





jvm7 jvm8
即使在今天(2015年),我们仍然有两个版本或Oracle HotSpot JDK –已调整为32或64位体系结构。 问题是我们是否真的想在服务器甚至笔记本电脑上使用32位JVM? 我们应该有很受欢迎的意见! 如果只需要较小的堆,则使用32位–它具有较小的内存占用空间,因此您的应用程序将使用较少的内存并触发较短的GC暂停。 但这是真的吗? 我将探索三个不同的领域:
- 内存占用
- GC性能
- 整体表现
让我们从内存消耗开始。
内存占用
众所周知,32位和64位JVM之间的主要区别与内存寻址有关。 这意味着所有64位版本的引用都占用8个字节而不是4个字节。幸运的是,JVM附带了压缩对象指针 ,默认情况下,所有小于26GB的堆都启用该对象指针 。 只要32位JVM可以寻址2GB左右(对于目标OS而言,它仍然要少13倍左右),那么这个限制对我们来说是可以接受的。 因此,无需担心对象引用。 唯一不同的对象布局是标记标头,它在64位上大4个字节。 我们还知道Java中的所有对象都是8字节对齐的,因此有两种可能的情况:
- 最糟糕的是– 64位对象比32位对象大8个字节。 这是因为向标头添加4个字节会导致对象被放入另一个内存插槽,因此我们必须再添加4个字节来填充对齐间隙。
- 最佳–两个架构上的对象具有相同的大小。 当在32位上有4个字节的对齐间隙时,就会发生这种情况,可以通过其他标记头字节简单地填充它。
现在假设两种不同的应用程序大小来计算这两种情况。 装载了相当大项目的IntelliJ IDEA包含大约700万个对象,这将是我们的较小项目。 对于第二个选项,假设我们有一个大型项目(我称其为“巨大”),其中包含实时集中的5000万个对象。 现在让我们计算最坏的情况:
-
IDEA -> 7 millions * 8 bytes = 53 MB -
Huge -> 50 millions * 8 bytes = 381 MB
上面的计算向我们显示,在最坏的情况下,IntelliJ会增加大约50MB的堆,而对于某些带有很小对象的大型,高度粒度的项目,实际的应用堆会增加大约50MB。 在第二种情况下,它可能占总堆的25%左右,但对于绝大多数项目而言,它约为2%,几乎没有。
GC性能
