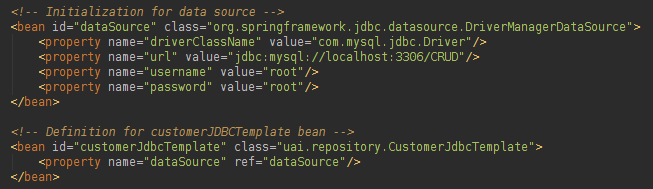
我们现在可以获取数据源(感谢Spring注入)并创建我们的JDBCTemplate:
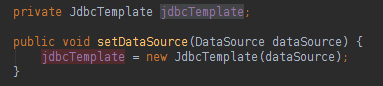
PS .:上面的所有XML代码和JDBCTemplate实例化都可以被Spring注入和代码引导替换,只需对Spring功能进行一些研究即可。 我不喜欢的一件事是ID恢复的INSERT语句,它很冗长:
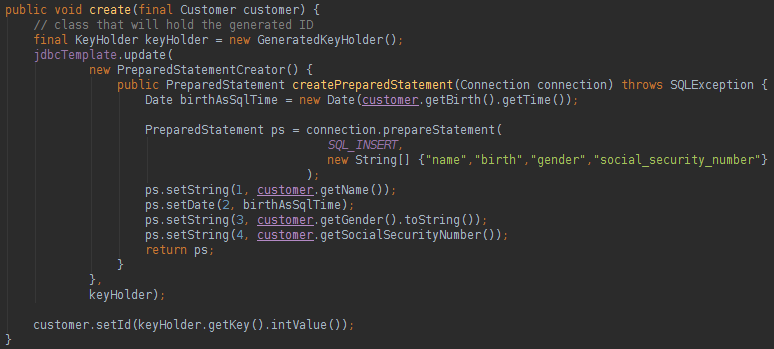
使用KeyHolder类,我们可以在数据库中恢复生成的ID,不幸的是,我们需要大量的代码才能完成此操作。 其他CRUD功能更易于使用,如下所示:
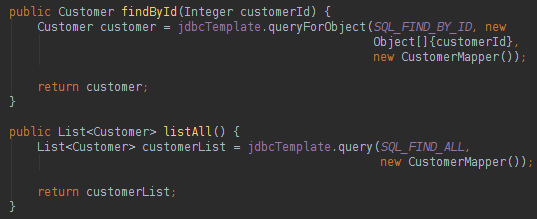
注意,由于使用RowMapper,执行SQL查询非常简单,并且会生成一个填充的对象。 RowMapper是JDBC模板用来简化使用数据库中的数据填充类的引擎 。
看一下下面的RowMapper代码:
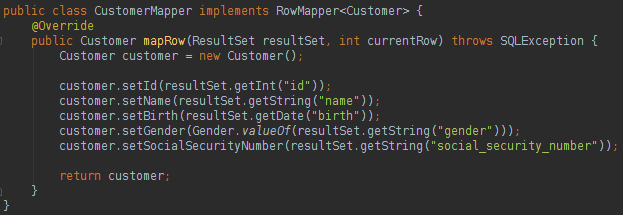
关于RowMapper的最好的消息是它可以在项目的任何查询中使用。 负责编写将填充类数据的逻辑的开发人员。 要完成此页面,请在下面的数据库DELETE和数据库UPDATE语句中查看:

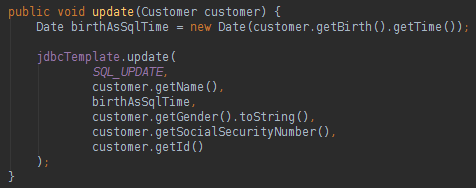
关于Spring JDBC模板,我们可以说:
- 拥有良好的支持 :互联网上的任何搜索都将导致包含提示和错误修复的多个页面。
- 许多公司都在使用它 :全世界有几个项目都在使用它
- 对于同一项目,请小心使用不同的数据库:对于使用不同数据库运行的项目,本机SQL可能会成为问题。 需要重写几个查询以适应所有项目数据库。
- 框架知识 :很好地了解Spring基础知识,如何配置和使用它。
对于那些不知道Spring有几个模块的人,在您的项目中可以仅使用JDBC Template模块。 您可以保留项目的所有其他模块/框架,并仅添加运行JDBC模板所需的模块/框架。
