






 这篇博客介绍了一个使用Dropwizard、MongoDB和Gradle构建的小项目,旨在实现带缓冲区的计数器,以减少延迟。博主探讨了Guava缓存、MongoDB集成、嵌入式MongoDB在Gradle中的使用以及Dropwizard健康检查等功能。文章提供了一个实验性的解决方案,并分享了源代码链接。
这篇博客介绍了一个使用Dropwizard、MongoDB和Gradle构建的小项目,旨在实现带缓冲区的计数器,以减少延迟。博主探讨了Guava缓存、MongoDB集成、嵌入式MongoDB在Gradle中的使用以及Dropwizard健康检查等功能。文章提供了一个实验性的解决方案,并分享了源代码链接。
mongodb实验报告
介绍
我使用Dropwizard,MongoDB和Gradle创建了一个小项目。 它实际上是作为一个实验性的Guava缓存开始的,作为将计数器发送到MongoDB(或任何其他DB)的缓冲区。 我也想尝试MondleDB插件的Gradle。 接下来,我想创建某种界面来检查此框架,因此我决定尝试使用DropWizard。 这就是这个项目的创建方式。
本文不是使用任何选定技术的教程。 这是一个小展示柜,我做过实验。 我猜有一些缺陷,也许我没有使用所有“最佳实践”。 但是,我确实相信,在本文的帮助下,该项目可以成为我使用的各种技术的良好起点。 我还尝试显示一些设计选择,这些选择有助于实现SRP,去耦,内聚等。
我决定从用例描述及其实现方式开始。 之后,我将解释我对Gradle,MongoDB(和嵌入式)和Dropwizard所做的工作。
在开始之前,这里是源代码:
用例:带缓冲区的计数器
我们对服务器有一些输入请求。 在请求过程中,我们选择用一些数据(由某些逻辑决定)“绘制”它。 有些请求将由Value-1绘制,某些请求将由Value-2绘制,等等。有些将根本不会绘制。 我们要限制绘画请求的数量(每个绘画值)。 为了有限制,对于每个绘制值,我们知道最大值,但是还需要计算(每个绘制值)绘制请求的数量。 由于系统具有多个服务器,因此计数器应由所有服务器共享。
延迟至关重要。 通常,每个请求处理会得到4-5毫秒(对于所有流程。不仅仅是绘画)。 因此,我们不希望增加计数器会增加延迟。 相反,我们将保留一个缓冲区,客户端将向缓冲区发送“增加”。 缓冲区将定期以“批量增量”增加存储库。
我知道可以直接使用Hazelcast或Couchbase或其他类似的快速内存数据库。 但是对于我们的用例,那是最好的解决方案。
原理很简单:
- 从属模块将调用服务以增加某个密钥的计数器
- 该实现为每个键保留一个计数器缓冲区
- 这是线程安全的
- 编写在单独的线程中进行
- 每次写入都会大量增加
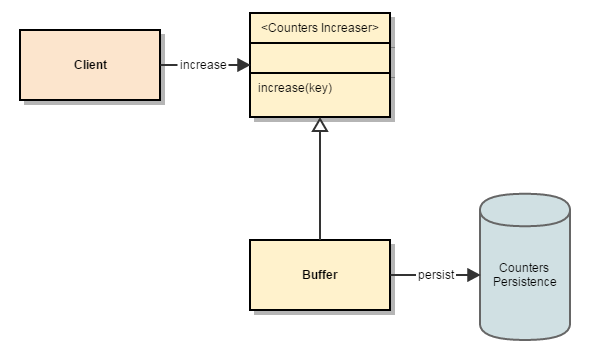
柜台高级设计
缓冲
对于缓冲区,我使用了Google Guava 缓存 。
缓冲结构
创建缓冲区:
private final LoadingCache<Counterable, BufferValue> cache;
...
this.cache = CacheBu 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2199
2199

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









