





apache hive
这篇文章介绍了如何使用Apache Hive查询Hadoop下存储的搜索点击数据。 我们将以示例的形式生成有关总产品浏览量的客户最爱搜索查询和统计信息。
继续之前的文章
我们已经有使用Flume在Hadoop HDFS中收集的客户搜索点击数据。
这里将进一步分析使用Hive在Hadoop下查询存储的数据。
蜂巢
Hive允许我们使用类似SQL的语言HiveQL查询大数据。
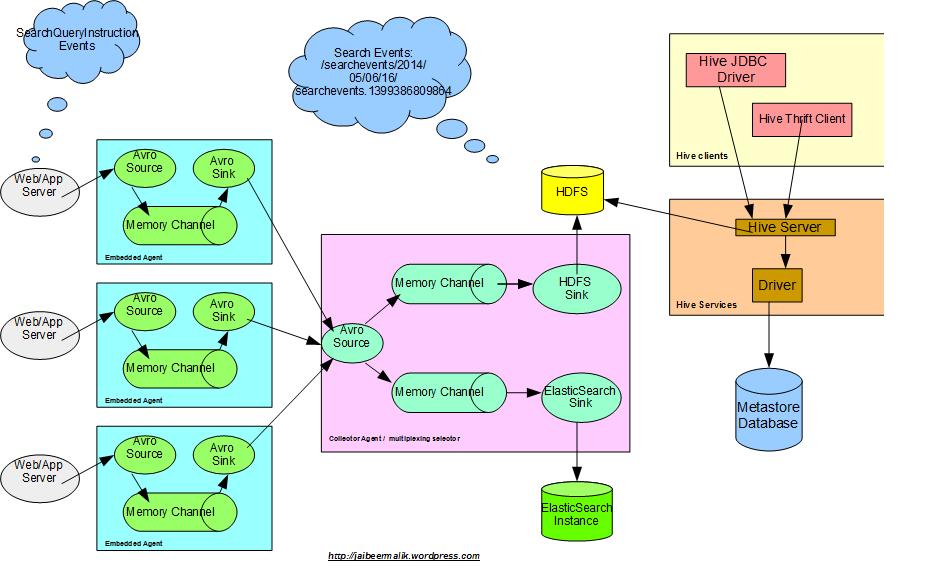
Hadoop数据
正如上一篇文章中分享的那样,我们具有以以下格式“ / searchevents / 2014/05/15/16 /”存储在hadoop下的搜索点击数据。 数据存储在每小时创建的单独目录中。
文件创建为:
hdfs://localhost.localdomain:54321/searchevents/2014/05/06/16/searchevents.1399386809864数据存储为DataSteam:
{"eventid":"e8470a00-c869-4a90-89f2-f550522f8f52-1399386809212-72","hostedmachinename":"192.168.182.1334","pageurl":"http://jaibigdata.com/0","customerid":72,"sessionid":"7871a55c-a950-4394-bf5f-d2179a553575","querystring":null,"sortorder":"desc","pagenumber":0,"totalhits":8,"hitsshown":44,"createdtimestampinmillis":1399386809212,"clickeddocid":"23","favourite":null,"eventidsuffix":"e8470a00-c869-4a90-89f2-f550522f8f52","filters":[{"code":"searchfacettype_brand_level_2","value":"Apple"},{"code":"searchfacettype_color_level_2","value":"Blue"}]}
{"eventid":"2a4c1e1b-d2c9-4fe2-b38d-9b7d32feb4e0-1399386809743-61","hostedmachinename":"192.168.182.1330","pageurl":"http://jaibigdata.com/0","customerid":61,"sessionid":"78286f6d-cc1e-489c-85ce-a7de8419d628","querystring":"queryString59","sortorder":"asc","pagenumber":3,"totalhits":32,"hitsshown":9,"createdtimestampinmillis":1399386809743,"clickeddocid":null,"favourite":null,"eventidsuffix":"2a4c1e1b-d2c9-4fe2-b38d-9b7d32feb4e0","filters":[{"code":"searchfacettype_age_level_2","value":"0-12 years"}]}Spring数据
我们将使用Spring for Apache Hadoop通过Spring运行配置单元作业。 要在您的应用程序中设置hive环境,请使用以下配置:
<hdp:configuration id="hadoopConfiguration"
resources="core-site.xml">
fs.default.name=hdfs://localhost.localdomain:54321
mapred.job.tracker=localhost.localdomain:54310
</hdp:configuration>
<hdp:hive-server auto-startup="true" port="10234" min-threads="3" id="hiveServer" configuration-ref="hadoopConfiguration">
</hdp:hive-server>
<hdp:hive-client-factory id="hiveClientFactory" host="localhost" port="10234">
</hdp:hive-client-factory>
<hdp:hive-runner id="hiveRunner" run-at-startup="false" hive-client-factory-ref="hiveClientFactory">
</hdp:hive-runner>检查Spring上下文文件applicationContext-elasticsearch.xml以获得更多详细信息。 我们将使用hiveRunner运行hive脚本。
应用程序中的所有配置单元脚本都位于资源配置单元文件夹下。
可以在HiveSearchClicksServiceImpl.java中找到运行所有hive脚本的服务。
设置数据库
让我们设置数据库以首先查询数据。
DROP DATABASE IF EXISTS search CASCADE;
CREATE DATABASE search;使用外部表查询搜索事件
我们将创建一个外部表search_clicks来读取hadoop下存储的搜索事件数据。
