






java批处理 异常处理
在当今世界,互联网已经改变了我们的生活方式,其主要原因之一是大部分日常琐事都使用互联网。 这导致大量数据可用于处理。
其中涉及大量数据的一些示例是处理工资单,银行对帐单,利息计算等。因此,想象一下,如果所有这些工作都必须手动完成,那么完成这些工作将花费很多时间。
在目前的年龄如何? 答案是批处理。
1.简介
批处理是对批量数据执行的,无需人工干预,并且可以长时间运行。 它可能是数据或计算密集型的。 批处理作业可以按预定义的时间表运行,也可以按需启动。 此外,由于批处理作业通常是长时间运行的作业,因此在批处理作业中发现经常检查和从特定故障中重新启动是常见的功能。
1.1 Java批处理的历史
Java平台的批处理是作为JSR 352规范(Java EE 7平台的一部分)引入的,它定义了批处理应用程序的编程模型以及用于运行和管理批处理作业的运行时。
1.2 Java Batch的体系结构
下图显示了批处理的基本组件。
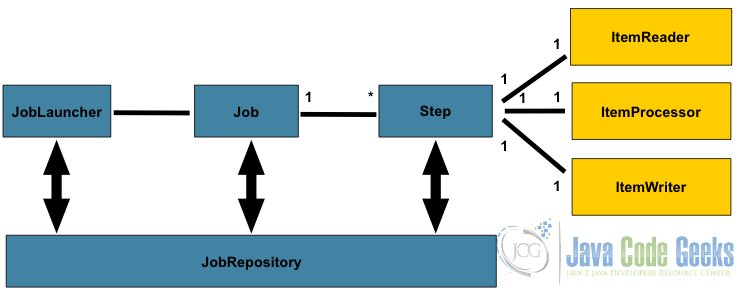
Java批处理的体系结构
批处理应用程序的体系结构解决了批处理问题,例如作业,步骤,存储库,读取器处理器编写器模式,块,检查点,并行处理,流,重试,排序,分区等。
让我们了解架构的流程。
- 作业存储库包含需要运行的作业。
-
JobLauncher从Job存储库中提取一个作业。 - 每个工作都包含步骤。 这些步骤是
ItemReader,ItemProcessor和ItemWriter。 - Item Reader是读取数据的工具。
- 项目处理是一种将基于业务逻辑处理数据的处理。
- 条目编写器会将数据写回到定义的源。
1.3批处理组件。
现在,我们将尝试详细了解批处理组件。
- 作业:作业包含整个批处理过程。 它包含一个或多个步骤。 使用作业指定语言(JSL)将作业放在一起,该语言指定必须执行步骤的顺序。 在JSR 352中,JSL在称为作业XML文件的XML文件中指定。 一项工作基本上就是一个存放步骤的容器。
- 步骤:步骤是一个域对象,它包含作业的一个独立的顺序阶段。 步骤包含执行实际处理所需的所有必要逻辑和数据。 根据批处理规范,步骤的定义含糊不清,因为步骤的内容纯粹是特定于应用程序的,并且可以像开发人员所希望的那样复杂或简单。 有两种步骤: 面向块和面向任务 。
- 作业操作员:它提供了一个界面来管理作业处理的各个方面,其中包括操作命令,例如开始,重新启动和停止,以及作业存储库命令,例如检索作业和步骤执行。
- 作业存储库:它包含有关当前正在运行的作业的信息以及有关该作业的历史数据。
JobOperator提供用于访问此存储库的API。JobRepository可以使用数据库或文件系统来实现。
下一节将帮助您了解批处理体系结构的一些常见特征。
1.3工作步骤
步骤是作业的独立阶段。 如上所述,作业中有两种类型的步骤。 我们将在下面尝试详细了解这两种类型。
1.3.1面向块的步骤
块状步骤将一次读取和处理一项,并将结果分组。 然后,当块达到预定义的大小时,将结果存储起来。 当数据集很大时,面向块的处理使存储结果的效率更高。 它包括三个部分。
- 项目读取器从一个数据源中依次读取输入,该数据源可以是数据库,平面文件,日志文件等。
- 处理器将根据定义的业务逻辑一一处理数据。
- 编写器将数据分块写入。 块的大小是预定义的并且是可配置的
作为块步骤的一部分,有一些检查点可为框架提供信息以完成块。 如果在块处理期间发生错误,则可以基于最后一个检查点重新开始该过程。
1.3.2面向任务的步骤
除了处理数据源中的项目外,它还执行任务。 其中包括创建或删除目录,移动文件,创建或删除数据库表等。与块步骤相比,任务步骤通常不会长时间运行。
在正常情况下,在需要清理的面向块的步骤之后使用面向任务的步骤。 例如,我们获取日志文件作为应用程序的输出。 块步骤用于处理数据并从日志文件中获取有意义的信息。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 6273
6273











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









