





lucene 源码分析
本文是我们名为“ Apache Lucene基础知识 ”的学院课程的一部分。
在本课程中,您将了解Lucene。 您将了解为什么这样的库很重要,然后了解Lucene中搜索的工作方式。 此外,您将学习如何将Lucene Search集成到您自己的应用程序中,以提供强大的搜索功能。 在这里查看 !
1.简介
在Lucene中,分析是将字段文本转换为其最基本的索引表示形式(术语)的过程。 通常,将令牌称为分析器的单词(我们仅在参考英语时讨论该主题)。 但是,对于特殊的分析器,令牌可以带有多个单词,其中也包括空格。 这些术语用于确定在搜索过程中哪些文档与查询匹配。 例如,如果您在字段中为该句子编入索引,则术语可能以for和example开头,依此类推,依次排列为单独的术语。 分析器是分析过程的封装。 分析器通过对文本执行任何数量的操作来标记文本,这些操作可能包括提取单词,丢弃标点符号,从字符中删除重音,小写(也称为规范化),删除常用单词,将单词简化为词根形式(词干)或更改单词变成基本形式(词义化)。 此过程也称为标记化,从文本流中提取的文本块称为标记。 标记及其相关的字段名称是术语。
2.使用分析仪
Lucene的主要目标是促进信息检索。 强调检索很重要。 您想在Lucene上放置一小段文字,然后让该文字中的各个单词进行丰富的搜索。 为了让Lucene知道什么是“单词”,它会在索引编制过程中分析文本并将其提取为术语。 这些术语是用于搜索的原始构建块。
对于Lucene,选择合适的分析仪是一项至关重要的开发决定,而且一个尺寸绝对不能满足所有需求。 语言是一个因素,因为每种语言都有其独特的功能。 要考虑的另一个因素是要分析的文本的范围。 不同行业的术语,首字母缩写词和缩写词可能会引起注意。 任何分析仪都无法满足所有情况。 内置的分析选项可能无法满足我们的需求,因此我们必须投资创建定制的分析解决方案。 幸运的是,Lucene的构建基块使此操作非常容易。
通常,Lucene分析仪的设计遵循以下步骤:
实际文本–>基本令牌准备–>小写过滤–>停用词过滤(否定不太有用的词,占内容中40-50%的词的否定)–>通过自定义逻辑过滤–>最终令牌准备用于在lucene中建立索引,这将在lucene的搜索中参考。
不同的分析器使用不同的标记器,在此基础上,输出标记流–文本组的顺序将有所不同。
词干用于获取相关词的词根。 例如,对于单词running,ran,run等,将运行根词。 在分析器中使用此功能可通过搜索api使搜索范围的内容更高。 如果在索引中引用了根词,则可能是针对确切的单词,我们可以在索引中有多个选项进行搜索,并且短语匹配的可能性可能更高。 因此,这种概念(称为词干分析器)经常用于分析仪设计中。
停用词是书面语言中常用但不太有用的词。 对于英语,这些单词是“ a”,“ the”,“ I”等。
在不同的分析器中,将从停止词中清除令牌流,以使索引对搜索结果更有用。
Lucene分析仪的工作过程
分析过程分为三个部分。 为了帮助说明该过程,我们将使用以下原始文本作为示例。 (处理HTML或PDF文档以获得标题,主要文本和其他要分析的字段称为解析,这超出了分析的范围。假设解析器已经从较大的文档中提取了此文本。)
<h1>Building a <em>top-notch</em> search engine</h1>首先,字符过滤器对要分析的原始文本进行预处理。 例如,HTML Strip字符过滤器将删除HTML。 现在,我们剩下了以下文本:
Building a top-notch search engine接下来,令牌生成器将预处理的文本分解为令牌。 令牌通常是单词,但是不同的令牌生成器处理特殊情况(例如“ top-notch”)的方式有所不同。 一些令牌生成器(例如标准令牌生成器)将破折号视为单词边界,因此“ top-notch”将是两个令牌(“ top”和“ notch”)。 其他令牌生成器(例如,空白令牌生成器)仅将空白视为单词边界,因此“ top-notch”将是单个令牌。 还有一些不寻常的令牌生成器,例如NGram令牌生成器,它会生成部分单词的令牌。
假设破折号被认为是单词边界,我们现在有:
[Building] [a] [top] [notch] [search] [engine]最后,令牌过滤器对令牌执行其他处理,例如删除后缀(称为词干)并将字符转换为小写。 令牌的最终序列可能看起来像这样:
[build] [a] [top] [notch] [search] [engine]分词器和零个或多个过滤器的组合构成了一个分析器。 默认情况下,使用标准分析器,该分析器由标准标记器和标准,小写和停止标记过滤器组成。
