





corda
如何使流程更快? 如果您与Corda合作已有一段时间,那么您很有可能已经考虑过这一点。 您可以通过以下几方面进行合理的调整以提高性能:事务大小,优化查询并减少整个Flow执行过程中所需的网络跃点数。 在某种程度上,还有另一种可能也使您着迷。 多线程。
更具体地说,从已经执行的流程异步启动流程/子流程。 这样做有可能极大地改善您的CorDapps性能。

如果您尝试此操作,则可能会遇到与我得到的类似的例外。 此外,到目前为止,Corda还不支持子流的线程化。 但是,仍然可以做到。 我们只需要对此保持聪明。 那就是Corda Services中多线程进入的地方。它们可以在Flow中调用,但不会妨碍Flow对其施加的严格规则,因为正在执行的Flow不会从服务中挂起或检查点。
在本文中,我将重点介绍从服务内部以多线程方式启动流程。 在Corda中还可以使用其他线程,但这是我想深入研究的有趣领域。 另一方面,从服务启动流也充满了一些陷阱。 这些需要考虑并遍历。 否则,您将有一天醒来,想知道为什么一切都没有明显的原因停止了。
幸运的是,我在这里为您提供帮助。 对我来说,嗯,我不得不直面这个问题。
对我来说幸运的是,R3能够提供帮助。
作为参考,我将在本文中使用Corda Enterprise 3.1 。 要从本文的内容中真正受益,您将需要使用Enterprise。 这是由于Enterprise支持多个异步执行的流。 开源目前不允许这样做。
我还建议您查看我以前的文章Corda Services 101,因为我们将在此基础上建立基础。
情境
让我们首先概述一下本文将要使用的场景。
- 随着时间的推移,甲方向甲方发送一些消息。 每个消息来自一个流。
- 甲方回应发送给他们的所有消息。 每个消息都来自单个Flow,但是它们希望在单个位置执行该过程。
可以快速组合一系列流程来满足此要求。 按顺序执行此操作应该证明绝对是零问题(在纠正了我们所有犯下的愚蠢错误之后)。
尽管这种情况对于需要性能的情况来说是一个很差的情况,但是它很容易理解,因此我们可以专注于异步运行。
慢速同步解决方案
在研究异步解决方案之前,快速浏览一下将要使用的代码将是有益的。 下面是ReplyToMessagesFlow的代码。 我不想遍历所有底层代码,而只想专注于与此帖子相关的代码:
@InitiatingFlow
@StartableByRPC
class ReplyToMessagesFlow : FlowLogic<List>() {
@Suspendable
override fun call(): List {
return messages().map { reply(it) }
}
private fun messages() =
repository().findAll(PageSpecification(1, 100))
.states
.filter { it.state.data.recipient == ourIdentity }
private fun repository() = serviceHub.cordaService(MessageRepository::class.java)
@Suspendable
private fun reply(message: StateAndRef) = subFlow(SendMessageFlow(response(message), message))
private fun response(message: StateAndRef): MessageState {
val state = message.state.data
return state.copy(
contents = "Thanks for your message: ${state.contents}",
recipient = state.sender,
sender = state.recipient
)
}
} 如果您确实阅读过Corda Services 101,那么您可能已经认识到此类。 正如我之前提到的,为提出的问题组合解决方案非常容易。 从Vault检索MessageState ,然后启动子subFlow以subFlow进行回复。
这段代码将愉快地逐个传递消息。
那么,我们可以采用此代码并使其更快吗?
