





javaslang
Java 8的lambda(λ)使我们能够创建出色的API。 它们极大地提高了语言的表达能力。
Javaslang利用lambda来基于功能模式创建各种新功能。 其中之一是功能性集合库,旨在替代Java的标准集合。
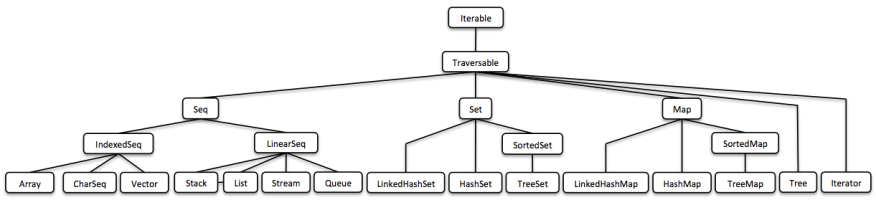
(这只是鸟瞰图,您将在下面找到易于理解的版本。)
功能编程
在深入探讨有关数据结构的细节之前,我想谈一些基本知识。 这将清楚说明为什么我创建Javaslang以及专门创建新的Java集合。
副作用
Java应用程序通常有很多副作用 。 他们改变了某种状态,也许是外部世界。 常见的副作用是在适当位置更改对象或变量,打印到控制台,写入日志文件或数据库。 如果副作用以不希望的方式影响我们程序的语义,则认为它们是有害的 。
例如,如果一个函数抛出一个异常并解释了该异常,则它被认为是影响我们程序的副作用。 此外, 异常类似于非本地goto语句 。 他们打破了正常的控制流程。 但是,实际应用程序确实会产生副作用。
int divide(int dividend, int divisor) {
// throws if divisor is zero
return dividend / divisor;
}在功能设置中,我们处于有利的情况下,可以在Try中封装副作用:
// = Success(result) or Failure(exception)
Try<Integer> divide(Integer dividend, Integer divisor) {
return Try.of(() -> dividend / divisor);
}此版本的除法不再抛出。 通过使用尝试类型,我们明确了可能的故障。

参照透明
如果某个函数可以用其值替换而不影响程序的行为,则该函数或更一般的表达式称为“ 引用透明” 。 简单地说,给定相同的输入,输出总是相同的。
// not referential transparent
Math.random();
// referential transparent
Math.max(1, 2);如果涉及的所有表达式都是引用透明的,则该函数称为纯函数。 由纯函数组成的应用程序在编译后很可能就可以正常工作 。 我们能够对此进行推理。 单元测试易于编写,并且调试已成为过去。
价值观思考
Clojure的创建者Rich Hickey就“价值的价值”进行了精彩的演讲。 最有趣的值是不可变值。 主要原因是价值不变
- 本质上是线程安全的,因此不需要同步
- 对于equals和hashCode稳定,因此是可靠的哈希键
- 不需要克隆
- 在未经检查的协变强制转换中使用时,表现为类型安全(特定于Java)
改进Java的关键是使用不可变的值与引用透明函数配对。
Javaslang提供了必要的控件和集合,以实现日常Java编程中的这一目标。
简而言之,数据结构
Javaslang的集合库由建立在lambda之上的一组丰富的功能数据结构组成。 他们与Java原始集合共享的唯一接口是Iterable。 主要原因是Java的collection接口的mutator方法不返回基础collection类型的对象。
通过查看不同类型的数据结构,我们将了解为什么如此重要。
可变数据结构
Java是一种面向对象的编程语言。 我们将状态封装在对象中以实现数据隐藏,并提供更改器方法来控制状态。 Java集合框架(JCF)就是基于这个想法而建立的。
interface Collection<E> {
// removes all elements from this collection
void clear();
}今天,我领悟到一种无效的返回类型是一种气味。 有证据表明发生了副作用 ,状态发生了变化。 共享的可变状态不仅是并发设置,而且是失败的重要原因。
不变的数据结构
不变的数据结构在创建后无法修改。 在Java上下文中,它们以集合包装的形式广泛使用。
List<String> list = Collections.unmodifiableList(otherList);
// Boom!
list.add("why not?");有许多库为我们提供了类似的实用程序方法。 结果始终是特定集合的不可修改视图。 通常,当我们调用mutator方法时,它将在运行时抛出。
持久数据结构
持久数据结构在被修改时会保留其自身的先前版本,因此实际上是不可变的。 完全持久的数据结构允许在任何版本上进行更新和查询。
许多操作仅执行很小的更改。 仅复制以前的版本是没有效率的。 为了节省时间和内存,至关重要的是确定两个版本之间的相似性并共享尽可能多的数据。
该模型没有施加任何实现细节。 功能数据结构在这里发挥作用。
功能数据结构
也被称为纯功能数据结构 ,它们是不可变的和持久的 。 功能数据结构的方法是参照透明的 。
Javaslang具有各种最常用的功能数据结构。 以下示例将进行深入说明。
链表
最受欢迎的也是最简单的功能数据结构之一是(单)链接List 。 它具有头元素和尾元素列表。 链接列表的行为类似于遵循后进先出(LIFO)方法的堆栈。
在Javaslang中,我们实例化一个List像这样:
// = List(1, 2, 3)
List<Integer> list1 = List.of(1, 2, 3);每个List元素形成一个单独的List节点。 最后一个元素的尾部为Nil,即空列表。
![]()
这使我们能够在列表的不同版本之间共享元素。
// = List(0, 2, 3)
List<Integer> list2 = list1.tail().prepend(0);新的head元素0 链接到原始List的尾部。 原始列表保持不变。

