





redis分片
本文是我们学院课程的一部分,标题为Redis NoSQL键值存储 。
这是Redis的速成课程。 您将学习如何安装Redis和启动服务器。 此外,您还会在Redis命令行上乱七八糟。 接下来是更高级的主题,例如复制,分片和集群,同时还介绍了Redis与Spring Data的集成。 在这里查看 !
1.简介
我们每天处理的数据量呈指数级增长。 当必要的数据无法容纳在内存中,甚至物理存储空间不足时,我们经常面临单个设备的硬件限制。 多年来,这些问题导致业界开发了可以克服此类限制的数据分片(或数据分区)解决方案。
在Redis中,数据分片(分区)是一种在多个Redis实例之间拆分所有数据的技术,以便每个实例仅包含键的一个子集。 通过添加越来越多的实例并将数据划分为较小的部分(碎片或分区),这样的过程可以减轻数据的增长。 不仅如此,这还意味着越来越多的计算能力可用于处理数据,有效地支持水平缩放。
尽管并非所有解决方案都是双赢的,但仍需要权衡取舍:通过在多个实例之间拆分数据,查找特定键(或多个键)的问题成为一个问题。 这就是分片(分区)方案的用武之地:应该按照一些一致或固定的规则对数据进行分片(分区),以便对同一密钥的写入和读取操作应转到拥有(拥有)此密钥的Redis实例。
本教程的材料基于与分区和分区有关的出色Redis文档: http : //redis.io/topics/partitioning
2.何时使用分片(分区)
根据Redis文档( http://redis.io/topics/partitioning ),如果要执行以下操作,应考虑对数据进行分片(分区):
- 使用多台计算机的内存来管理更大的数据库(否则,您将受限于单台计算机可以支持的内存量)
- 扩展多个CPU,多个计算机的计算能力,并利用它们的网络带宽
如果您认为现在没有数据缩放问题,则可能会在不久的将来遇到此问题,因此最好做好准备并提前考虑(请参阅规划分片(分区) )。 但是在这样做之前,请考虑分片(分区)带来的复杂性和缺点:
- 通常不支持涉及多个键的操作。 例如,如果两个集合(
SINTER)存储在映射到不同Redis实例的键中,则不可能直接执行它们之间的交集。 - 涉及映射到不同Redis实例的多个密钥的事务是不可能的。
- 分区是基于键的,因此无法使用单个大键(很大的排序集或列表)对数据集进行分片(分区)。
- 备份和持久管理要复杂得多:您必须处理多个RDB / AOF文件,备份涉及来自许多实例的RDB文件的聚合(合并)。
- 除非您对此进行了计划,否则在运行时添加和删除实例可能会导致数据失衡(请参阅规划分片(分区) )。
3.分片(分区)方案
Redis可以使用几种经过战斗验证的分片(分区)方案,具体取决于您的数据模式。
- 范围划分
通过将对象范围映射到特定的Redis实例中来完成。 例如,假设我们正在存储一些用户数据,并且每个用户都有其唯一的标识符(ID)。 在我们的分区方案中,我们可以定义ID从0到10000的用户将进入实例Redis 1,而ID从10001到20000的用户将进入实例Redis 2,依此类推。 该方案的缺点是,范围和实例之间的映射应该被维护,并且应该与Redis中保留的对象(用户,产品等)的种类一样多的映射。 - 哈希分区
该方案适用于任何密钥,但涉及哈希函数 :此函数应将密钥名称映射到某个数字。 假设我们有这样一个函数(我们称其为hash_func),这样的方案就是这样的:- 取得键名,并使用
hash_func将其映射到数字
哈希函数的选择非常重要。 良好的哈希函数可确保密钥在所有Redis实例上平均分布,因此不会在任何单个实例上建立过多的密钥。
- 取得键名,并使用
- 一致性哈希
它是hash partitioning的一种高级形式,被许多解决方案用于数据分片(分区)。
4.分片(分区)实现
从实现的角度来看,根据应用程序的体系结构,有几种可能的数据分片(分区)实现:
- 客户端分区
客户端直接选择正确的实例来写入或读取给定的密钥。 - 代理辅助分区