MyBatis
MyBatis(以iBatis名称创建)是一个非常好的框架,许多开发人员都在使用它。 有很多功能,但是我们在这篇文章中只会看到一些。 该页面的代码可以在这里找到: https : //github.com/uaihebert/MyBatisCrud
要使用MyBatis运行项目,您将需要实例化会话工厂。 这很容易,文档说明该工厂可以是静态的:
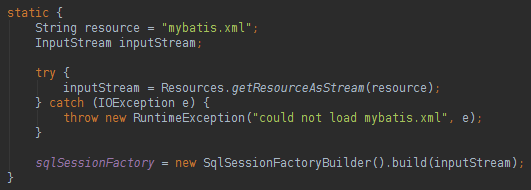
使用MyBatis运行项目时,只需要实例化一次Factory,这就是为什么它使用静态代码的原因。 配置XML(mybatis.xml)非常简单,其代码可以在下面找到:
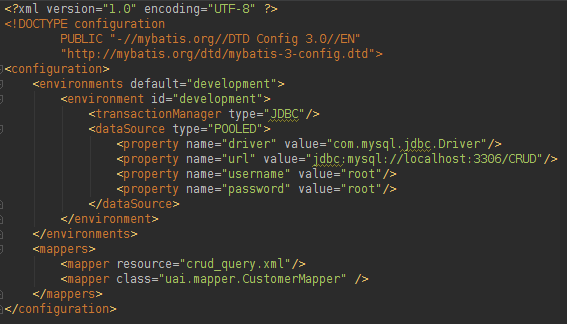
映射器(上面XML中的一个属性)将保存有关项目查询以及如何将数据库结果转换为Java对象的信息。 可以用XML或接口创建映射器。 让我们看下面在文件crud_query.xml中找到的Mapper:
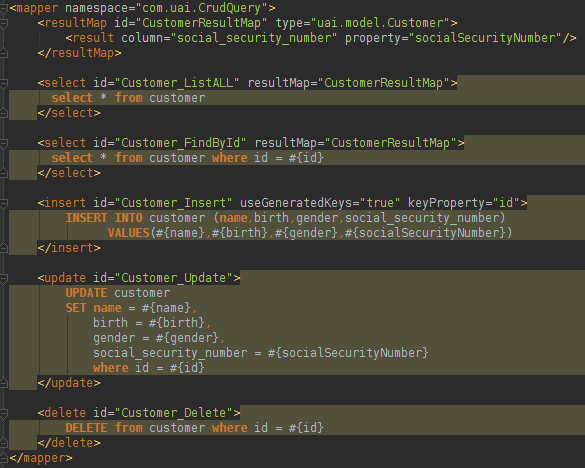
请注意,该文件易于理解。 找到的第一个配置是ResultMap ,它指示查询结果类型,并且结果类已配置为“ uai.model.Customer ”。 在该类中,我们有一个具有与数据库表列不同名称的属性,因此我们需要向ResultMap添加配置。 所有查询都需要一个MyBatis会话将使用的ID。 在文件的开头,可能会看到一个声明的名称空间 ,它作为Java包工作,该包将包装所有查询和XML文件中的ResultMap 。 我们还可以使用Interface + Annotation代替XML。 在crud_query.xml文件中找到的Mapper可以转换为以下接口:
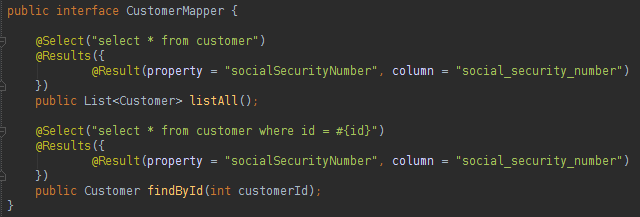
在接口中只编写了Read方法,以使代码更小,但是所有CRUD方法都可以在接口中编写。 首先让我们看看如何执行XML文件中的查询:
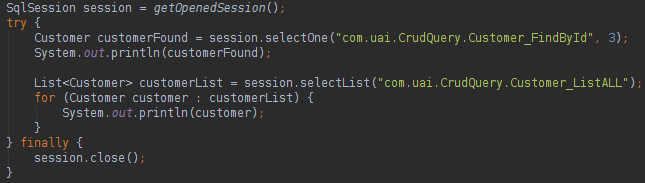
对象的解析是自动的,该方法易于阅读。 要运行查询,只需使用上面在crud_query.xml代码中看到的“ 名称空间+查询ID ”组合。 如果开发人员想要使用接口方法,则可以执行以下操作:
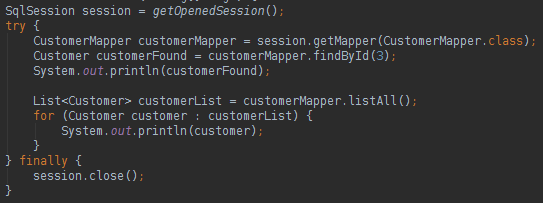
使用接口查询模式,我们可以得到干净的代码,并且开发人员无需实例化Interface,MyBatis的会话类即可完成工作。 如果要更新,删除或在数据库中插入记录,则代码很简单:
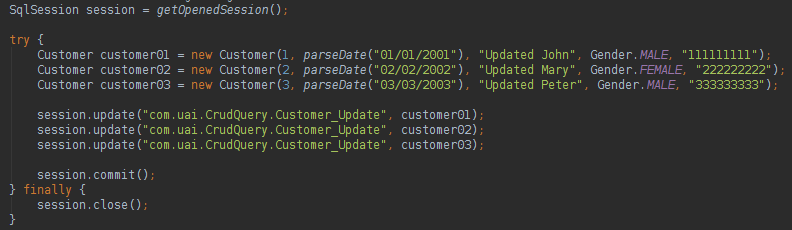
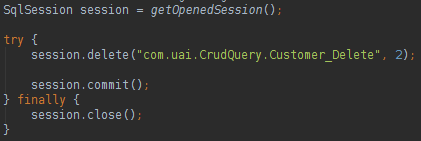
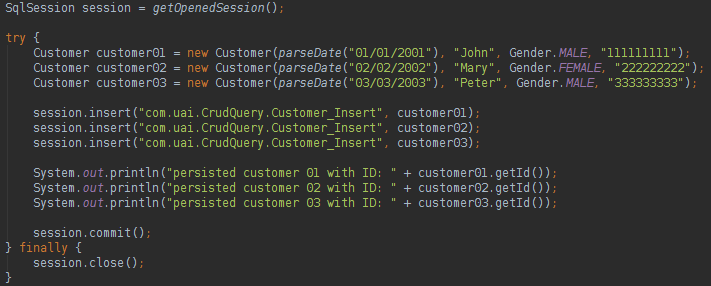
关于MyBatis,我们可以说:
- 优秀的文档 :每当我有疑问时,只要阅读其站点文档就可以回答
- 灵活性 :允许XML或Interfaces + Annotations,该框架为开发人员提供了极大的灵活性。 请注意,如果选择接口方法,数据库的可移植性将更加困难,那么使用部署工件而不是接口来选择要发送的XML更容易。
- 集成 :与Guice和Spring集成
- 动态查询 :允许在运行时中创建查询,例如JPA条件。 可以在查询中添加“ IF”来确定将在查询中使用哪个属性
- 事务 :如果您的项目未使用Spring的Guice,则需要手动控制事务
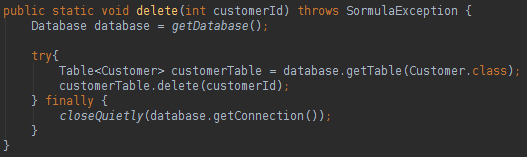
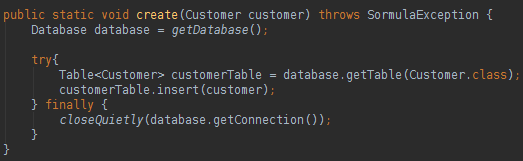
索莫拉
Sormula是一个ORM开源框架,与JPA / Hibernate非常相似。 此页面中的项目代码可在以下位置找到: https : //github.com/uaihebert/SormulaCrud