异步尝试失败
让我们尝试通过引入线程来使当前代码更快! 我们将使用CompletableFutures来做到这一点:
@InitiatingFlow
@StartableByRPC
class ReplyToMessagesBrokenAsyncFlow : FlowLogic<List>() {
@Suspendable
override fun call(): List {
return messages().map { CompletableFuture.supplyAsync { reply(it) }.join() }
}
// everything else is the same as before
}大多数代码与以前相同,因此已从示例中排除。
对代码的唯一更改是添加了CompletableFuture及其supplyAsync方法(来自Java)。 它尝试在单独的线程上开始为每个消息执行reply功能。
那么为什么将本节命名为“一次失败的尝试”? 我引用您执行以上代码时获得的堆栈跟踪:
java.util.concurrent.CompletionException: java.lang.IllegalArgumentException: Required value was null.
at java.util.concurrent.CompletableFuture.encodeThrowable(CompletableFuture.java:273) ~[?:1.8.0_172]
at java.util.concurrent.CompletableFuture.completeThrowable(CompletableFuture.java:280) ~[?:1.8.0_172]
at java.util.concurrent.CompletableFuture$AsyncSupply.run(CompletableFuture.java:1592) ~[?:1.8.0_172]
at java.util.concurrent.CompletableFuture$AsyncSupply.exec(CompletableFuture.java:1582) ~[?:1.8.0_172]
at java.util.concurrent.ForkJoinTask.doExec(ForkJoinTask.java:289) ~[?:1.8.0_172]
at java.util.concurrent.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1056) ~[?:1.8.0_172]
at java.util.concurrent.ForkJoinPool.runWorker(ForkJoinPool.java:1692) ~[?:1.8.0_172]
at java.util.concurrent.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:157) ~[?:1.8.0_172]
Caused by: java.lang.IllegalArgumentException: Required value was null.
at net.corda.node.services.statemachine.FlowStateMachineImpl.checkDbTransaction(FlowStateMachineImpl.kt:201) ~[corda-node-3.1.jar:?]
at net.corda.node.services.statemachine.FlowStateMachineImpl.processEventImmediately(FlowStateMachineImpl.kt:192) ~[corda-node-3.1.jar:?]
at net.corda.node.services.statemachine.FlowStateMachineImpl.subFlow(FlowStateMachineImpl.kt:271) ~[corda-node-3.1.jar:?]
at net.corda.core.flows.FlowLogic.subFlow(FlowLogic.kt:312) ~[corda-core-3.1.jar:?]
at com.lankydanblog.tutorial.flows.ReplyToMessagesBrokenAsyncFlow.reply(ReplyToMessagesBrokenAsyncFlow.kt:57) ~[classes/:?]
at com.lankydanblog.tutorial.flows.ReplyToMessagesBrokenAsyncFlow.access$reply(ReplyToMessagesBrokenAsyncFlow.kt:19) ~[classes/:?]
at com.lankydanblog.tutorial.flows.ReplyToMessagesBrokenAsyncFlow$poop$$inlined$map$lambda$1.get(ReplyToMessagesBrokenAsyncFlow.kt:46) ~[classes/:?]
at com.lankydanblog.tutorial.flows.ReplyToMessagesBrokenAsyncFlow$poop$$inlined$map$lambda$1.get(ReplyToMessagesBrokenAsyncFlow.kt:19) ~[classes/:?] 您将获得它,以及Corda正在打印的一长串检查点日志行。 此外,只是为了掩盖我的屁股,并向您证明这不是由于CompletableFuture的问题引起的,这是使用Executor线程池时出现的另一个错误:
Exception in thread "pool-29-thread-1" Exception in thread "pool-29-thread-2" java.lang.IllegalArgumentException: Required value was null.
at net.corda.node.services.statemachine.FlowStateMachineImpl.checkDbTransaction(FlowStateMachineImpl.kt:201)
at net.corda.node.services.statemachine.FlowStateMachineImpl.processEventImmediately(FlowStateMachineImpl.kt:192)
at net.corda.node.services.statemachine.FlowStateMachineImpl.subFlow(FlowStateMachineImpl.kt:271)
at net.corda.core.flows.FlowLogic.subFlow(FlowLogic.kt:312)
at com.lankydanblog.tutorial.flows.ReplyToMessagesBrokenAsyncFlow.reply(ReplyToMessagesBrokenAsyncFlow.kt:48)
at com.lankydanblog.tutorial.flows.ReplyToMessagesBrokenAsyncFlow.access$reply(ReplyToMessagesBrokenAsyncFlow.kt:19)
at com.lankydanblog.tutorial.flows.ReplyToMessagesBrokenAsyncFlow$call$$inlined$map$lambda$1.run(ReplyToMessagesBrokenAsyncFlow.kt:29)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
java.lang.IllegalArgumentException: Required value was null.