客户端将请求发送到支持Redis协议的代理,而不是直接将请求发送到正确的Redis实例。 代理将确保根据配置的分区方案将请求转发到正确的Redis实例,并将答复发送回客户端(最著名的实现是Twitter的Twemproxy, https://github.com/twitter/ twemproxy )。 - 查询路由
客户端将查询发送到随机Redis实例,该实例将确保将查询转发到正确的实例。 查询路由的混合形式假定客户端被重定向到正确的实例(但是查询不会直接从一个Redis实例转发到另一个实例),并将在本教程的第5部分 Redis Clustering中进行介绍 。
5.规划分片(分区)
如前所述,一旦您开始在许多Redis实例之间使用数据分片(分区),则在运行时添加和删除实例可能会很困难。 您经常会在Redis中使用的一种技术被称为Presharding ( http://redis.io/topics/partitioning )。
预分片的想法是从一开始就以许多实例开始(但实际节点/服务器只有一个或很少数量)。 自开始以来,实例的数量可能会有所不同并且可能会很大(对于大多数用例而言,32或64个实例就足够了)。 由于Redis非常轻巧,因此完全有可能在单个服务器上运行64个Redis实例。
这样,随着数据存储需求的增长以及需要更多Redis节点/服务器来处理它,可以将实例从一台服务器简单地移动到另一台服务器。 例如,如果您有一台服务器并添加了另外一台服务器,则应将第一台服务器的一半Redis实例移至第二台服务器。 当每个服务器/节点上有一个Redis实例时,此技巧可能会一直持续下去。
但是要记住一件事:如果将Redis用作数据的内存缓存(而不是持久性数据存储),则可能不需要使用预分片。 一致的散列实现通常能够在运行时处理新的或删除的实例。 例如,如果给定密钥的首选实例不可用,则该密钥将被其他实例拾取。 或者,如果添加新实例,则新密钥的一部分将存储在该新实例上。
6.分片(分区)和复制
在许多实例之间分片(分区)数据并不能解决数据安全和冗余问题。 如果其中一个分片(分区)由于硬件故障而死亡,而您没有备份来还原数据,则意味着您将永远丢失数据。
这就是为什么分片(分区)与复制并存的原因。 如果将Redis用作持久性数据存储,则最好为不同服务器/节点上的每个分片(分区)配置至少一个副本。 这可能会使您的容量需求增加一倍,但确保数据安全就显得更为重要。
复制的配置与本教程第3部分“ Redis复制 ”中介绍的配置没有任何不同。
7.用Twemproxy进行分片(分区)
Twemproxy (也称为nutcracker )是由Twitter( https://github.com/twitter/twemproxy )开发和开源的,它是Redis的广泛使用,非常快速且轻量级的代理。 尽管它具有许多功能,但我们要介绍的功能与其向Redis添加分片(分区)的能力有关:
- 在多台服务器之间自动分片数据
- 支持多种哈希模式,包括一致的哈希和分布
Twemproxy ( nutcracker )非常易于安装和配置。 本教程的最新版本是0.3.0 ,可以从http://code.google.com/p/twemproxy/downloads/list下载。 安装非常简单。
- 下载
wget http://twemproxy.googlecode.com/files/nutcracker-0.3.0.tar.gz - 解压缩档案
tar xfz nutcracker-0.3.0.tar.gz - 构建(您需要的唯一预装软件包是
gcc和make)。cd nutcracker-0.3.0 ./configure make - 安装
sudo make install
默认情况下, twemproxy ( nutcracker )将位于/usr/local/sbin/nutcracker 。 安装后,最重要(但是非常简单)的部分是其配置。
Twemproxy ( nutcracker )使用YAML作为配置文件格式( http://www.yaml.org/ )。 在twemproxy ( nutcracker )支持的许多设置中,我们将选择与分片(分区)相关的设置。
| 设置 | 听:名称:端口| ip:端口 |