USE search;
CREATE EXTERNAL TABLE IF NOT EXISTS search_clicks (eventid String, customerid BIGINT, hostedmachinename STRING, pageurl STRING, totalhits INT, querystring STRING, sessionid STRING, sortorder STRING, pagenumber INT, hitsshown INT, clickeddocid STRING, filters ARRAY<STRUCT<code:STRING, value:STRING>>, createdtimestampinmillis BIGINT) PARTITIONED BY (year STRING, month STRING, day STRING, hour STRING) ROW FORMAT SERDE 'org.jai.hive.serde.JSONSerDe' LOCATION 'hdfs:///searchevents/';JSONSerDe
自定义SerDe“ org.jai.hive.serde.JSONSerDe”用于映射json数据。 检查同一JSONSerDe.java的更多详细信息
如果您是从Eclipse本身运行查询,则依赖关系将自动解决。 如果您是从hive控制台运行的,请确保在运行hive查询之前为该类创建一个jar文件,并将该类的相关依赖项添加到hive控制台。
#create hive json serde jar
jar cf jaihivejsonserde-1.0.jar org/jai/hive/serde/JSONSerDe.class
# run on hive console to add jar
add jar /opt/hive/lib/jaihivejsonserde-1.0.jar;
# Or add jar path to hive-site.xml file permanently
<property>
<name>hive.aux.jars.path</name>
<value>/opt/hive/lib/jaihivejsonserde-1.0.jar</value>
</property>创建配置单元分区
我们将使用配置单元分区策略读取分层位置下hadoop中存储的数据。 根据上述位置“ / searchevents / 2014/05/06/16 /”,我们将传递以下参数值(DBNAME =搜索,TBNAME = search_clicks,YEAR = 2014,MONTH = 05,DAY = 06,HOUR = 16)。
USE ${hiveconf:DBNAME};
ALTER TABLE ${hiveconf:TBNAME} ADD IF NOT EXISTS PARTITION(year='${hiveconf:YEAR}', month='${hiveconf:MONTH}', day='${hiveconf:DAY}', hour='${hiveconf:HOUR}') LOCATION "hdfs:///searchevents/${hiveconf:YEAR}/${hiveconf:MONTH}/${hiveconf:DAY}/${hiveconf:HOUR}/";要运行脚本,
Collection<HiveScript> scripts = new ArrayList<>();
Map<String, String> args = new HashMap<>();
args.put("DBNAME", dbName);
args.put("TBNAME", tbName);
args.put("YEAR", year);
args.put("MONTH", month);
args.put("DAY", day);
args.put("HOUR", hour);
HiveScript script = new HiveScript(new ClassPathResource("hive/add_partition_searchevents.q"), args);
scripts.add(script);
hiveRunner.setScripts(scripts);
hiveRunner.call();在后面的文章中,我们将介绍如何使用Oozie协调器作业为小时数据自动创建配置单元分区。
获取所有搜索点击事件
获取存储在外部表search_clicks中的搜索事件。 传递以下参数值(DBNAME =搜索,TBNAME = search_clicks,YEAR = 2014,MONTH = 05,DAY = 06,HOUR = 16)。
USE ${hiveconf:DBNAME};
select eventid, customerid, querystring, filters from ${hiveconf:TBNAME} where year='${hiveconf:YEAR}' and month='${hiveconf:MONTH}' and day='${hiveconf:DAY}' and hour='${hiveconf:HOUR}';这将返回指定位置下的所有数据,还可以帮助您测试自定义SerDe。
查找最近30天内的商品视图
最近n天中浏览/点击产品的次数。
Use search;
DROP TABLE IF EXISTS search_productviews;