at net.corda.node.services.statemachine.FlowStateMachineImpl.checkDbTransaction(FlowStateMachineImpl.kt:201)
at net.corda.node.services.statemachine.FlowStateMachineImpl.processEventImmediately(FlowStateMachineImpl.kt:192)
at net.corda.node.services.statemachine.FlowStateMachineImpl.subFlow(FlowStateMachineImpl.kt:271)
at net.corda.core.flows.FlowLogic.subFlow(FlowLogic.kt:312)
at com.lankydanblog.tutorial.flows.ReplyToMessagesBrokenAsyncFlow.reply(ReplyToMessagesBrokenAsyncFlow.kt:48)
at com.lankydanblog.tutorial.flows.ReplyToMessagesBrokenAsyncFlow.access$reply(ReplyToMessagesBrokenAsyncFlow.kt:19)
at com.lankydanblog.tutorial.flows.ReplyToMessagesBrokenAsyncFlow$call$$inlined$map$lambda$1.run(ReplyToMessagesBrokenAsyncFlow.kt:29)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)希望您在这一点上相信我。 如果不是,请参考我一开始所说的内容。 Corda当前不支持从正在执行的流程异步启动新流程。 我相信他们正在努力。 但是,截至目前。 不要使用此解决方案。
可行的异步解决方案
我们已经看到,在Flow内部执行线程是行不通的。 为了继续追求性能,我们现在来看一下Corda服务中的线程。 这并不奇怪,因为标题和开头的段落已经讨论了这一点……
抛开讽刺的评论。 委派服务将需要对原始解决方案进行一些重做,但是大部分代码将保持不变。 大部分内容将被复制并粘贴到另一个类中。 从流中获取代码并将其放入服务中。
以下是新的MessageService ,其中包含原始ReplyToMessagesFlow的代码,但进行了一些更改和添加了线程代码:
@CordaService
class MessageService(private val serviceHub: AppServiceHub) : SingletonSerializeAsToken() {
private companion object {
val executor: Executor = Executors.newFixedThreadPool(8)!!
}
fun replyAll() {
messages().map {
executor.execute {
reply(it)
}
}
}
private fun messages() =
repository().findAll(PageSpecification(1, 100))
.states
.filter { it.state.data.recipient == serviceHub.myInfo.legalIdentities.first() }
private fun repository() = serviceHub.cordaService(MessageRepository::class.java)
private fun reply(message: StateAndRef) =
serviceHub.startFlow(SendMessageFlow(response(message), message))
private fun response(message: StateAndRef): MessageState {
val state = message.state.data
return state.copy(
contents = "Thanks for your message: ${state.contents}",
recipient = state.sender,
sender = state.recipient
)
}
} 如您所见,大多数代码与ReplyToMessagesFlow中的代码相同。