| 描述 | 此服务器池的侦听地址和端口( name:port或ip:port )。 |
| 例 | 听:127.0.0.1:22121 |
表格1
| 设置 | 哈希:<功能> |
| 描述 | 哈希函数的名称。 可能的值为: - 一次一个 – md5( http://en.wikipedia.org/wiki/MD5 ) – crc16( http://en.wikipedia.org/wiki/Cyclic_redundancy_check ) – crc32(与libmemcached兼容的crc32实现) – crc32a(根据规范正确的crc32实现) – fnv1_64( http://en.wikipedia.org/wiki/Fowler–Noll–Vo_hash_function ) – fnv1a_64( http://en.wikipedia.org/wiki/Fowler-Noll-Vo_hash_function ) – fnv1_32( http://en.wikipedia.org/wiki/Fowler–Noll–Vo_hash_function ) – fnv1a_32( http://en.wikipedia.org/wiki/Fowler–Noll–Vo_hash_function ) – hsieh( http://www.azillionmonkeys.com/qed/hash.html ) |
| 例 | 杂凑:fnv1a_64 |
表2
| 设置 | 分布:<模式> |
| 描述 | 密钥分发模式(请参阅http://en.wikipedia.org/wiki/Consistent_hashing )。 可能的值为: –凯塔玛 –模数 –随机 |
| 例 | 分布:ketama |
表3
| 设置 | redis:是|否 |
| 描述 | 一个布尔值,它控制服务器池是否使用Redis或Memcached协议。 由于我们将仅使用Redis,因此此设置应设置为true 。 默认为false 。 |
| 例 | redis:是的 |
表4
| 设置 | auto_eject_hosts:true | 假 |
| 描述 | 一个布尔值,它控制服务器连续失败server_failure_limit次后是否应暂时退出服务器。 默认为false 。 |
| 例 | auto_eject_hosts:否 |
表5
| 设置 | server_retry_timeout:<毫秒> |
| 描述 | 当auto_eject_host设置为true时,在临时弹出的服务器上重试之前等待的超时值(以毫秒为单位)。 默认值为30000毫秒。 |
| 例 | server_retry_timeout:30000 |
表6
| 设置 | server_failure_limit:<数字> |
| 描述 | 当auto_eject_host设置为true时,服务器上导致其暂时退出的连续失败次数。 默认为2 。 |
| 例 | server_failure_limit:2 |
表7
| 设置 | 服务器: – 名称:端口:重量| ip:端口:重量 – 名称:端口:重量| ip:端口:重量 |
| 描述 | 特定服务器池的服务器地址,端口和权重( name:port:weight或ip:port:weight)的列表。 |
| 例 | 服务器: – 127.0.0.1:6379:1 – 127.0.0.1:6380:1 |
表8
我们将使用三个Redis实例(服务器池)构建一个简单的拓扑,并在它们前面配置twemproxy ( nutcracker ),如下图所示:
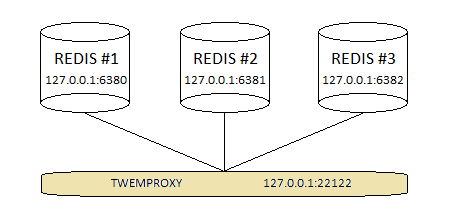
图1. Twemproxy和Redis服务器池配置由三个实例组成
twemproxy ( nutcracker )发行版中的conf/nutcracker.yml文件是寻找不同配置示例的良好起点。 至于示范,我们将与下面开始sharded服务器池,反映了上面显示的拓扑结构。
文件nutcracker-sharded.yml :