这个想法是使用长键将800万个String对象放入Cache中。 一个测试包含4个调用,这意味着有2400万次放入缓存映射。 我使用并行GC,将总堆大小设置为2GB。 结果令人惊讶,因为整个测试很快就在32位JDK上完成了。 3分40秒,而64位虚拟机为4分30秒。 比较GC日志后,我们可以看到,差异主要来自GC暂停:114秒到157秒。 这意味着实际上32位JVM带来的GC开销要低得多– 64位554可以暂停到618。 在下面,您可以查看GC Viewer的屏幕截图(两个轴上的缩放比例均相同)
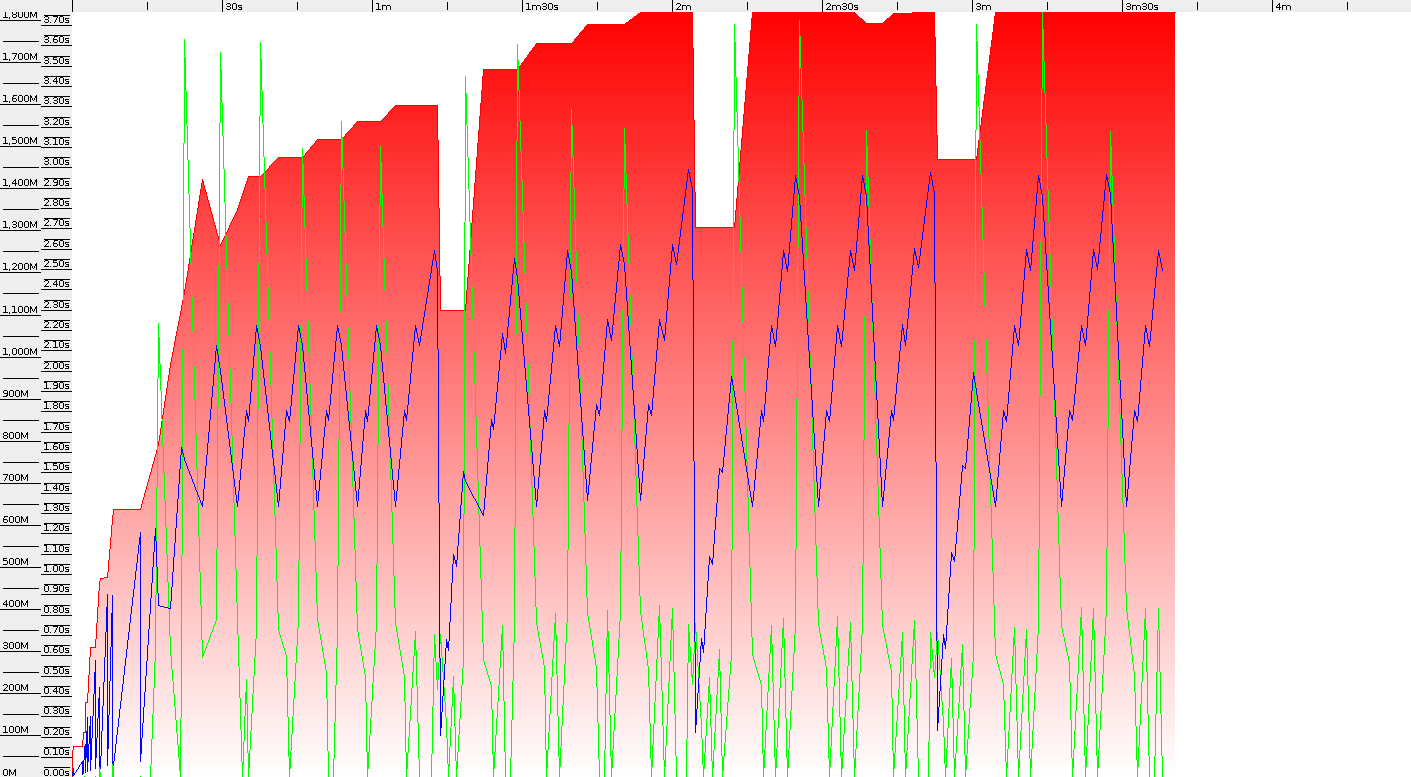
32位JVM并行GC
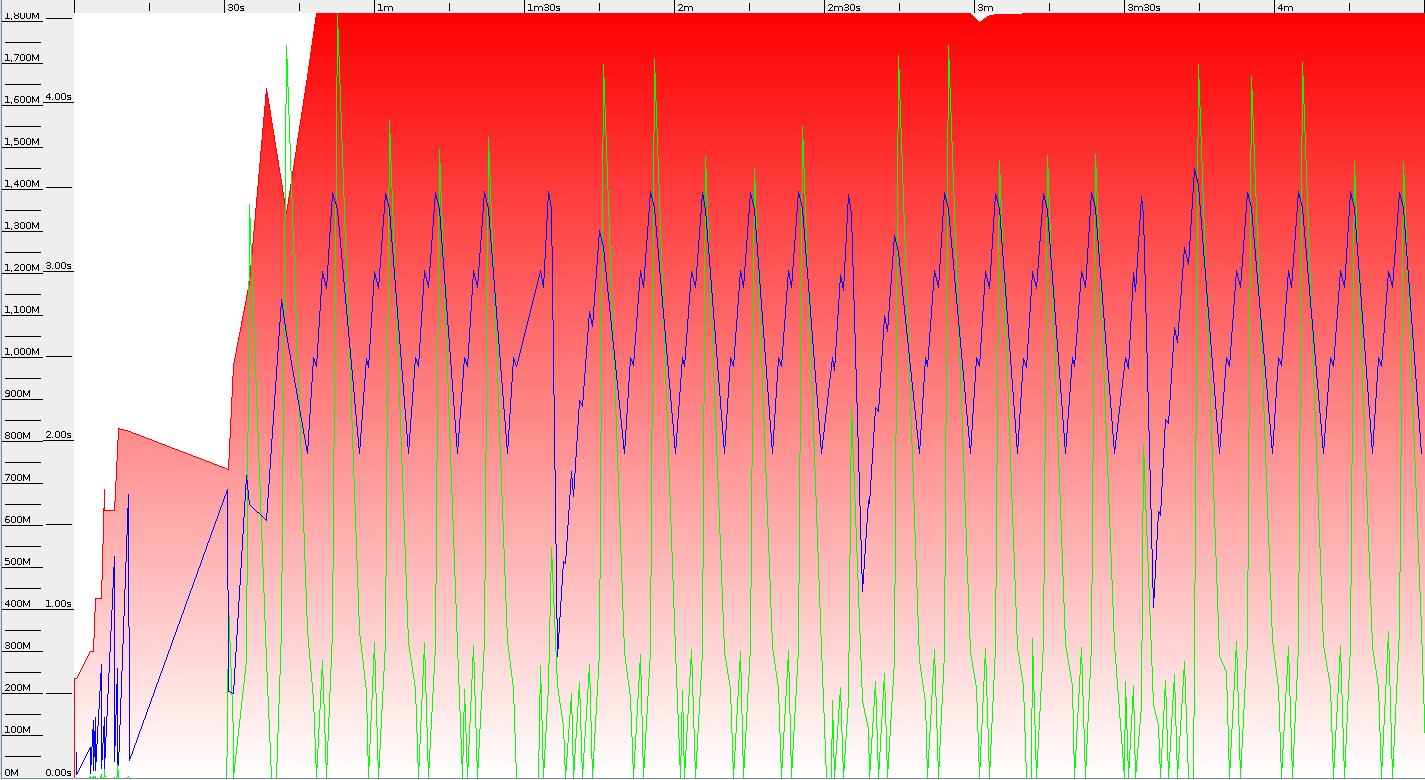
64位JVM并行GC
我原本希望64位JVM的开销较小,但是基准测试表明,即使总堆使用量在32位上也差不多,我们在Full GC上释放了更多的内存。 年轻一代的停顿时间也相似–两种架构的停顿时间均为0.55秒左右。 但是,平均主要停顿在64位上更高,为3.2,而32位上为2.7。 事实证明,小堆的GC性能在32位JDK上要好得多。 问题是您的应用程序对GC的要求是否很高–在测试中,平均吞吐量约为42-48%。
在更多的“企业”场景中进行了第二次测试。 我们正在从数据库加载实体,并在加载的列表上调用size()方法。 对于大约6分钟的总测试时间,对于64位,我们有133.7s的总暂停时间,对于32位,我们有130.0s的总暂停时间。 堆的使用也非常相似– 64位为730MB,32位JVM为688MB。 这向我们显示,对于正常的“企业”用法,在各种JVM架构上的GC性能之间没有太大差异。

从数据库中选择32位JVM并行GC
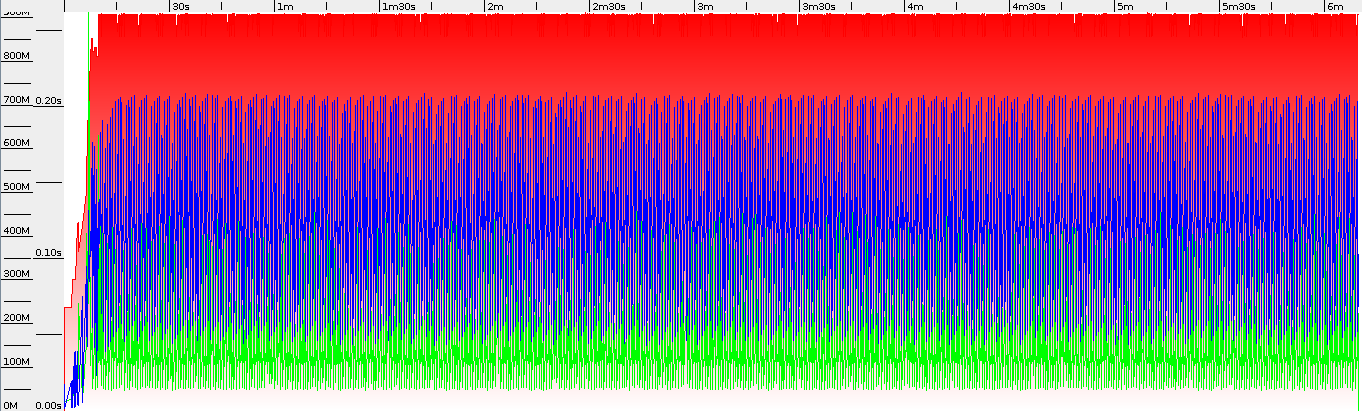
64位JVM并行GC从数据库中选择
即使具有类似的GC性能,32位JVM仍可以在20秒前完成工作(大约5%)。
整体表现
当然,要验证适用于所有应用程序的JVM性能几乎是不可能的,但是我将尝试提供一些有意义的结果。 首先,让我们检查时间性能。
Benchmark 32bits [ns] 64bits [ns] ratio
