





hazelcast
如果要使用Hazelcast内存数据网格(IMDG)来加快数据库应用程序的速度,但是要处理数百个表怎么办? 手动编码所有Java POJO和序列化支持将需要数周的工作,完成后,手动维护该域模型将很快成为一场噩梦。 阅读本文,了解如何节省时间并在5分钟内完成。
现在,有一种优雅的方法可以管理这些需求。 Hazelcast自动数据库集成工具允许连接到现有数据库,该数据库可以自动生成所有这些样板类。 我们获得了真正的POJO,序列化支持,配置,MapStore / MapLoad,摄取等,而无需编写任何手动代码。 另外,我们还为Hazelcast分布式地图提供了Java Stream支持。
使用工具
让我们尝试一个例子。 就像我的许多文章一样,我将使用Sakila开源示例数据库。 它可以下载为文件或Docker实例 。 Sakila包含16个表,这些表中共有90列。 它还包括带有其他列的七个视图。
首先,我们使用Hazelcast Auto DB Integration Initializer和试用许可证密钥。
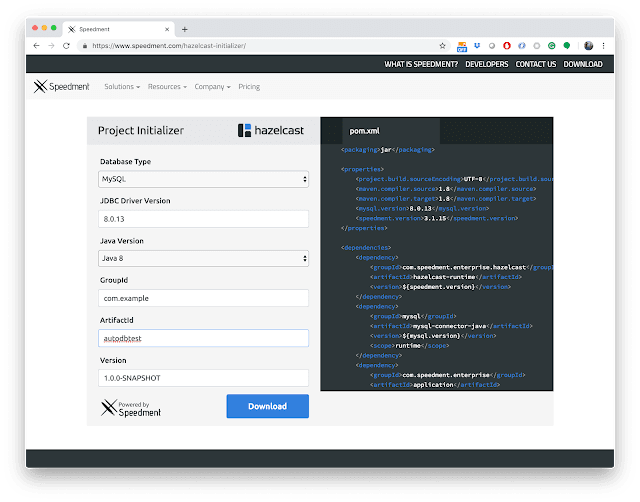
填写上面显示的值,然后按“下载”,您的项目将保存到计算机中。 然后,按照下一页的说明说明如何解压缩,启动该工具并获得试用许可证。
接下来,我们连接到数据库:
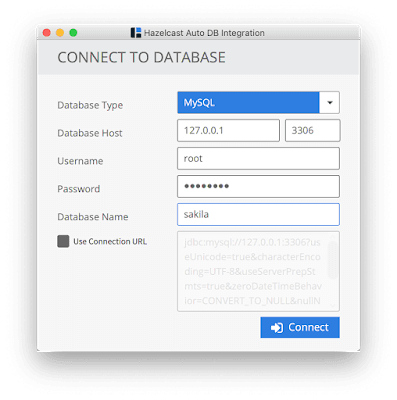
该工具现在将分析架构元数据,然后在另一个窗口中可视化数据库架构:
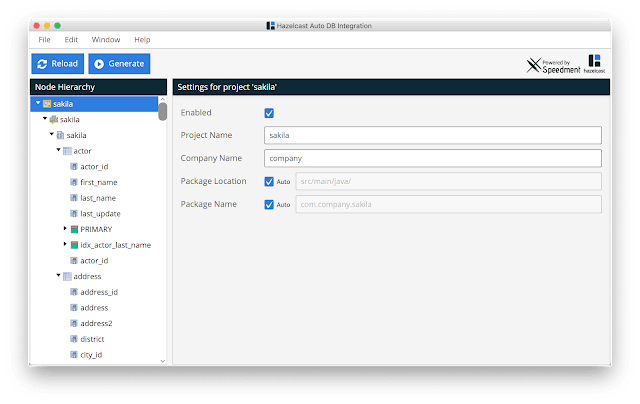
只需按下“生成”按钮,完整的Hazelcast域模型将在2或3秒钟内自动生成。
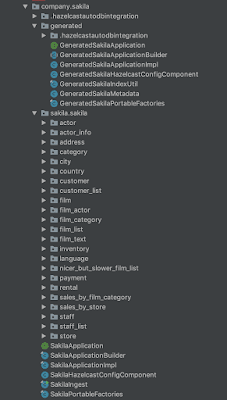
现在,我们几乎可以编写我们的Hazelcast IMDG应用程序了。 我们需要创建一个Hazelcast IMDG以首先存储实际数据。
建筑
这是架构与应用程序与Hazelcast IMDG进行通信时的样子,Hazelcast IMDG又从底层数据库获取数据:
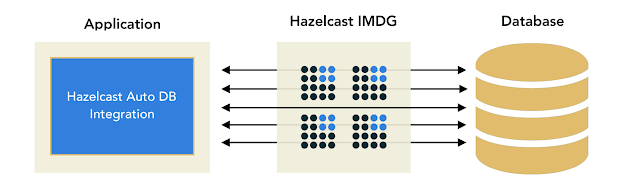
该工具生成的代码仅需要出现在应用程序中,而无需出现在Hazelcast IMDG中。
创建Hazelcast IMDG
创建Hazelcast IMDG很容易。 将以下依赖项添加到pom.xml文件:
<dependency>
<groupId>com.hazelcast</groupId>
<artifactId>hazelcast</artifactId>
<version>3.11</version>
</dependency>然后,将以下类复制到您的项目中:
public class Server {
public static void main(String... args) throws InterruptedException {
final HazelcastInstance instance = Hazelcast.newHazelcastInstance();
while (true) {
Thread.sleep(1000);
}
}