这些操作在恒定的时间内发生,换句话说,它们与List的大小无关。 其他大多数操作都需要线性时间。 在Javaslang中,这是由接口LinearSeq表示的,我们可能已经从Scala知道了。
如果我们需要可在恒定时间内查询的数据结构,则Javaslang提供了Array和Vector。 两者都具有随机访问功能。
数组类型由对象的Java数组支持。 插入和删除操作花费线性时间。 向量在数组和列表之间。 它在随机访问和修改这两个方面都表现出色。
实际上,链接列表也可以用于实现Queue数据结构。
队列
可以基于两个链接列表来实现非常有效的功能队列。 前一个 List包含已出队的元素, 后一个 List包含已入 队的元素。 入队和出队两个操作均在O(1)中执行。
Queue<Integer> queue = Queue.of(1, 2, 3)
.enqueue(4)
.enqueue(5);初始队列由三个元素创建。 后面的列表上有两个元素。
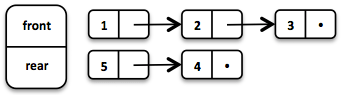
如果在出队时前面的List用完了元素,那么后面的List将被反转并成为新的前面的List。

使一个元素出队时,我们得到一对第一个元素和剩余的Queue。 因为功能数据结构是不可变的且持久的,所以有必要返回新版本的Queue。 原始队列不受影响。
Queue<Integer> queue = Queue.of(1, 2, 3);
// = (1, Queue(2, 3))
Tuple2<Integer, Queue<Integer>> dequeued =
queue.dequeue();队列为空时会发生什么? 然后dequeue()将引发NoSuchElementException。 要以功能性的方式来实现它,我们宁愿期望一个可选结果。
// = Some((1, Queue()))
Queue.of(1).dequeueOption();
// = None
Queue.empty().dequeueOption();不管是否为空,都可以进一步处理可选结果。
// = Queue(1)
Queue<Integer> queue = Queue.of(1);
// = Some((1, Queue()))
Option<Tuple2<Integer, Queue<Integer>>>
dequeued = queue.dequeueOption();
// = Some(1)
Option<Integer> element =
dequeued.map(Tuple2::_1);
// = Some(Queue())
Option<Queue<Integer>> remaining =
dequeued.map(Tuple2::_2);排序集
排序集是比队列更常用的数据结构。 我们使用二分搜索树来对它们进行功能化建模。 这些树由最多具有两个子节点的节点组成,每个节点处都有值。
我们在有序的情况下(由元素Comparator表示)构建二进制搜索树。 任何给定节点的左子树的所有值都严格小于给定节点的值。 正确的子树的所有值都严格大于。
// = TreeSet(1, 2, 3, 4, 6, 7, 8)
SortedSet<Integer> xs =
TreeSet.of(6, 1, 3, 2, 4, 7, 8); 
对此类树的搜索以O(log n)时间运行。 我们从根开始搜索,并确定是否找到了元素。 由于这些值的总顺序,我们知道下一步要在当前树的左侧或右侧分支中搜索的位置。
// = TreeSet(1, 2, 3);
SortedSet<Integer> set = TreeSet.of(2, 3, 1, 2);
// = TreeSet(3, 2, 1);
Comparator<Integer> c = (a, b) -> b - a;
SortedSet<Integer> reversed =
TreeSet.of(c, 2, 3, 1, 2);大多数树操作本质上都是递归的 。 插入功能的行为类似于搜索功能。 当到达搜索路径的末尾时,将创建一个新节点,并将整个路径重建到根。 尽可能引用现有的子节点。 因此,插入操作需要O(log n)的时间和空间。
// = TreeSet(1, 2, 3, 4, 5, 6, 7, 8)
SortedSet<Integer> ys = xs.add(5); 
为了维持二叉搜索树的性能特征,需要保持平衡。 从根到叶的所有路径都必须具有大致相同的长度。
在Javaslang中,我们基于Red / Black Tree实现了二叉搜索树 。 它使用特定的着色策略来使树在插入和删除时保持平衡。 要了解有关此主题的更多信息,请参阅Chris Okasaki的《 Purely Functional Data Structures》 。
收藏状态
通常,我们正在观察编程语言的融合。 好的功能使它消失,其他消失。 但是Java是不同的,它永远是向后兼容的。 这是一种优势,但也会减缓发展。
Lambda使Java和Scala更加紧密地联系在一起,但是它们仍然如此不同。 Scala的创建者Martin Odersky最近在他的BDSBTB 2015主题演讲中提到了Java 8集合的状态。
他将Java的Stream描述为迭代器的一种奇特形式。 Java 8 Stream API是提升集合的示例。 它的作用是定义一个计算并将其链接到另一个专有步骤中的特定集合。
