





apache camel
《骆驼设计模式》一书介绍了20种模式以及用于设计基于Apache Camel的集成解决方案的众多技巧和最佳实践。 每种模式都基于真实的用例,并提供了Camel特定的实现细节和最佳实践。 为了让您有这本书的感觉,以下是该书的重试模式摘录,其中介绍了如何在Apache Camel中进行短期和长期退休。
上下文和问题
从本质上讲,集成应用程序必须通过网络与其他系统进行交互。 随着基于动态云的环境成为规范,并且微服务体系结构将应用程序划分为更细粒度的服务,成功的服务通信已成为许多分布式应用程序的基本前提。 与其他服务进行通信的服务必须能够透明地处理下游系统中可能发生的瞬态故障,并继续运行而不会造成任何中断。 由于可以将瞬态故障视为基础结构级别的故障,网络连接的丢失,繁忙服务所施加的超时和节流等。这些情况很少发生,并且通常会自行纠正,并且通常可以重试操作成功。
力量与解决方案
再现和解释瞬态故障可能是一项艰巨的任务,因为这些故障可能是由不定期发生的,与外部系统相关的多种因素造成的。 诸如Chaos Monkey之类的工具可用于模拟不可预测的系统中断,并在需要时让您测试应用程序的弹性。 处理瞬态故障的一个好的策略是重试该操作,并希望它会成功(如果错误确实是瞬态的,它将成功;只要保持冷静并继续重试)。
要实现“重试”逻辑,需要考虑以下几个方面:
重试哪些失败?
某些服务操作(例如HTTP调用和关系数据库交互)是重试逻辑的潜在候选者,但是在实现它之前需要进一步分析。 关系数据库可能会因为限制使用过多资源而拒绝连接尝试,或者由于并发修改而拒绝SQL插入操作。 在这些情况下重试可能会成功。 但是,如果关系数据库由于凭据错误而拒绝连接,或者由于外键约束SQL插入操作失败,则重试该操作将无济于事。 与HTTP调用类似,重试连接超时或响应超时可能会有所帮助,但是重试由业务错误引起的SOAP Fault毫无意义。 因此,请谨慎选择重试次数。
多久重试一次?
一旦确定了重试的必要性,就应该调整特定的重试策略以满足两个应用程序的性质:具有重试逻辑的服务使用者和具有短暂故障的服务提供者。 例如,如果实时集成服务无法处理请求,则可能只允许它在返回响应之前进行几次重试,且延迟很短,而基于批处理的异步服务可能能够承担更多的重试。更长的延迟和指数退缩。 重试策略还应考虑其他因素,例如服务消耗合同和服务提供商的SLA。 例如,非常激进的重试策略可能会导致服务使用者进一步受到限制,甚至将其列入黑名单,或者它可能会使服务完全过载并降级繁忙的服务,甚至根本无法恢复。 某些API可能会指示您一段时间内的剩余请求计数以及响应中的黑名单信息,但有些可能不会。 因此,重试策略定义了应多久重试一次以及多长时间之后您才能接受这是一个非暂时性故障并放弃。
幂等
重试操作时,请考虑对该操作可能产生的副作用。 重试逻辑将消耗的服务操作应设计为幂等的。 使用相同的数据输入重试相同的操作应该没有任何副作用。 想象一个请求已成功处理,但响应尚未返回。 服务使用者可以假定请求已失败,然后重试相同的操作,这可能会产生一些意外的副作用。
监控方式
跟踪和报告重试也很重要。 如果某些操作在成功之前不断被重试,或者在失败之前被重试了太多次,则必须确定并修复这些操作。 由于在没有适当监视的情况下,服务中的重试应该对服务使用者透明,因此它们可能未被检测到,并以负面的方式影响了整个系统的稳定性和性能。
超时和SLA
当下游系统中发生暂时性故障并且重试逻辑生效时,重试服务的总处理时间将大大增加。 与其从重试和延迟次数的角度考虑重试参数,重要的是从服务SLA和服务使用者超时的角度来驱动这些值。 因此,请考虑处理请求所允许的最长时间,并确定可以挤入该时间范围的最大重试次数和延迟时间(包括处理时间)。
机械学
使用Camel和ActiveMQ有几种不同的重试方法。
骆驼重新交付政策(重试)
这是在骆驼中重试的最流行和通用的方法。 重新交付策略定义了重试规则(例如重试和延迟的次数,是否使用冲突避免和指数退避乘数以及日志记录),然后可以将这些规则应用于处理流程的多个errorHandler和onException块。 每当引发异常时,将应用重新交付策略中的规则。