sharded:
listen: 127.0.0.1:22122
hash: fnv1a_64
distribution: ketama
auto_eject_hosts: true
redis: true
server_retry_timeout: 2000
server_failure_limit: 2
servers:
- 127.0.0.1:6380:1
- 127.0.0.1:6381:1
- 127.0.0.1:6382:1 在sharded服务器池使用ketama与关键散列器设置为密钥分发一致性哈希fnv1a_64 。
在开始之前twemproxy ( nutcracker ),我们应该有三个Redis的情况下,并在端口6380,6381和6382上运行。
redis-server --port 6380
redis-server --port 6381
redis-server --port 6382 之后,可以使用以下命令启动带有示例配置的twemproxy ( nutcracker )实例:
nutcracker -c nutcracker-sharded.yml
图2. Twemproxy(胡桃夹子)已成功启动
验证分片(分区)操作的最简单方法是连接到twemproxy ( nutcracker ),存储一对键/值对,然后尝试从每个Redis实例中获取所有存储的键:每个键应返回一个且只有一个例如,其他人应该返回( nil )。 虽然,从twemproxy ( nutcracker )查询相同的键将始终twemproxy先前存储的值。 根据我们的样本配置, twemproxy ( nutcracker )正在侦听端口22122 ,可以使用常规redis-cli工具进行连接。 三个键userkey , somekey和anotherkey将设置为一些值。
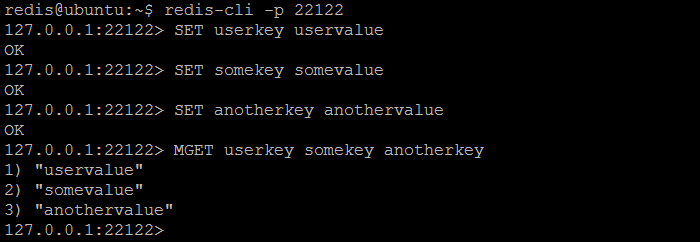
图3.在Twemproxy(胡桃夹子)中设置几个键/值对并验证它们是否已存储
现在,如果我们从twemproxy ( nutcracker )服务器池中查询每个单独的Redis实例,则某些实例(而不是其他实例)将解析某些键( userkey , somekey , anotherkey )。
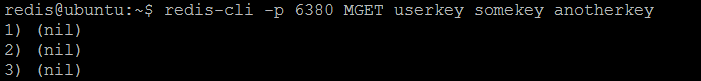
图4. Redis#1没有存储密钥

图5. Redis的#2仅具有一个键userkey存储
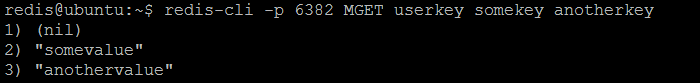
图6. Redis#3有两个一个密钥,一个是somekey , anotherkey另一个key
可能会提出一个有趣的问题:为什么密钥以这种方式存储? 答案是配置的hash function :密钥在服务器池中的所有Redis实例中一致地分布。 但是,为了获得平衡(均匀或随机)的分布,应根据应用程序使用的键命名模式非常仔细地选择配置的hash function 。 如我们的示例所示,密钥并非在所有实例中均匀分布(第一个实例没有任何内容,第二个实例有一个密钥,第三个实例有两个密钥)。
最后的注意事项:尽管twemproxy ( nutcracker )确实支持Redis协议,但由于“ 何时使用分片(分区)”部分中讨论的限制,因此不支持所有命令。
有关twemproxy ( nutcracker )的更多详细信息,请参阅https://github.com/twitter/twemproxy ,它提供了许多不错的最新文档。
8.接下来
在本节中,我们仅介绍了一种如何在Redis中处理分片(分区)的方法。 接下来的第5部分 , Redis群集 ,我们将发现替代解决方案。
翻译自: https://www.javacodegeeks.com/2015/09/redis-sharding.html
redis分片















 472
472

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