// i + 1
i.prepareForAddition()
.add(1)
.mapBackToInteger(Mappers.toInteger())这就是新的Java 8 Stream API的工作方式。 它是众所周知的Java集合之上的计算层。
// = ["1", "2", "3"] in Java 8
Arrays.asList(1, 2, 3)
.stream()
.map(Object::toString)
.collect(Collectors.toList())Javaslang受到Scala的极大启发。 这就是上面的示例在Java 8中的样子。
// = Stream("1", "2", "3") in Javaslang
Stream.of(1, 2, 3).map(Object::toString)在过去的一年中,我们为实现Javaslang集合库付出了很多努力。 它包含使用最广泛的收集类型。
顺序
我们通过实现顺序类型开始了自己的旅程。 我们已经在上面描述了链接列表。 流,然后是一个懒惰的链表。 它使我们可以处理可能无限长的元素序列。
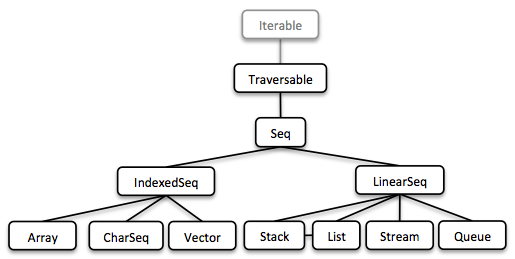
所有集合都是可迭代的,因此可以在增强的for语句中使用。
for (String s : List.of("Java", "Advent")) {
// side effects and mutation
}我们可以通过内部化循环并使用lambda注入行为来实现相同目的。
List.of("Java", "Advent").forEach(s -> {
// side effects and mutation
});无论如何,正如我们之前所看到的,我们更喜欢返回值的表达式而不是什么都不返回的语句。 通过看一个简单的示例,很快我们将认识到语句增加了噪音,并将属于的内容分开。
String join(String... words) {
StringBuilder builder = new StringBuilder();
for(String s : words) {
if (builder.length() > 0) {
builder.append(", ");
}
builder.append(s);
}
return builder.toString();
}Javaslang集合为我们提供了许多对底层元素进行操作的功能。 这使我们能够以一种非常简洁的方式表达事物。
String join(String... words) {
return List.of(words)
.intersperse(", ")
.fold("", String::concat);
}大多数目标可以使用Javaslang以各种方式实现。 在这里,我们将整个方法主体简化为List实例上的流畅函数调用。 我们甚至可以删除整个方法,然后直接使用List获取计算结果。
List.of(words).mkString(", ");在现实世界的应用程序中,我们现在能够大幅度减少代码行数,从而降低错误的风险。
设置并映射
顺序很棒。 但是,为了完整起见,集合库还需要不同类型的“集合”和“地图”。
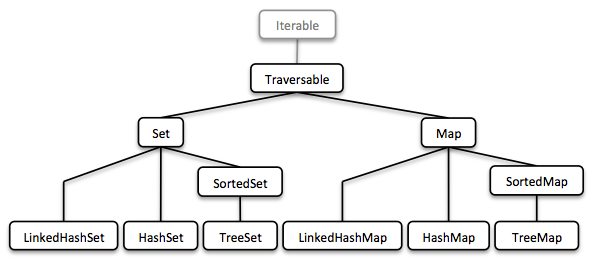
我们描述了如何使用二叉树结构对排序集进行建模。 排序的Map就是包含键值对并具有键顺序的排序Set。
HashMap实现由哈希数组映射树(HAMT)支持 。 因此,HashSet由包含密钥对的HAMT支持。
我们的地图不具有特殊的条目类型来表示键值对。 相反,我们使用已经是Javaslang一部分的Tuple2。 元组的字段被枚举。
// = (1, "A")
Tuple2<Integer, String> entry = Tuple.of(1, "A");
Integer key = entry._1;
String value = entry._2;Maps和Tuples在整个Javaslang中使用。 元组不可避免地会以一般方式处理多值返回类型。
// = HashMap((0, List(2, 4)), (1, List(1, 3)))
List.of(1, 2, 3, 4).groupBy(i -> i % 2);
// = List((a, 0), (b, 1), (c, 2))
List.of('a', 'b', 'c').zipWithIndex();在Javaslang,我们通过实现99欧拉问题探索和测试我们的库。 这是一个很好的概念证明。 请不要犹豫,发送请求请求。
动手!
我真的希望本文能引起您对Javaslang的兴趣。 即使像我一样在工作中使用Java 7(或更低版本),也可以遵循函数式编程的思想。 这将是非常好的!
请确保Javaslang在2016年成为工具带的一部分。
骇客骇客!
PS:有问题吗? @_Javaslang或Gitter聊天
翻译自: https://www.javacodegeeks.com/2015/12/functional-data-structures-java-8-javaslang.html
javaslang















 215
215

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