骆驼重新交付政策示例
重试机制的主要区别在于,Camel错误处理逻辑不会重试整个路由,而是仅重试处理流程中的失败端点。 这要归功于在骆驼路线中连接端点的通道。 只要处理节点抛出异常,该异常就会传播回并被通道捕获,然后可以应用各种错误处理策略。 这里的另一个重要区别是基于Camel的错误处理和重新传递逻辑是内存中的,并且它在重试期间会阻塞线程,这会产生后果。 如果所有线程都被阻塞并等待重试,则可能会用完线程。 线程的所有者可以是使用者,也可以是带有来自路由的线程池的某种并行处理结构(例如并行拆分器,收件人列表或线程DSL)。 例如,如果我们有一个带有十个请求处理线程的HTTP使用者,一个繁忙且拒绝连接的数据库以及一个具有指数退避的RedeliveryPolicy,则在十个请求之后,所有线程将最终等待重试,而没有线程将可用于处理新请求。 解决此线程阻塞问题的方法是选择
asyncDelayedRedelivery,其中Camel将使用线程池并异步安排重新交付。 但是线程池将重新交付请求存储在内部队列中,因此此选项可以非常快速地消耗所有堆。 还请记住,所有错误处理程序都有一个线程池,一个线程池有一个线程池
CamelContext,因此,除非您为持久的重新交付配置了特定的线程池,否则该池可能会在一条路径中耗尽,而在另一条路径中阻塞线程。 另一个含义是,由于重试逻辑在内存中的性质,重新启动应用程序将丢失重试状态,并且将无法分发或保持该状态。
总体而言,这种Camel重试机制非常适合短时本地重试,并且可以克服网络故障或资源短暂锁定的情况。 对于更长的延迟,最好使用具有群集和非线程阻塞功能的持久重新交付来重新设计应用程序(下面将介绍这种解决方案)。
ActiveMQ经纪人重新交付(长期重试)
该重试机制与前两个机制具有不同的特征,因为它是由代理本身(而不是消息使用者或Camel路由引擎)管理的。 ActiveMQ借助其调度程序,可以延迟传递消息。 此功能是代理重新交付插件的基础。 重新交付插件可以拦截死信处理并重新安排失败消息以重新交付。 计划将失败的消息传递到原始队列的尾部,然后重新传递给消息使用者,而不是传递给DLQ。 当总消息顺序不重要,并且消费者之间的吞吐量和负载分配很重要时,这很有用。
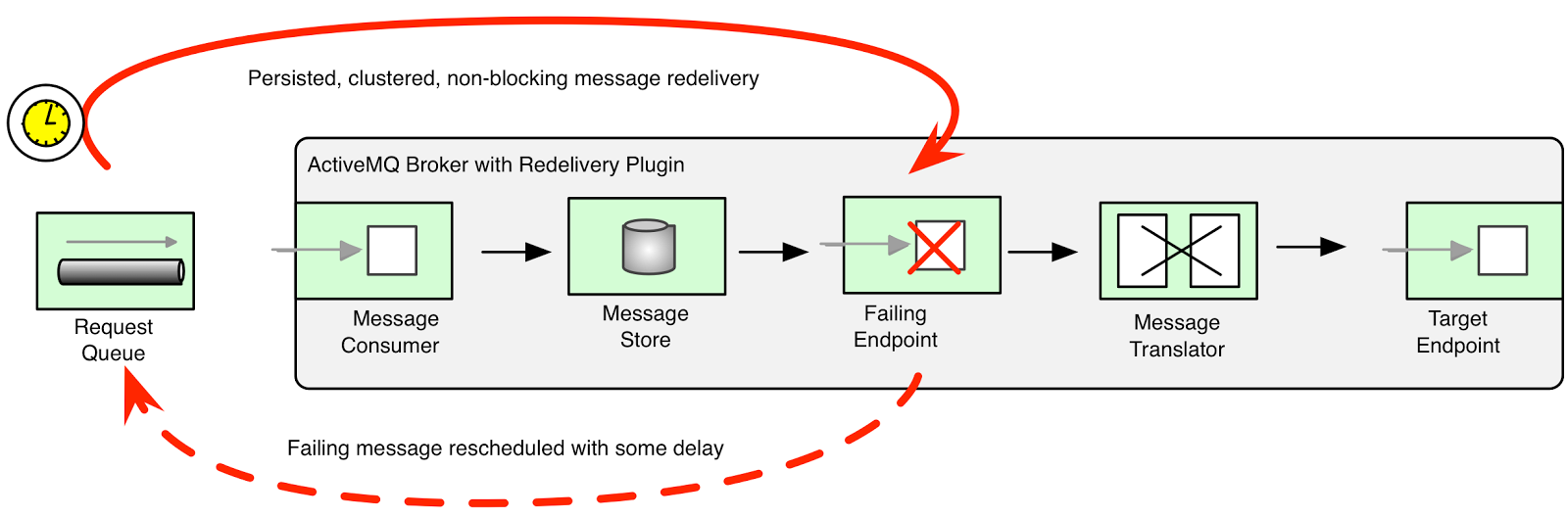
ActiveMQ重新交付示例
旁注–我知道,无耻的插件,但是我对这本书的研究感到非常兴奋。 您可以在这里享受40%的折扣,直到6月底为止! 希望你喜欢。 与以前的方法的不同之处在于,该消息在代理消息存储中是持久的,并且在代理或骆驼路由重新启动后仍会继续存在而不会影响重新交付的时间。 另一个优点是,对于每个重试的消息,没有线程被阻塞。 由于消息已返回给代理,因此可以使用竞争消费者模式将消息传递给其他消费者。 但是副作用是消息顺序丢失了,因为消息将被放置在消息队列的尾部。 同样,使用调度程序运行代理也会对性能产生一定的影响。 这种重试机制对于长时间的重试很有用,因为您无法承受每个失败消息的阻塞线程。 当您希望保留该消息并将其群集以进行重新发送时,它也很有用。
注意,与使用代理重新交付插件相比,手动实现代理重新交付逻辑很容易。 您所要做的就是捕获异常并发送带有
AMQ_SCHEDULED_DELAY标头指向中间队列。 一旦延迟过去,该消息将被使用,并且将重试相同的操作。 您可以多次重新计划和处理同一条消息,直到放弃并将消息放入退避或死信队列中。
翻译自: https://www.javacodegeeks.com/2017/06/short-retry-vs-long-retry-apache-camel-2.html
apache camel















 932
932

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