}重复运行此主要方法3次,以在群集中创建三个Hazelcast节点。 较新版本的IDEA要求在“运行/调试配置”中启用“允许并行运行”。 如果只运行一次,也可以。 即使我们的集群中只有一个节点,下面的示例仍然可以使用。
运行主要方法树时间将产生以下内容:
Members {size:3, ver:3} [
Member [172.16.9.72]:5701 - d80bfa53-61d3-4581-afd5-8df36aec5bc0
Member [172.16.9.72]:5702 - ee312d87-abe6-4ba8-9525-c4c83d6d99b7
Member [172.16.9.72]:5703 - 71105c36-1de8-48d8-80eb-7941cc6948b4 this
]真好! 我们的三节点集群已启动并正在运行!
数据提取
在运行任何业务逻辑之前,我们需要将数据库中的数据提取到新创建的Hazelcast IMDG中。 幸运的是,该工具也为我们完成了此任务。 找到名为SakilaIngest的生成的类,并使用数据库密码作为第一个命令行参数运行它,或修改代码以使其知道密码。 这就是生成的类的样子。
public final class SakilaIngest {
public static void main(final String... argv) {
if (argv.length == 0) {
System.out.println("Usage: " + SakilaIngest.class.getSimpleName() + " database_password");
} else {
try (Speedment app = new SakilaApplicationBuilder()
.withPassword(argv[0]) // Get the password from the first command line parameter
.withBundle(HazelcastBundle.class)
.build()) {
IngestUtil.ingest(app).join();
}
}
}
}运行时,将显示以下输出(为简便起见,以下简称):
...
Completed 599 row(s) ingest of data for Hazelcast Map sakila.sakila.customer_list
Completed 2 row(s) ingest of data for Hazelcast Map sakila.sakila.sales_by_store
Completed 16,049 row(s) ingest of data for Hazelcast Map sakila.sakila.payment
Completed 16,044 row(s) ingest of data for Hazelcast Map sakila.sakila.rental
Completed 200 row(s) ingest of data for Hazelcast Map sakila.sakila.actor_info现在,我们从Hazelcast IMDG中获得了数据库中的所有数据。 真好!
