





java编译器分析
简单地说,反编译器尝试将源代码转换为目标代码。 但是有很多有趣的复杂性-Java源代码是结构化的; 字节码当然不是。 而且,转换不是一对一的:两个不同的Java程序可能会产生相同的字节码。 我们需要应用试探法以合理地近似原始来源。
(微小的)字节码刷新器
为了了解反编译器的工作原理,有必要了解字节码的基础知识。 如果您已经熟悉字节码,请随时跳到下一部分。
JVM是基于堆栈的计算机 (与基于寄存器的计算机相对),这意味着指令在评估堆栈上运行。 可以从堆栈弹出操作数,执行各种操作,然后将结果推回堆栈以进行进一步评估。 请考虑以下方法:
public static int plus(int a, int b) {
int c = a + b;
return c;
} 注意:本文显示的所有字节码都是从javap输出的,例如javap -c -p MyClass 。
public static int plus(int, int);
Code:
stack=2, locals=3, arguments=2
0: iload_0 // load ‘x’ from slot 0, push onto stack
1: iload_1 // load ‘y’ from slot 1, push onto stack
2: iadd // pop 2 integers, add them together, and push the result
3: istore_2 // pop the result, store as ‘sum’ in slot 2
4: iload_2 // load ‘sum’ from slot 2, push onto stack
5: ireturn // return the integer at the top of the stack(为清楚起见添加了注释。)
方法的局部变量(包括该方法的参数)存储在JVM所谓的局部变量数组中 。 为了简洁起见,我们将存储在本地变量数组中位置#x的值(或引用)称为“插槽#x”(请参阅JVM规范§3.6.1 )。
对于实例方法,插槽#0中的值始终是this指针。 然后从左到右依次是方法参数,然后是方法中声明的所有局部变量。 在上面的示例中,该方法是静态的,因此没有this指针。 插槽#0保留参数x ,插槽#1保留参数y 。 局部变量sum驻留在插槽#2中。
有趣的是,每种方法都具有最大堆栈大小和最大局部变量存储量,这两者都是在编译时确定的。
从这里立即显而易见的一件事是您最初可能不会想到的,那就是编译器没有尝试优化代码。 实际上, javac几乎从不发出优化的字节码。 这有很多好处,包括在大多数位置设置断点的能力:如果我们要消除冗余的加载/存储操作,我们将失去该能力。 因此,大部分繁重的工作都是由即时(JIT)编译器在运行时执行的。
反编译
因此,如何获取基于栈的非结构化字节码并将其转换回结构化Java代码? 第一步通常是摆脱操作数堆栈,我们可以通过将堆栈值映射到变量并插入适当的加载和存储操作来做到这一点。
“堆栈变量”仅分配一次,并且消耗一次。 您可能会注意到,这将导致很多冗余变量-稍后再介绍! 反编译器也可以将字节码简化为更简单的指令集,但是在此我们不考虑。
我们将使用符号s0 (等)表示堆栈变量 ,使用v0表示原始字节码中引用的真实局部变量(并存储在插槽中)。
| 字节码 | 堆栈变量 | 复制传播 | |
|---|---|---|---|
| 0 1个 2 3 4 5 | iload_0 iload_1 我加 istore_2 iload_2 我回来 | s0 = v0 s1 = v1 s2 = s0 + s1 v2 = s2 s3 = v2 返回s3 | v2 = v0 + v1 返回v2 |
通过将标识符分配给每个被推入或弹出的值,我们可以从字节码到变量 ,例如, iadd弹出两个操作数以进行加和推结果。
然后,我们应用一种称为复制传播的技术来消除一些冗余变量。 复制传播是一种内联形式,其中只要对转换有效,就可以简单地将对变量的引用替换为指定的值。
我们所说的“有效”是什么意思? 好吧,这里有一些重要的限制。 考虑以下:
0: s0 = v1
1: v1 = s4
2: v2 = s0 <-- s0 cannot be replaced with v1 在这里,如果我们用v0替换s0 ,则行为将发生变化,因为v0的值在分配s0之后但被消耗之前发生变化。 为了避免这些复杂性,我们仅将复制传播用于仅分配一次的内联变量。