Sormula有一个名为Database的类,它的工作方式类似于JPA EntityManagerFactory , Database类就像数据库和模型类之间的桥梁。 为了执行SQL动作,我们将使用Table类,该类的工作方式类似于JPA EntityManager ,但是键入了Table类。 要以代码运行Sormula,您将需要创建一个数据库实例:
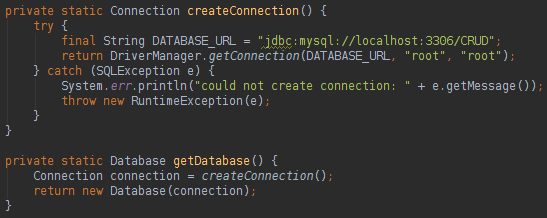
要创建数据库实例,我们需要的是Java连接。 从数据库读取数据非常容易,如下所示:
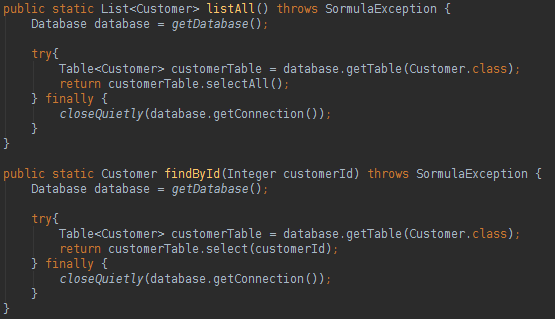
您只需要创建一个数据库实例和一个表实例即可执行各种SQL操作。 我们如何映射与数据库表列名称不同的类属性名称? 看下面:
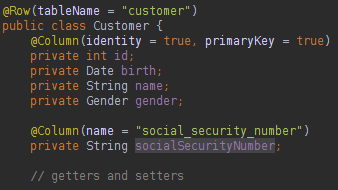
我们可以使用批注在我们的类中进行数据库映射,非常类似于JPA样式。 要更新,删除或创建数据库中的数据,您可以执行以下操作:
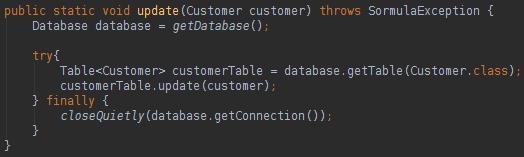
关于Sormula,我们可以这样说:
- 拥有良好的文档
- 易于设置
- 在maven存储库中找不到它,如果需要,它将使附加源代码更加困难
- 有很多检查过的异常,您需要对调用的动作进行try / catch
sql2o
此框架可与本机SQL一起使用,并使将数据库数据转换为Java对象更加容易。 此页面中项目的代码可以在以下位置找到: https : //github.com/uaihebert/sql2oCrud sql2o具有一个非常容易创建的Connection类:
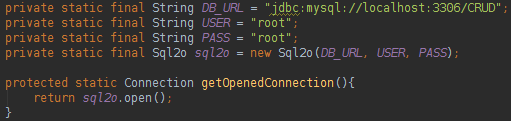
请注意,我们有一个静态Sql2o对象,它将像Connection工厂一样工作。 要读取数据库数据,我们将执行以下操作:
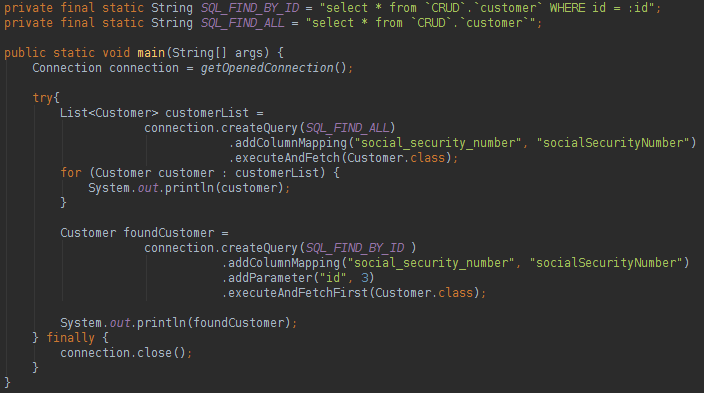
请注意,我们已编写了本机SQL,但已命名参数。 我们没有使用像'?1'这样的位置参数,而是给像':id'这样的参数命名。 可以说,命名参数的优点是我们不会在具有多个参数的查询中迷失; 当我们忘记传递某些参数时,错误消息将告诉我们缺少的参数名称。