分析仪可以执行更复杂的操作以获得更好的结果。 例如,分析人员可能会使用令牌过滤器来拼写检查词或引入同义词,以便搜索“ saerch”或“ find”都将返回包含“ Searching”的文档。 也有类似功能的不同实现方式可供选择。
除了在包括的分析器之间进行选择之外,我们还可以通过将现有的标记器和零个或多个过滤器链接在一起来创建自己的自定义分析器。 标准分析器不执行词干分析,因此您可能需要创建一个包含词干标记过滤器的自定义分析器。
有这么多的可能性,我们可以测试不同的组合,看看哪种方法最适合我们的情况。
3.分析仪的类型
在Lucene中,一些不同的分析器是:
一个。 空白分析仪
空格分析器根据空格将文本处理为令牌。 空白之间的所有字符均已建立索引。 在此,停用词不用于分析,并且大小写不变。 Whitespace分析器是使用Whitespace Tokenizer(Whitespace标记生成器)(Whitespace类型的标记生成器,用于在空白处分割文本)构建的。
b。 简单分析器
SimpleAnalyser使用字母标记器和小写过滤从内容中提取标记并将其放入Lucene索引中。 简单的分析器是使用小写标记器构建的。 小写的标记符执行字母标记符和小写标记过滤器的功能。 它以非字母分隔文本并将其转换为小写。 尽管它在功能上等同于Letter令牌生成器和小写令牌过滤器的组合,但同时执行两个任务具有性能优势,因此是这种(冗余的)实现。
C。 停止分析器
StopAnalyser删除了对索引不太有用的常见英语单词。 这些是通过向分析器提供STOP_WORDS列表的列表来完成的。
Stop分析器是使用带有Stop令牌过滤器的小写令牌生成器构建的(Stop类型的令牌过滤器可从令牌流中删除停用词)
以下是可以为停止分析器类型设置的设置:
- 停用词->用来停用过滤器的停用词列表。 默认为英语停用词。
- stopwords_path->停用词文件配置的路径(相对于配置位置或绝对路径)。
d。 标准分析仪
StandardAnalyser是通用分析器。 它通常在标准停用词的帮助下将标记转换为小写字母以分析文本,并且还受其他规则约束。 StandardAnalyzer是将标准令牌生成器与标准令牌过滤器(标准类型的令牌过滤器,对使用标准令牌生成器提取的令牌进行归一化处理),小写令牌过滤器和停止令牌过滤器一起构建的。
e。 经典分析仪
使用英语停用词列表通过ClassicFilter,LowerCaseFilter和StopFilter过滤ClassicTokenizer的分析器。
F。 UAX29URLEmailAnalyzer
使用英语停用词列表,使用StandardFilter,LowerCaseFilter和StopFilter过滤UAX29URLEmailTokenizer的分析器。
G。 关键字分析器
类型为关键字的分析器,可将整个流“标记为”单个标记。 这对于诸如邮政编码,ID之类的数据很有用。 注意,使用映射定义时,将字段简单标记为not_analyzed可能更有意义。
H。 雪球分析仪
使用标准标记器,标准过滤器,小写过滤器,停止过滤器和雪球过滤器的雪球分析器。
Snowball Analyzer是Lucene的词干分析器,其最初基于snowball.tartarus.org的snowball项目。
用法示例:
{
"index" : {
"analysis" : {
"analyzer" : {
"my_analyzer" : {
"type" : "snowball",
"language" : "English"
}
}
}
}
}一世。 模式分析仪
类型模式分析器,可以通过正则表达式灵活地将文本分成术语。 接受以下设置:
模式分析器示例:
空白令牌生成器:
curl -XPUT 'localhost:9200/test' -d '
{
"settings":{
"analysis": {
"analyzer": {
"whitespace":{
"type": "pattern",
"pattern":"\\\\\\\\s+"
}
}
}
}
}curl 'localhost:9200/test/_analyze?pretty=1&analyzer=whitespace' -d 'foo,bar baz'
# "foo,bar", "baz"非单词字符标记器:
curl -XPUT 'localhost:9200/test' -d '
{
"settings":{
"analysis": {
"analyzer": {
"nonword":{
"type": "pattern",
"pattern":"[^\\\\\\\\w]+"