强制执行的一种方式可能是追踪所有门店非堆栈变量,即,我们知道, v1在#0分配V1 0,并且还V1 1在#2。 由于对v1有多个分配,因此我们无法执行复制传播。
但是,我们最初的示例没有这种复杂性,最终我们得到了一个简洁明了的结果:
v2 = v0 + v1
return v2另外:恢复变量名
如果将变量简化为字节码中的插槽引用,那么如何恢复原始变量名? 有可能我们做不到。 为了改善调试体验,每种方法的字节码可能包括一个称为局部变量表的特殊部分。 对于原始源中的每个变量,都存在一个条目,用于指定名称,插槽号和名称所适用的字节码范围。 通过包含-v选项,可以将该表(以及其他有用的元数据)包含在javap反汇编中。 对于上面的plus()方法,该表如下所示:
Start Length Slot Name Signature
0 6 0 a I
0 6 1 b I
4 2 2 c I 在这里,我们看到v2指的是原始变量' c ',其字节码偏移量为#4-5。
对于已编译而没有局部变量表的类(或被混淆器剥离的类),我们必须生成自己的名称。 有很多策略可以做到这一点。 一个聪明的实现可能会看一看如何将变量用于适当名称的提示。
堆栈分析
在前面的示例中,我们可以保证在任何给定点上哪个值位于堆栈的顶部,因此我们可以命名为s0 , s1等。
到目前为止,处理变量非常简单,因为我们只探索了单个代码路径的方法。 在现实世界的应用程序中,大多数方法都不会那么适应。 每次向方法添加循环或条件时,都会增加调用者可能采用的路径数量。 考虑我们先前示例的修改版本:
public static int plus(boolean t, int a, int b) {
int c = t ? a : b;
return c;
}现在我们有了控制流程来使事情复杂化。 如果尝试执行与以前相同的任务,则会遇到问题。
| 字节码 | 堆栈变量 | |
|---|---|---|
| 0 1个 4 5 8 9 10 11 | iload_0 ifeq 8 iload_1 转到9 iload_2 istore_3 iload_3 我回来 | s0 = v0 如果(s0 == 0)转到#8 s1 = v1 转到#9 s2 = v2 v3 = {s1,s2} s4 = v3 返回s4 |
我们需要更加聪明地分配堆栈标识符。 单独考虑每条指令已不再足够; 我们需要跟踪堆栈在任何给定位置的外观,因为我们可能会采用多种路径到达该位置。
当我们检查#9 ,我们看到istore_3弹出一个值,但是该值有两个来源:它可能起源于#5或#8 。 堆栈顶部#9处的值可能是s1或s2 ,这取决于我们分别来自#5还是#8 。 因此,我们需要将它们视为相同的变量-我们将它们合并,并且对s1或s2所有引用都将成为对明确变量s{1,2}引用。 进行“重新标记”后,我们可以安全地执行复制传播。
| 重新贴标签后 | 复制后 | |
|---|---|---|
| 0 1个 4 5 8 9 10 11 | s0 = v0 如果(s0 == 0)转到#8 s {1,2} = v1 转到#9 s {1,2} =:v2 v3 = s {1,2} s4 = v3 返回s4 | 如果(v0 == 0)转到#8 s {1,2} = v1 转到#9 s {1,2} = v2 v3 = s {1,2}返回v3 |
注意条件分支在#1 :如果s0的值为零,我们跳转到else块; else ,跳转到else块。 否则,我们将沿着当前路径继续。 有趣的是,与原始来源相比,测试条件被否定了。
现在,我们已经涵盖了足够的内容,可以深入……
条件表达式
在这一点上,我们可以确定我们的代码可以使用三元运算符( ?: :)进行建模:我们有一个条件,每个分支对同一堆栈变量s {1,2}具有单个赋值,此后两个路径会聚。
一旦确定了这种模式,就可以立即将三元数向上滚动。
| 复制属性后。 | 折叠三元 | |
|---|---|---|
| 0 1个 4 5 8 9 10 11 | 如果(v0 == 0)转到#8 s {1,2} = v1 转到9 s {1,2} = v2 v3 = s {1,2}返回v3 | v3 = v0!= 0 v1:v2 返回v3 |
请注意,作为转换的一部分,我们否定了#9的条件。 事实证明, javac否定条件的方式是相当可预测的,因此,如果将条件翻转回去,我们可以更紧密地匹配原始源。
除了–但是类型是什么?