System.currentTimeMillis() 113.662 22.449 5.08
System.nanoTime() 128.986 20.161 6.40
findMaxIntegerInArray 2780.503 2790.969 1.00
findMaxLongInArray 8289.475 3227.029 2.57
countSinForArray 4966.194 3465.188 1.43
UUID.randomUUID() 3084.681 2867.699 1.08正如我们所看到的,与长变量相关的所有操作的最大且绝对明显的区别是。 在64位JVM上,这些操作的速度是2.6到6.3倍之间。 使用整数非常相似,生成随机UUID的速度也快7%左右。 值得一提的是,解释代码(-Xint)具有相似的速度-仅64位版本的JIT效率更高。 那么有什么特别的区别吗? 是! 64位体系结构带有JVM使用的其他处理器寄存器。 检查生成的程序集后,看起来性能提升主要来自使用64位寄存器的可能性,这可以简化长时间的操作。 可以在Wiki页面下找到任何其他更改。 如果要在计算机上运行此程序,则可以在我的GitHub上找到所有基准测试– https://github.com/jkubrynski/benchmarks_arch
结论
在整个IT世界中,我们不能简单地回答-“是的,您应该始终使用** bits JVM”。 这在很大程度上取决于您的应用程序特征。 如我们所见,32位和64位体系结构之间存在许多差异。 即使长期相关操作的JIT性能提高了几百个百分点,我们也可以看到,经过测试的批处理过程在32位JVM上更早完成。 结论–没有简单的答案。 您应该始终检查哪种架构更适合您的要求。
非常感谢Wojtek Kudla审阅本文并执行其他测试:)
翻译自: https://www.javacodegeeks.com/2015/05/do-we-really-still-need-a-32-bit-jvm.html
jvm7 jvm8















 573
573

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