}
}
}
}
}curl 'localhost:9200/test/_analyze?pretty=1&analyzer=nonword' -d 'foo,bar baz'</strong>
# "foo,bar baz" becomes "foo", "bar", "baz"curl 'localhost:9200/test/_analyze?pretty=1&analyzer=nonword' -d 'type_1-type_4'</strong>
# "type_1","type_4"驼峰标记器:
curl -XPUT 'localhost:9200/test?pretty=1' -d '
{
"settings":{
"analysis": {
"analyzer": {
"camel":{
"type": "pattern",
"pattern":"([^\\\\\\\\p{L}\\\\\\\\d]+)|(?<=\\\\\\\\D)(?=\\\\\\\\d)|(?<=\\\\\\\\d)(?=\\\\\\\\D)|(?<=[\\\\\\\\p{L}&&[^\\\\\\\\p{Lu}]])(?=\\\\\\\\p{Lu})|(?<=\\\\\\\\p{Lu})(?=\\\\\\\\p{Lu}[\\\\\\\\p{L}&&[^\\\\\\\\p{Lu}]])"
}
}
}
}
}curl 'localhost:9200/test/_analyze?pretty=1&analyzer=camel' -d '
MooseX::FTPClass2_beta
'
# "moose","x","ftp","class","2","beta"上面的正则表达式更容易理解为:
| ([^ \\ p {L} \\ d] +) | #吞下非字母和数字, |
| | (?<= \\ D)(?= \\ d) | #或非数字后跟数字, |
| | (?<= \\ d)(?= \\ D) | #或数字后跟非数字, |
| | (?<= [\\ p {L} && [^ \\ p {Lu}]]) | #或小写 |
| (?= \\ p {Lu}) | #后跟大写字母, |
| | (?<= \\ p {Lu}) | #或大写 |
| (?= \\ p {Lu} | #后跟大写 |
| [\\ p {L} && [^ \\ p {Lu}]] | #然后小写 |
表格1
j。 定制分析仪
一种自定义类型的分析器,允许将令牌生成器与零个或多个令牌过滤器以及零个或多个字符过滤器组合。 定制分析器接受要使用的标记器的逻辑/注册名称,以及标记过滤器的逻辑/注册名称的列表。
这是自定义分析器的示例:
index :
analysis :
analyzer :
myAnalyzer2 :
type : custom
tokenizer : myTokenizer1
filter : [myTokenFilter1, myTokenFilter2]
char_filter : [my_html]
tokenizer :
myTokenizer1 :
type : standard
max_token_length : 900
filter :
myTokenFilter1 :
type : stop
stopwords : [stop1, stop2, stop3, stop4]
myTokenFilter2 :
type : length
min : 0
max : 2000
char_filter :
my_html :
type : html_strip
escaped_tags : [xxx, yyy]
read_ahead : 1024语言参数可以与雪球过滤器具有相同的值,并且默认为英语。 请注意,并非所有语言分析器都提供默认的停用词集。
stopwords参数可用于为没有默认语言的语言提供停用词,或仅用您的自定义列表替换默认设置。 检查Stop Analyzer以获取更多详细信息。 例如,此处和此处都提供了其中许多语言的默认停用词集。
一个配置示例(YAML格式),指定瑞典语并带有停用词:
index :
analysis :
analyzer :
my_analyzer:
type: snowball
language: Swedish