CREATE TABLE search_productviews(id STRING, productid BIGINT, viewcount INT);
-- product views count in the last 30 days.
INSERT INTO TABLE search_productviews select clickeddocid as id, clickeddocid as productid, count(*) as viewcount from search_clicks where clickeddocid is not null and createdTimeStampInMillis > ((unix_timestamp() * 1000) - 2592000000) group by clickeddocid order by productid;要运行脚本,
Collection<HiveScript> scripts = new ArrayList<>();
HiveScript script = new HiveScript(new ClassPathResource("hive/load-search_productviews-table.q"));
scripts.add(script);
hiveRunner.setScripts(scripts);
hiveRunner.call();样本数据,从“ search_productviews”表中选择数据。
# id, productid, viewcount
61, 61, 15
48, 48, 8
16, 16, 40
85, 85, 7查找过去30天内的Cutomer热门查询
Use search;
DROP TABLE IF EXISTS search_customerquery;
CREATE TABLE search_customerquery(id String, customerid BIGINT, querystring String, querycount INT);
-- customer top query string in the last 30 days
INSERT INTO TABLE search_customerquery select concat(customerid,"_",queryString), customerid, querystring, count(*) as querycount from search_clicks where querystring is not null and customerid is not null and createdTimeStampInMillis > ((unix_timestamp() * 1000) - 2592000000) group by customerid, querystring order by customerid;样本数据,从“ search_customerquery”表中选择数据。
# id, querystring, count, customerid
61_queryString59, queryString59, 5, 61
298_queryString48, queryString48, 3, 298
440_queryString16, queryString16, 1, 440
47_queryString85, queryString85, 1, 47分析构面/过滤器以进行导航
您可以进一步扩展Hive查询,以生成有关最终客户在使用构面/过滤器搜索相关产品时的行为表现的统计信息。
USE search;
-- How many times a particular filter has been clicked.
select count(*) from search_clicks where array_contains(filters, struct("searchfacettype_color_level_2", "Blue"));
-- how many distinct customer clicked the filter
select DISTINCT customerid from search_clicks where array_contains(filters, struct("searchfacettype_color_level_2", "Blue"));
-- top query filters by a customer
select customerid, filters.code, filters.value, count(*) as filtercount from search_clicks group by customerid, filters.code, filters.value order by filtercount DESC limit 100;数据提取Hive查询可以根据需求按夜/小时计划,并且可以使用作业计划程序(如Oozie)执行。 该数据可以进一步用于BI分析或改善客户体验。
在以后的文章中,我们将介绍进一步分析生成的数据,
- 使用ElasticSearch Hadoop为客户最重要的查询和产品视图数据编制索引
- 使用Oozie计划针对配置单元分区进行协调的作业,并将作业捆绑以将数据索引到ElasticSearch。
- 使用Pig来计算唯一客户总数等
apache hive















 214
214

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