我们可以在查询中告知具有不同名称的列的名称,无需创建Mapper / RowMapper。 使用查询中定义的返回类型,我们将不需要手动实例化该对象,sql2o将为我们完成该操作。 如果要更新,删除或在数据库中插入数据,可以执行以下操作:
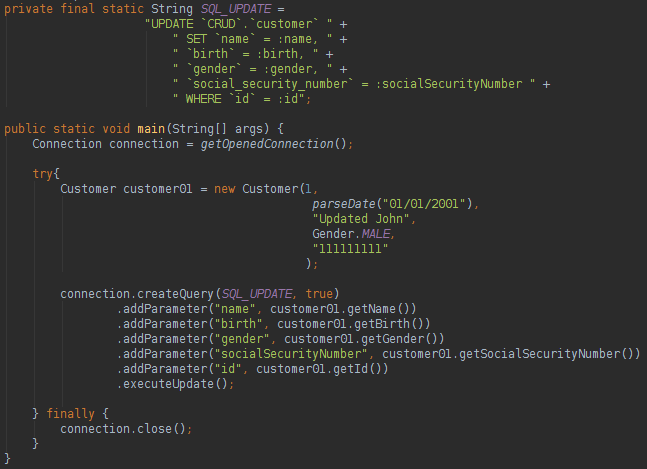
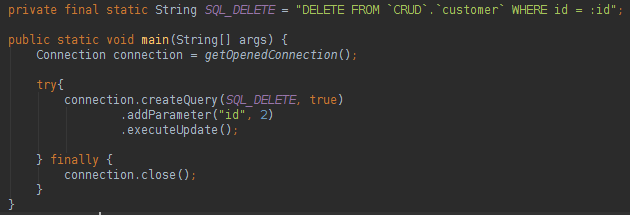
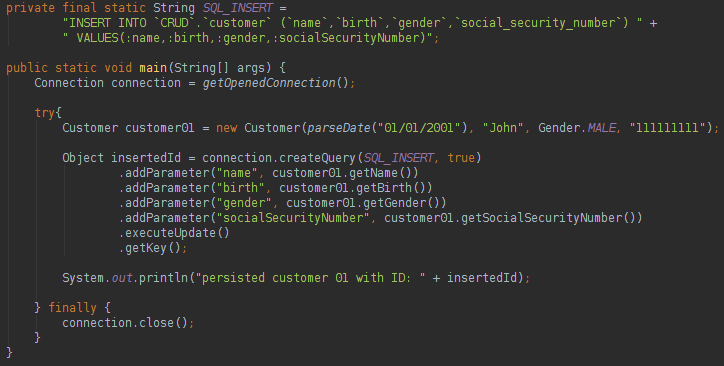
这是一个“非常易于使用”的框架。 关于sql2o,我们可以这样说:
- 易于处理标量查询 :SUM,COUNT函数的返回值易于处理
- 查询中的命名参数 :使用许多参数将易于处理SQL
- 绑定函数 :bind是一个将通过给定对象自动填充数据库查询参数的函数,不幸的是,由于枚举问题,该函数在本项目中不起作用。 我没有调查问题,但是我认为这很容易处理
OO
jOOQ它是一个由很多人指示的框架,该框架的用户在很多站点/论坛中都赞扬它。 不幸的是,jOOQ在我的PC上无法正常工作,因为我的数据库太旧了,写这篇文章时(在飞机上)我无法下载其他数据库。
我注意到,要使用jOOQ,您将需要基于模型生成几个jOOQ类。 jOOQ在站点上有一个很好的文档,其中详细介绍了如何生成这些类。
jOOQ对使用免费数据库(例如:MySQL,Postgre等)的用户免费。对于使用付费数据库(例如,Oracle,SQL Server等)的用户,需要jOOQ付费版本。
阿瓦耶
是几个博客/论坛中引用的框架。 它与ORM概念配合使用,很容易执行数据库CRUD操作。
我发现的问题:
- 没有足够详细的文档 :其Hello World不太详细
- 配置 :它具有必需的属性配置文件,其中包含许多配置,对于那些只想做一个Hello World的人来说确实很无聊
- 需要增强器:增强是一种用于优化类字节码的方法,但是一开始很难设置,并且必须在Hello World之前进行
原始的JDBC方法值得吗?