stopwords: "och,det,att,i,en,jag,hon,som,han,på,den,med,var,sig,för,så,till,är,men,ett,om,hade,de,av,icke,mig,du,henne,då,sin,nu,har,inte,hans,honom,skulle,hennes,där,min,man,ej,vid,kunde,något,från,ut,när,efter,upp,vi,dem,vara,vad,över,än,dig,kan,sina,här,ha,mot,alla,under,någon,allt,mycket,sedan,ju,denna,själv,detta,åt,utan,varit,hur,ingen,mitt,ni,bli,blev,oss,din,dessa,några,deras,blir,mina,samma,vilken,er,sådan,vår,blivit,dess,inom,mellan,sådant,varför,varje,vilka,ditt,vem,vilket,sitta,sådana,vart,dina,vars,vårt,våra,ert,era,vilkas" 这是一个自定义字符串分析器的示例,该示例是通过扩展Lucene的抽象Analyzer类而构建的。 以下清单显示了实现了tokenStream(String,Reader)方法的SampleStringAnalyzer。 SampleStringAnalyzer定义了一组停用词,可以使用Lucene提供的StopFilter在索引过程中将其丢弃。 tokenStream方法检查正在建立索引的字段。 如果该字段是注释,它将首先使用LowerCaseTokenizer对输入进行标记和小写,使用StopFilter消除英语的停用词(一组有限的英语停用词),并使用PorterStemFilter除去常见的词尾变化形式。 如果要索引的内容不是注释,则分析器使用LowerCaseTokenizer对输入进行标记化和小写,并使用StopFilter消除Java关键字。
public class SampleStringAnalyzer extends Analyzer {
private Set specialStopSet;
private Set englishStopSet;
private static final String[] SPECIALWORD_STOP_WORDS = {
"abstract","implements","extends","null""new",
"switch","case", "default" ,"synchronized" ,
"do", "if", "else", "break","continue","this",
"assert" ,"for", "transient",
"final", "static","catch","try",
"throws","throw","class", "finally","return",
"const" , "native", "super","while", "import",
"package" ,"true", "false" };
private static final String[] ENGLISH_STOP_WORDS ={
"a", "an", "and", "are","as","at","be" "but",
"by", "for", "if", "in", "into", "is", "it",
"no", "not", "of", "on", "or", "s", "such",
"that", "the", "their", "then", "there","these",
"they", "this", "to", "was", "will", "with" };
public SourceCodeAnalyzer(){
super();
specialStopSet = StopFilter.makeStopSet(SPECIALWORD_STOP_WORDS);
englishStopSet = StopFilter.makeStopSet(ENGLISH_STOP_WORDS);
}
public TokenStream tokenStream(String fieldName,
Reader reader) {
if (fieldName.equals("comment"))
return new PorterStemFilter(
new StopFilter(
new LowerCaseTokenizer(reader),englishStopSet));
else
return new StopFilter(
new LowerCaseTokenizer(reader),specialStopSet);
}
}
}分析仪内部是什么?