在处理堆栈值时,JVM使用的类型系统比Java源代码更简单。 具体来说, boolean , char和short值使用与int值相同的指令进行操作。 因此,比较v0 != 0可以解释为:
v0 != false ? v1 : v2…要么:
v0 != 0 ? v1 : v2…甚至:
v0 != false ? v1 == true : v2 == true…等等!
但是,在这种情况下,我们很幸运地知道v0的确切类型,因为它包含在方法描述符中 :
descriptor: (ZII)I
flags: ACC_PUBLIC, ACC_STATIC这告诉我们方法签名的形式为:
public static int plus(boolean, int, int) 我们还可以推断v3应该是一个int (而不是boolean ),因为它被用作返回值,并且描述符告诉我们返回类型。 然后我们剩下:
v3 = v0 ? v1 : v2
return v3 v0一句,如果v0是局部变量(而不是形式参数),那么我们可能不知道它表示boolean值而不是int 。 还记得我们前面提到的局部变量表,它告诉我们原始变量名吗? 它还包含有关变量类型的信息 ,因此,如果将编译器配置为发出调试信息,我们可以在该表中查找类型提示。 还有另一个类似的表,称为LocalVariableTypeTable ,其中包含类似的信息。 主要区别在于LocalVariableTypeTable可能包含有关泛型类型的详细信息,而LocalVariableTable无法。 值得注意的是,这些表是未经验证的元数据,因此它们不一定是可信赖的 。 一个特别狡猾的混淆器可能会选择用谎言填充这些表,并且生成的字节码仍然有效! 自行决定使用它们。
短路运算符(
public static boolean fn(boolean a, boolean b, boolean c){
return a || b && c;
}怎么会更简单? 不幸的是,字节码有点麻烦……
| 字节码 | 堆栈变量 | 复制后 | |
|---|---|---|---|
| 0 1个 4 5 8 9 12 13 16 17 | iload_0 ifne#12 iload_1 ifeq#16 iload_2 ifeq#16 iconst_1 转到#17 iconst_0 我回来 | s0 = v0 如果(s0!= 0)转到#12 s1 = v1 如果(s1 == 0)转到#16 s2 = v2 如果(s2 == 0)转到#16 s3 = 1 转到17 s4 = 0 返回s {3,4} | 如果(v0!= 0)转到#12如果(v1 == 0)转到#16 如果(v2 == 0)转到#16 |
#17的ireturn指令可能会返回s3或s4 ,这取决于所采用的路径。 我们如上所述对它们进行别名处理,然后执行复制传播以消除s0 , s1和s2 。
我们在#1 , #5和#7处拥有三个连续的条件。 正如我们前面提到的,条件分支跳转或落入下一条指令。
上面的字节码包含遵循特定且非常有用的模式的条件分支序列:
| 条件连词(&&) | 条件析取(||) |
|---|---|
| |
如果我们考虑上面的相邻条件对,则#1...#5不符合以下任何一种模式,但是#5...#9是条件析取( || ),因此我们应用适当的变换:
1: if (v0 != 0) goto #12
5: if (v1 == 0 || v2 == 0) goto #16
12: s{3,4} = 1
13: goto #17
16: s{3,4} = 0
17: return s{3,4} 请注意,我们应用的每个转换都可能创造机会执行其他转换。 在这种情况下,应用|| transform重组了我们的条件,现在#1...#5符合&&模式! 因此,我们可以通过将这些行合并为单个条件分支来进一步简化该方法:
1: if (v0 == 0 && (v1 == 0 || v2 == 0)) goto #16
12: s{3,4} = 1
13: goto #17
16: s{3,4} = 0
17: return s{3,4} 这看起来很熟悉吗? 它应该:该字节码现在符合我们前面介绍的三元( ?: :)运算符模式。 我们可以将#1...#16简化为单个表达式,然后使用复制传播将s{3,4}内联到#17的return语句中:
return (v0 == 0 && (v1 == 0 || v2 == 0)) ? 0 : 1;使用前面描述的方法描述符和局部变量类型表,我们可以推断出将该表达式简化为的所有必要类型:
return (v0 == false && (v1 == false || v2 == false)) ? false : true; 好吧,这当然比我们最初的反编译更简洁,但仍然很麻烦。 让我们看看我们能做些什么。 我们可以先折叠x和!x比较,例如x == true和x == false 。 我们也可以通过减少x ? false : true来消除三元运算符x ? false : true x ? false : true与简单表达式!x 。
return !(!v0 && (!v1 || !v2));更好,但是仍然很少。 如果您还记得高中离散数学,那么可以看到De Morgan定理可以在这里应用:
!(a || b) --> (!a) && (!b)
!(a && b) --> (!a) || (!b)因此:
return ! ( !v0 && ( !v1 || !v2 ) )…成为:
return ( v0 || !(!v1 || !v2 ) )…最终:
return ( v0 || (v1 && v2) )欢呼!
处理方法调用
我们已经了解了一种方法的外观:在locals数组中将参数“到达”。 要调用方法,必须将参数压入堆栈,对于例如方法,此参数必须紧跟this指针。 正如您所期望的那样,以字节码调用方法:
push arg_0
push arg_1
invokevirtual METHODREF 我们在上面指定了invokevirtual ,这是用于调用大多数实例方法的指令。 JVM实际上有一些用于方法调用的指令,每个指令具有不同的语义:
-
invokeinterface调用接口方法。 -
invokevirtual使用虚拟语义调用实例方法,即,根据目标的运行时类型将调用分派到适当的替代。 -
invokespecial调用会调用特定的实例方法(不带虚拟语义); 它最常用于调用构造函数,但也用于super.method()类的调用。 -
invokestatic调用静态方法。 -
invokedynamic是最不常见的(在Java中),它使用“ bootstrap”方法来调用自定义调用站点绑定程序。 创建它是为了改善对动态语言的支持,并且已在Java 8中用于实现lambda。
对于反编译器编写器,重要的细节是该类的常量池包含有关任何所调用方法的详细信息,包括其参数的数量和类型以及其返回类型。 在调用程序类中记录此信息,可以使运行时验证运行时是否存在预期的方法,并且该方法符合预期的签名。 如果目标方法在第三方代码中,并且其签名发生了变化,则任何尝试调用旧版本的代码都将引发错误(与产生未定义行为相反)。
回到上面的示例, invokevirtual操作码的存在告诉我们目标方法是实例方法 ,因此需要this指针作为隐式第一个参数。 常量池中的METHODREF告诉我们该方法具有一个形式参数,因此我们知道除了目标实例指针外,还需要从堆栈中弹出一个参数。 然后,我们可以将代码重写为:
arg_0.METHODREF(arg_1)当然,字节码并不总是那么友好。 不需要将堆栈参数整齐地推入堆栈,一个接一个地推。 例如,如果参数之一是三元表达式,则将存在需要独立转换的中间加载,存储和分支指令。 混淆器可能会将方法重写为特别复杂的指令序列。 一个好的反编译器将需要足够灵活,以处理超出本文范围的许多有趣的极端情况。
不仅限于此……
到目前为止,我们仅限于分析单个代码序列,首先是一系列简单的指令,然后应用产生更熟悉的高级结构的转换。 如果您认为这似乎过于简单,那么您是正确的。 Java是一种高度结构化的语言,具有诸如范围和块之类的概念以及更复杂的控制流机制。 为了处理诸如if/else块和循环之类的构造,我们需要对代码进行更严格的分析,并特别注意可能采用的各种路径。 这称为控制流分析 。
我们首先将代码分解为可以从头到尾执行的连续块。 这些被称为基本块 ,我们通过沿着可能跳转到另一个块的地方以及可能成为跳转目标的任何指令拆分指令列表来构造它们。
然后,我们通过在块之间创建代表所有可能分支的边来建立控制流程图 (CFG)。 请注意,这些边缘可能不是显式分支; 包含可能引发异常的指令的块将连接到它们各自的异常处理程序。 我们不会详细介绍如何构造CFG,但是需要一些高级知识才能理解我们如何使用这些图来检测诸如循环之类的代码构造。
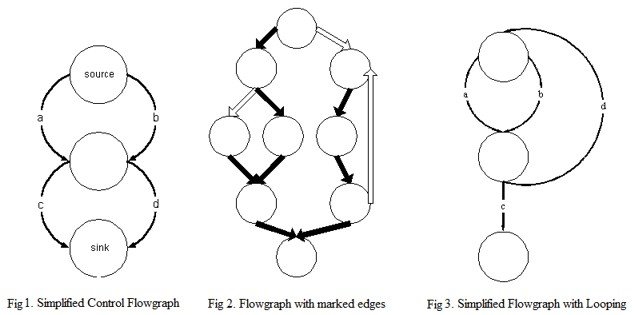
控制流程图的示例。
我们最感兴趣的控制流程图的方面是控制关系 :
- 如果到
N所有路径都通过D则称节点D支配另一个节点N所有节点都占主导地位。 如果D和N是不同的节点,则说D严格支配N - 如果
D严格支配N并没有严格的主宰任何其他节点是严格支配N,然后D可立即主宰说N。 - 支配者树是节点树,其中每个节点的子节点是其立即支配的节点。
-
D的支配性边界是所有节点N的集合,以使D支配N的直接前辈,但不严格支配N换句话说,这是D的优势结束的节点集。
基本循环和控制流程
考虑以下Java方法:
public static void fn(int n) {
for (int i = 0; i < n; ++i) {
System.out.println(i);
}
}…及其拆卸:
0: iconst_0
1: istore_1
2: iload_1
3: iload_0
4: if_icmpge 20
7: getstatic #2 // System.out:PrintStream
10: iload_1
11: invokevirtual #3 // PrintStream.println:(I)V
14: iinc 1, 1
17: goto 2
20: return让我们应用上面讨论的内容,首先将其引入堆栈变量,然后执行复制传播,以将其转换为更具可读性的形式。
| 字节码 | 堆栈变量 | 复制后 | |
|---|---|---|---|
| 0 1个 2 3 4 7 10 11 14 17 20 | iconst_0 istore_1 iload_1 iload_0 if_icmpge 20 静态#2 iload_1 invokevirtual#3 1号,1号 转到2 返回 | s0 = 0 v1 = s0 s2 = v1 s3 = v0 如果(s2> = s3)转到20 s4 = System.out s5 = v1 s4.println(s5) v1 = v1 + 1 转到2 返回 | 如果(v1> = v0)转到20,则v1 = 0 System.out.println(v1) |
注意在#4处的条件分支和在#17处的goto如何创建逻辑循环。 通过查看控制流程图,我们可以更容易地看到这一点:
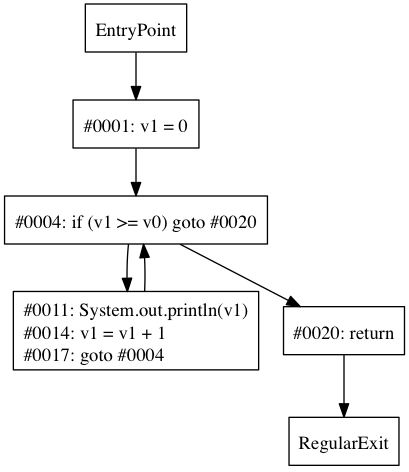