我要强调的第一点是使用Executor线程池。 我之所以没有在这里使用CompletableFutures ,是因为稍后我们将对其进行研究。
那么,这一切如何运作? replyAll函数在新的系统线程上对从Vault检索到的每条消息执行reply 。 这个新线程又调用startFlow 。 触发将新的流程放入“流程工作器”队列中。 这是所有乐趣发生的地方,一切开始变得混乱。
Flow Worker队列负责执行Flow的执行顺序,并随着Flow的添加和完成而填充并为空。 该队列对于协调节点内流的执行至关重要。 当涉及到多线程Flows本身时,它也是痛苦的根源。
下图显示了队列的简化视图:
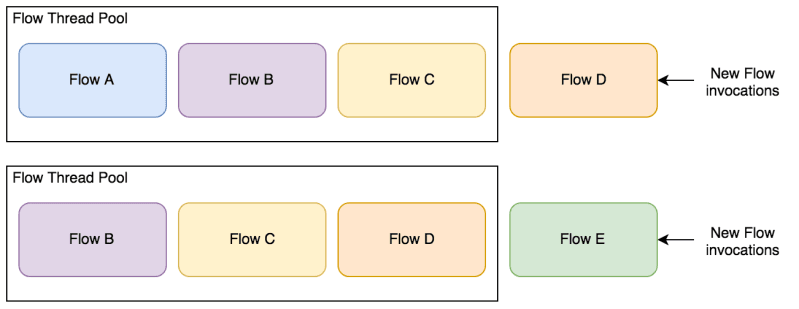
流进入队列并在处理后离开
我为什么要谈论这个队列? 好吧,我们需要格外小心,不要将无法完成的流程填满队列。
怎么会这样 通过在正在执行的流程中启动流程,然后流程等待其完成。 直到队列的线程池中的所有线程都遇到这种情况,这才不会引起问题。 一旦发生,它将使队列陷入僵局。 没有流程可以完成,因为它们都依赖于许多排队的流程来完成。

流留在队列中,等待它们调用的流完成
这种情况最有可能发生在多次触发相同流量的高吞吐量系统上。 现在,队列中充满了等待其他流完成的机会。
这不是很好,使事情变得有点困难。 但是,只要我们意识到这一点,我们就可以适应它。
这也是Executor线程池而不是CompletableFuture的原因。 通过启动新的流程而不等待其完成,可以避免死锁。 这也是该解决方案的缺点。 没有新Flow的结果,其功能将极为有限。
话虽如此,如果您的用例适合上面显示的结构,那么我绝对建议您使用此解决方案。
在下一节中,我将讨论使用CompletableFuture 。
CompletableFutures的危险解决方案
这很危险的原因很简单。 僵局。 我建议不要使用此解决方案。 除非您的节点有权访问足够的线程,否则要减少用无法完成的线程填充队列的机会。 另一方面,这是一个更为理想的解决方案,因为您可以等待启动的流程的结果并对其进行处理。 这使解决方案更加有用。
以下是带有CompletableFutures的MessageService外观:
@CordaService
class MessageService(private val serviceHub: AppServiceHub) : SingletonSerializeAsToken() {
fun replyAll(): List =
messages().map { reply(it).returnValue.toCompletableFuture().join() }
// everything else is the same as before
} 除replyAll函数外,代码replyAll 。 返回的CordaFuture提供的toCompletableFuture函数,调用join以等待所有期货的结果并返回总体结果。
如前所述,该解决方案可能导致死锁。 但是,对于您的情况,也许并非如此。 由您决定发生这种情况的可能性。 如果不利于您,最好走开。 选择坚持使用同步或异步解决方案,类似于我在上一节中详细介绍的解决方案。
我真的需要这样做吗?
现在,是的,我相信你会的。
展望未来,我怀疑您是否需要依靠我在本文中提出的解决方案。
我相信Corda正在努力消除从Flow内部启动Flow时甚至不必考虑线程的需求。 取而代之的是,您可以简单地调用subFlow并带有一个选项以使其异步运行。 这将使我们能够保留原始的同步解决方案,但可以选择使每个subFlow在单独的线程上运行。
将各部分结合在一起
总之,在Corda Enterprise 3中,可以在正在执行的Flow中异步启动新的Flow。 根据您的用例,这可以提供良好的性能优势。 有缺点。 您不能等待异步流的结果,而不会用死锁的威胁来威胁您的节点。 节点的基础队列无法处理它所处的情况。因此,您需要注意如何将线程引入Flow调用。 值得庆幸的是,随着Corda的发展,您甚至根本不必担心自己这样做。 它甚至可能像添加布尔函数参数一样简单。 那是梦想!
这篇文章中使用的代码可以在我的GitHub上找到 。
如果您发现此帖子有帮助,可以在Twitter上@LankyDanDev关注我,以了解我的新帖子。
翻译自: https://www.javacodegeeks.com/2018/09/asynchronous-flow-invocations-corda-services.html
corda















 427
427

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