JDBC的优点是:
- 最佳性能 :在持久层和数据库之间,我们将没有任何框架。 我们可以使用原始JDBC获得最佳性能
- 控制SQL :书面SQL是将在数据库中执行的SQL,没有框架会编辑/更新/生成查询SQL
- 本机资源 :我们可以毫无问题地访问所有本机数据库资源,例如:函数,存储过程,提示等
缺点是:
- 详细代码 :收到数据库查询结果后,我们需要手动实例化并填充对象,并调用所有必需的“设置”方法。 如果我们具有一对多的类关系,则此代码将变得更糟。 在另一片刻内找到片刻很容易。
- 易碎代码 :如果数据库表列更改其名称,则必须编辑使用该列的所有项目查询。 一些项目使用带有列名的常量来完成此任务,例如Customer.NAME_COLUMN ,通过这种方法,表列名的更新会更容易。 如果将列从数据库中删除,即使您具有列常量,所有项目查询都将被更新。
- 复杂的可移植性 :如果您的项目使用多个数据库,则有必要为每个供应商编写几乎所有查询。 对于任何查询中的任何更新,都必须更新每个供应商查询,这可能需要开发人员花费大量时间。
我只能看到一个因素,几乎可以让我立即选择原始的JDBC方法:
- 性能 :如果您的项目需要每分钟处理数千个事务,需要可伸缩且内存使用率低,这是最佳选择。 通常,中型/大型项目具有所有这些高性能要求。 也可以为项目提供混合解决方案。 大多数项目存储库(DAO)将使用框架,而只有一小部分将使用JDBC
我非常喜欢JDBC,我已经工作过并且仍在使用它。 我只是要求您不要认为JDBC是解决每个问题的灵丹妙药。
如果您知道此处未列出的任何其他优点/缺点,请告诉我,我将在此添加您的功劳。
如何选择正确的框架?
如果要为其他项目更改JPA,或者仅在寻找其他持久性框架,我们必须小心。 如果第3页中的解决方案不能解决您的问题,最好的解决方案是更改持久性框架。 在更改持久性框架之前,您应该考虑什么?
- 文档 :该框架是否有据可查? 很容易理解它是如何工作的,它可以回答您的大多数疑问吗?
- 社区 :框架是否具有活跃的用户社区? 有论坛吗?
- 维护/修复错误 :框架是否正在接受提交以修复错误或接受新功能? 是否正在创建修订版本? 哪个频率?
- 寻找一个了解此框架的开发人员有多难 ? 我认为这是要考虑的最重要的问题。 您可以将世界上最好的框架添加到您的项目中,但是如果没有开发人员知道如何操作该框架,那么该框架将毫无用处。 如果您需要聘请高级开发人员,找到一名开发人员会有多难? 如果您紧急需要雇用一个知道未知框架的人员,这可能会非常困难。
最后的想法
我会再说一遍:我不认为JPA可以/不应该应用于世界上每个项目中的每种情况。 我认为JPA像其他任何框架一样都有缺点,因此没有用。
如果您的框架未在此处列出,我不希望您受到冒犯,也许我用来查找持久性框架的研究词汇并未将我引向您的框架。
希望这篇文章对您有所帮助。 如果您有任何重复/问题,请将其发布。 再见!















 810
810

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