从图中可以明显看出,我们有一个整齐的循环,其边缘从goto到条件分支。 在这种情况下,条件分支称为循环标头 ,可以将其定义为具有形成回路的后沿的支配器。 循环头控制着循环体内的所有节点。
我们可以通过寻找形成循环的后边缘来确定条件是否为循环头,但是我们该怎么做呢? 一个简单的解决方案是测试条件节点是否在其自己的优势边界中。 一旦知道了循环头,就必须找出要拉入循环主体的节点。 我们可以通过查找由标头控制的所有节点来做到这一点。 在伪代码中,我们的算法如下所示:
findDominatedNodes(header)
q := new Queue()
r := new Set()
q.enqueue(header)
while (not q.empty())
n := q.dequeue()
if (header.dominates(n))
r.add(n)
for (s in n.successors())
q.enqueue(n)
return r一旦弄清了循环体,就可以将代码转换成循环。 请记住,我们的循环头可能是一个条件跳出循环,在这种情况下,我们需要否定的条件。
v1 = 0
while (v1 < v0) {
System.out.println(v1)
v1 = v1 + 1
}
return 瞧,我们有一个简单的前提条件循环! 大多数循环(包括while , for和for-each )都编译为相同的基本模式,我们将其视为简单的while循环。 无法确定程序员最初编写的是哪种循环,但是for和for-each遵循我们可以寻找的非常具体的模式。 我们不会详细介绍,但是如果您查看上面的while循环,则可以看到原始的for循环的初始值设定项( v1 = 0 )在循环之前,并已插入其迭代器( v1 = v1 + 1 )。在循环主体的末尾。 我们将把它作为一种练习,思考一下何时以及如何将while循环转换for或for-each 。 考虑一下我们可能如何调整逻辑以检测条件后 ( do/while )循环也很有趣。
我们可以应用类似的技术来反编译if/else语句。 字节码模式非常简单:
begin:
iftrue(!condition) goto #else
// `if` block begins here
...
goto #end
else:
// `else` block begins here
...
end:
// end of `if/else` 在这里,我们使用iftrue作为表示任何条件分支的伪指令:测试条件,如果条件通过,则分支; 否则,请继续。 我们知道if块从条件之后的指令开始, else块从条件的跳转目标开始。 查找那些块的内容就像查找由那些起始节点所控制的节点一样简单,我们可以使用与上述相同的算法来完成。
现在,我们已经介绍了基本的控制流机制,尽管还有其他一些机制(例如,异常处理程序和子例程),但是它们不在本文的介绍范围之内。
结语
编写反编译器绝非易事,而且经验很容易转化为一本书的材料价值,甚至可能是一系列书籍! 显然,我们无法在单个博客文章中介绍所有内容,并且如果我们尝试过,您可能不想阅读它。 我们希望通过接触最常见的结构(逻辑运算符,条件和基本控制流程),使您对反编译器开发领域有个有趣的了解。
Lee Benfield是CFR Java反编译器的作者。
Mike Strobel是Procyon (一个Java反编译器和元编程框架)的作者。
现在去写你自己的! :)
翻译自: https://www.javacodegeeks.com/2013/12/anatomy-of-a-java-decompiler.html
java编译器分析















 3300
3300

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









