






 本文介绍了如何结合Apache Kafka、Kafka Streams、TensorFlow Serving和gRPC,实现流处理与模型服务的集成。通过一个Java项目的示例,展示了如何在Kafka Streams应用中使用gRPC调用TensorFlow Serving进行模型推断,同时讨论了这种方法的优缺点。
本文介绍了如何结合Apache Kafka、Kafka Streams、TensorFlow Serving和gRPC,实现流处理与模型服务的集成。通过一个Java项目的示例,展示了如何在Kafka Streams应用中使用gRPC调用TensorFlow Serving进行模型推断,同时讨论了这种方法的优缺点。
kafka grpc
机器学习/深度学习模型可以通过不同的方式进行预测。 我的首选方法是将分析模型直接部署到流处理应用程序(如Kafka Streams或KSQL )中。 您可以例如使用TensorFlow for Java API 。 这样可以实现最佳延迟和外部服务的独立性。 在我的Github项目中可以找到几个示例: 使用TensorFlow,H2O.ai,Deeplearning4j(DL4J)在Kafka Streams微服务中进行模型推断 。
但是, 直接部署模型并不总是可行的方法 。 有时有意义或需要在另一个服务基础架构中部署模型,例如TensorFlow Serving for TensorFlow模型。 然后通过RPC /请求响应通信完成模型推断。 组织或技术原因可能会强制采用此方法。 或者,您可能希望利用内置功能来管理模型服务器中的不同模型并对其进行版本控制。
因此,您将流处理与RPC /请求-响应范例结合在一起。 该体系结构如下所示:
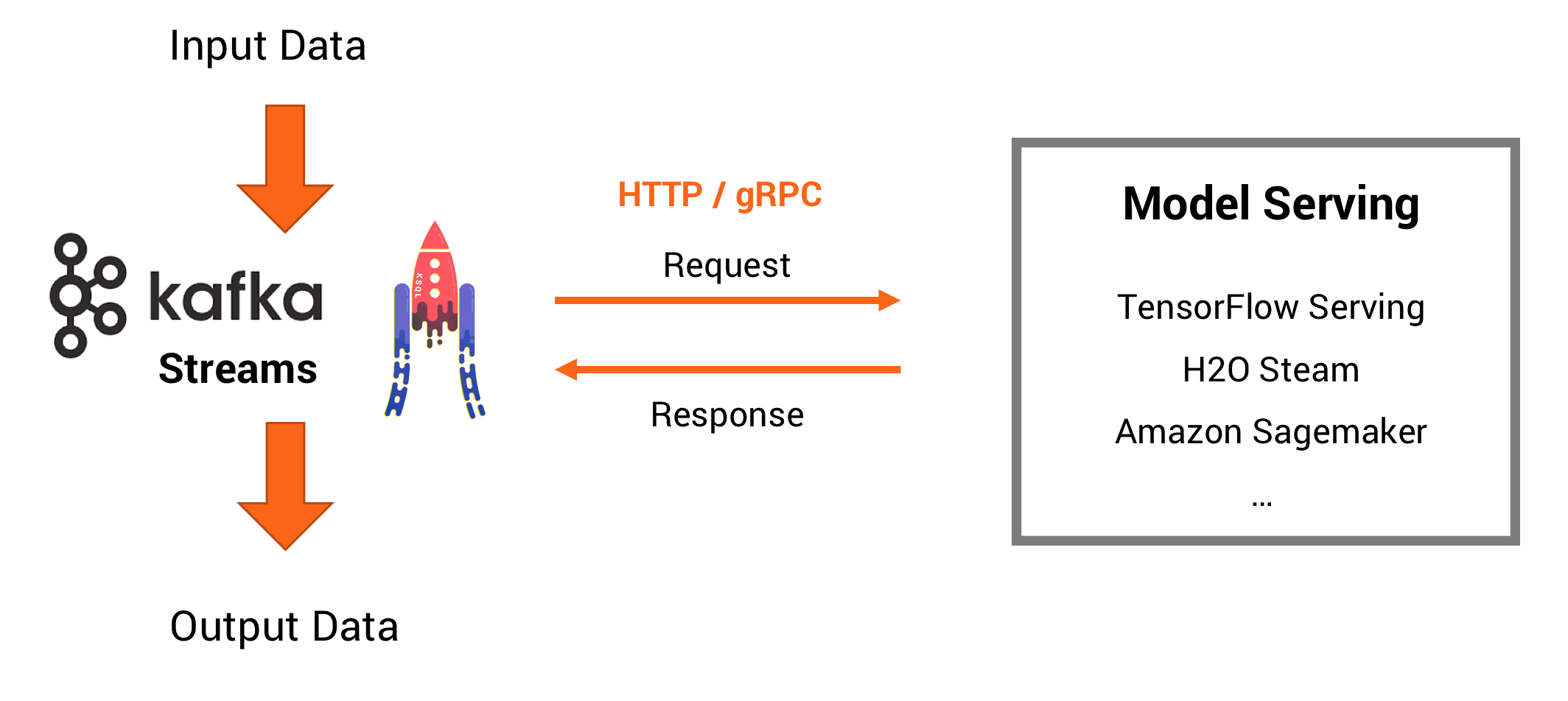
诸如TensorFlow Serving之类的外部模型服务基础架构的优点:
- 与现有技术和组织流程的简单集成
- 如果您来自非流媒体世界,则更容易理解
- 以后也可以迁移到真实流
- 内置用于不同模型和版本控制的模型管理
缺点:
- 作为远程呼叫而不是本地推断的更糟糕的延迟
- 没有离线推断(设备,边缘处理等)
- 将Kafka Streams应用程序的可用性,可伸缩性和延迟/吞吐量与RPC接口的SLA耦合在一起
- Kafka处理未涵盖的副作用(例如,发生故障时&#x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1766
1766

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