分析人员需要返回TokenStream
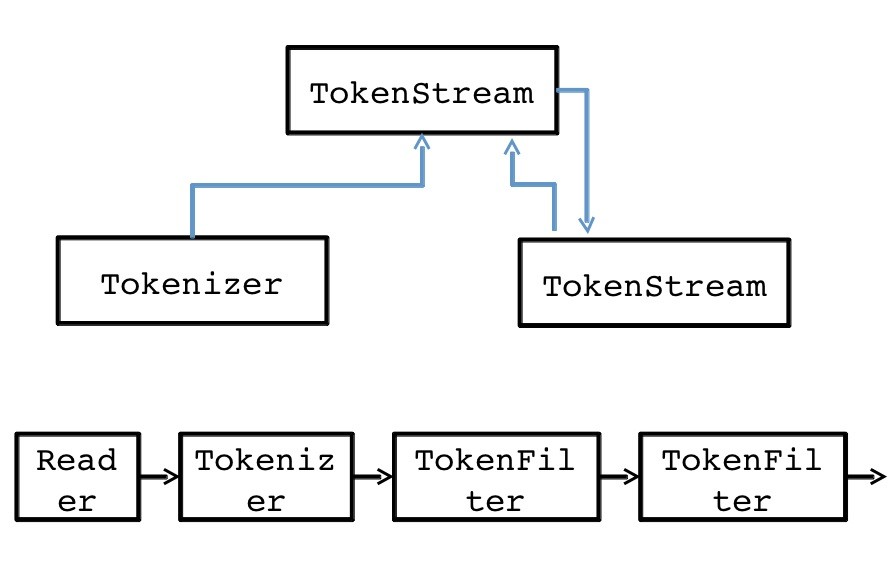
图1
将文本分析为令牌:
在文本字段上进行搜索和建立索引需要将文本数据处理为令牌。 软件包oal.analysis包含用于对文本进行标记和索引的基类。 处理可以由一系列转换组成,例如,空白标记化,大小写规范化,停止列表和词干。
抽象类oal.analysis.TokenStream将输入的文本分成一系列标记,这些标记使用类似迭代器的模式进行检索。 TokenStream有两个子类: oal.analysis.Tokenizer和oal.analysis.TokenFilter 。 Tokenizer将java.io.Reader作为输入,而TokenFilter将另一个oal.analysis.TokenStream作为输入。 这使我们可以将令牌生成器链接在一起,以便初始令牌生成器从读取器获取其输入,其他令牌生成器则对链中先前TokenStream中的令牌进行操作。
oal.analysis.Analyzer在每个字段上为oal.analysis.Analyzer提供索引和搜索过程。 它将字段名称映射到令牌生成器,还可以为未知字段名称提供默认分析器。 Lucene包含许多分析模块,这些模块提供了各种分析仪的具体实现。 从Lucene 4开始,这些模块被捆绑到单独的jar文件中。 有几个特定语言的十几分析软件包,从oal.analysis.ar为阿拉伯语oal.analysis.tr土耳其。 软件包oal.analysis.core提供了几个通用分析器,令牌生成器和令牌生成器工厂类。
抽象类oal.analysis.Analyzer包含用于从输入文本中提取术语的方法。 Analyzer的具体子类必须重写方法createComponents ,该方法返回嵌套类TokenStreamComponents的对象,该对象定义令牌化过程并提供对处理管道的初始组件和文件组件的访问。 初始组件是处理输入源的Tokenizer。 最后一个组件是TokenFilter的一个实例,它是方法Analyzer.tokenStream(String,Reader)返回的TokenStream。 这是一个自定义分析器的示例,该分析器将其输入标记为单个单词(所有字母均小写)。
Analyzer analyzer = new Analyzer() {
@Override
protected TokenStreamComponents createComponents(String fieldName, Reader reader) {
Tokenizer source =
new StandardTokenizer(VERSION,reader);
TokenStream filter =
new LowerCaseFilter(VERSION,source);
return new TokenStreamComponents(source, filter);
}
}; oal.analysis.standard.StandardTokenizer和oal.analysis.core.LowerCaseFilter对象的构造函数需要一个Version参数。 还要注意,软件包oal.analysis.standard分布在jarfile lucene-analyzers-common-4.xyjar中,其中x和y是次要版本和发行版号。
我们应该使用哪个核心分析仪?
现在,我们已经看到了四个核心Lucene分析仪在工作方式上的实质性差异。 为我们的应用程序选择合适的分析仪会让我们感到惊讶:大多数应用程序不使用任何内置分析仪,而是选择创建自己的分析仪链。 对于那些确实使用核心分析器的应用程序,StandardAnalyzer可能是最常见的选择。 对于大多数应用程序而言,其余的核心分析器通常过于简单,除非特定的用例(例如,包含零件号列表的字段可能使用Whitespace-Analyzer)。 但是这些分析仪非常适合测试用例,并且确实被Lucene的单元测试大量使用。
通常,应用程序具有特定的需求,例如自定义停用词列表,对诸如零件号或同义词扩展之类的特定于应用程序的标记执行特殊的标记化,保留某些标记的大小写或选择特定的词干算法。
翻译自: https://www.javacodegeeks.com/2015/09/lucene-analysis-process-guide.html
lucene 源码分析















 121
121

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