你好,世界
既然我们的网格已经生效并且已经提取了数据,我们就可以访问填充的Hazelcast地图。 这是一个程序,该程序使用Map界面将所有长度大于一小时的影片打印到控制台:
public static void main(final String... argv) {
try (Speedment app = new SakilaApplicationBuilder()
.withPassword("your-db-password-goes-here")
.withBundle(HazelcastBundle.class)
.build()) {
HazelcastInstance hazelcast = app.getOrThrow(HazelcastInstanceComponent.class).get();
IMap<Integer, Film> filmMap = hazelcast.getMap("sakila.sakila.film");
filmMap.forEach((k, v) -> {
if (v.getLength().orElse(0) > 60) {
System.out.println(v);
}
});
}
} 电影长度是一个可选变量(即,在数据库中可以为空),因此它会自动映射到OptionalLong 。 可以将此行为设置为“ legacy POJO”,如果在手头的项目中需要返回null,则返回null。
该工具还有一个附加功能:我们获得Java Stream支持! 因此,我们可以编写如下相同的功能:
public static void main(final String... argv) {
try (Speedment app = new SakilaApplicationBuilder()
.withPassword("your-db-password-goes-here")
.withBundle(HazelcastBundle.class)
.build()) {
FilmManager films = app.getOrThrow(FilmManager.class);
films.stream()
.filter(Film.LENGTH.greaterThan(60))
.forEach(System.out::println);
}引擎盖下
该工具生成实现Hazelcast的“便携式”序列化支持的POJO。 这意味着可以使用多种语言(例如Java,Go,C#,JavaScript等)编写的应用程序访问网格中的数据。
该工具生成以下Hazelcast类:
POJO
每个实现可移植接口的表/视图一个。
序列化工厂
每个模式一个。 从客户端中的IMDG反序列化数据时,需要有效地创建可移植POJO。
MapStore / MapLoad
每个表/视图一个。 IMDG可使用这些类直接从数据库加载数据。
类定义
每个表/视图一个。 这些类用于配置。
索引效用法
每个项目一个。 这可用于基于数据库索引来改进IMDG的索引。
配置支持
每个项目一个。 创建序列化工厂,类定义和某些性能设置的自动配置。
摄取支持
每个项目一个。 用于将数据从数据库吸收到Hazelcast IMDG中的模板。
该工具还包含其他功能,例如对Hazelcast Cloud的支持和Java Stream支持。
一个特别吸引人的特性是域模型(例如POJO和序列化器)不需要位于服务器的类路径上。 它们只需要位于客户端的类路径上。 这极大地简化了网格的设置和管理。 例如,如果您需要更多节点,请添加一个新的通用网格节点,它将加入集群并开始直接参与。
淡褐色云
可以使用应用程序构建器轻松配置与Hazelcast Cloud实例的连接,如以下示例所示:
Speedment hazelcastApp = new SakilaApplicationBuilder()
.withPassword(“<db-password>")
.withBundle(HazelcastBundle.class)
.withComponent(HazelcastCloudConfig.class,
() -> HazelcastCloudConfig.create(
"<name of cluster>",
"<cluster password>",
"<discovery token>"
)
)
.build();积蓄
我估计该工具仅为较小的示例Sakila数据库节省了几个小时(如果不是几天的话)的样板代码。 在具有数百个表的企业级项目中,该工具将在开发和维护方面节省大量时间。
既然您已经学会了如何为第一个示例项目创建代码并设置了所有必要的工具,那么我相信您可以在5分钟内为任何Hazelcast数据库项目生成代码。
资源资源
Sakila: https ://dev.mysql.com/doc/index-other.html或https://hub.docker.com/r/restsql/mysql-sakila
初始化程序: https : //www.speedment.com/hazelcast-initializer/
手册: https : //speedment.github.io/speedment-doc/hazelcast.html
翻译自: https://www.javacodegeeks.com/2019/05/java-become-productive-hazelcast.html
hazelcast


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









